
Сегодня компании все чаще обращаются к технологиям распознавания речи для улучшения обслуживания клиентов, автоматизации рабочих процессов и анализа данных. При наличии на рынке множества решений выбор правильной системы стал непростой задачей. Предприятия ищут баланс между точностью, скоростью, интеграцией с существующими процессами и безопасностью данных.
Однако сравнение систем распознавания речи — это не только анализ показателей точности. Важно учитывать особенности каждой системы в контексте реального использования. Проблемы могут возникать из-за различий в методологиях тестирования и несоответствий между результатами тестов и реальными условиями эксплуатации. В этой статье мы подробно рассмотрим, как Lingvanex решает эти задачи, предлагая надежное и эффективное решение для бизнеса.

Проблемы современных методологий при сравнении систем распознавания речи
Выбор системы распознавания речи — это не простая задача, во многом из-за недостатков в методах тестирования этих систем. Современные подходы к сравнению систем распознавания речи сталкиваются с рядом проблем, которые могут исказить результаты и усложнить объективную оценку. Вот основные проблемы, возникающие при таких сравнениях:
1. Ограниченные тестовые наборы данных
Системы распознавания речи часто тестируются на заранее подготовленных и ограниченных наборах данных. Эти наборы могут не отражать реальные условия использования, такие как различные акценты, диалекты, шум и нестандартные речевые конструкции. Это может привести к завышенным результатам тестов, которые не представляют реальную производительность системы в реальных условиях.
2. Чрезмерная зависимость от показателя ошибки слов (WER)
В большинстве случаев системы оцениваются по показателю ошибки слов (WER), который измеряет процент неправильно распознанных слов. Однако этот показатель не всегда является достаточным для всесторонней оценки системы. Например, небольшие ошибки в отдельных словах могут не сильно повлиять на общее понимание, но система с низким WER может совершать ошибки в критически важных словах, что приведет к недоразумениям.
3. Отсутствие учета контекста
Многие системы распознавания речи рассматривают речь как набор независимых слов, не принимая во внимание контекст. Однако контекст может значительно повлиять на правильное распознавание слов, особенно когда слова звучат одинаково, но имеют разные значения в зависимости от соседних слов и предложений.
4. Недостаточное внимание к акцентам и диалектам
Многие методологии тестирования не уделяют достаточного внимания разнообразию акцентов и диалектов. Это приводит к созданию систем, которые хорошо работают с "стандартным" языком, но показывают низкую точность при взаимодействии с людьми, говорящими на диалектах или с сильным акцентом.
5. Недооценка пользовательского опыта
Системы часто оцениваются только по техническим параметрам, таким как точность распознавания и скорость, но удобство использования для конечного пользователя остается вне внимания. Например, система может быть точной, но требовать слишком много усилий для обучения или настройки.
6. Фоновый шум и записи низкого качества
Реальные условия редко бывают тихими. Фоновый шум, будь то в офисах, общественных местах или от работы оборудования, может мешать точному распознаванию. Кроме того, не все записи отличаются 100-процентным качеством, и системы часто сталкиваются с трудностями при работе с аудио низкого качества, таким как телефонные звонки или голосовые сообщения.
7. Скорость речи
Люди говорят с разной скоростью, и системы часто испытывают трудности в понимании как очень медленной, так и очень быстрой речи. Это может привести к потере важной информации или ошибкам при транскрибировании.
8. Речевая многозадачность
В реальных условиях, например, на совещаниях или деловых звонках, несколько людей часто говорят одновременно. Система должна уметь различать голоса и точно распознавать речь каждого участника.
Методологии тестирования для оценки систем распознавания речи нуждаются в улучшении, чтобы учитывать реальные условия эксплуатации и более широкий круг сценариев. Lingvanex, понимает эти ограничения и разрабатывает решения, которые адаптируются к реальным рабочим условиям бизнеса. Мы не полагаемся только на лабораторные тесты: наша система тестируется в условиях, близких к реальному использованию, что позволяет нам своевременно выявлять и устранять потенциальные проблемы.
Как Lingvanex решает эти проблемы
Чтобы обеспечить высокую точность распознавания речи в реальных условиях, Lingvanex использует несколько уникальных технических подходов:
- Адаптация к акцентам и диалектам
Lingvanex использует глубокие нейронные сети, обученные на больших наборах данных с различными акцентами и диалектами. Наши модели обучаются с использованием технологий трансферного обучения, что позволяет эффективно адаптировать системы к новым акцентам, требуя минимальных дополнительных данных для тонкой настройки. Мы также предлагаем использование специализированных моделей для определенных отраслей или регионов, что повышает точность для целевой аудитории.
Благодаря способности системы адаптироваться к конкретным акцентам и диалектам, компании могут уверенно работать с международной аудиторией, предоставляя высококачественные голосовые сервисы и улучшая взаимодействие с клиентами, что особенно важно для компаний, ведущих бизнес в мировом масштабе.
- Подавление шума
Программное обеспечение Lingvanex интегрируется с технологиями активного подавления шума для фильтрации фона. Это позволяет системе эффективно устранять шум при сохранении ясности речи. Алгоритмы подавления шума применяются на этапе предварительной обработки аудиосигнала, что делает систему особенно полезной в колл-центрах и офисах с открытой планировкой.
Компании, работающие в шумных офисах, колл-центрах или на производственных площадках, могут предоставить клиентам точные и четкие транскрипции разговоров, улучшая качество обслуживания и повышая удовлетворенность клиентов.
- Оптимизация аудио низкого качества
Системы Lingvanex используют специальные алгоритмы для обработки аудио данных с низкой частотой дискретизации, таких как телефонные звонки. Это особенно важно для бизнесов, работающих с телефонной связью и голосовыми сообщениями.
Компании, которые сильно зависят от телефонных линий или голосовых сообщений, могут получать точные транскрипции даже с записей низкого качества. Это улучшает анализ данных, ускоряет обработку запросов клиентов и снижает количество ошибок.
- Адаптация к скорости речи
Lingvanex использует нейронные сети для обработки речи с различной скоростью. Это обеспечивает стабильную работу системы, независимо от темпа речи, что критически важно для автоматизации транскрипций и анализа больших объемов голосовых данных.
Компании могут уверенно использовать систему для автоматической транскрипции звонков или встреч, независимо от того, как быстро или медленно говорит собеседник. Это сокращает время, затрачиваемое на ручную обработку данных, и повышает точность транскрипции.
- Дифференциация говорящих
Системы Lingvanex могут идентифицировать и атрибутировать голос каждого участника разговора. Для разделения и идентификации говорящих в реальном времени используются алгоритмы диаризации говорящих.
Это решение позволяет компаниям, работающим с записями, где несколько говорящих (например, совещания или конференции), получать точные транскрипции, упрощая анализ данных, улучшая коммуникацию и экономя время на ручной транскрипции.
Lingvanex vs. Whisper: Сравнительный анализ
Когда речь идет о системах распознавания речи, одним из ключевых критериев оценки является производительность на основе объективных метрик. Чтобы дать более четкое представление, мы провели сравнительный тест Lingvanex и другой крупной системы, Whisper, используя как стандартные, так и реальные данные.
Ключевые метрики, которые мы оценивали:
- Показатель ошибки слов (WER). Эта метрика отражает процент неправильно распознанных слов. Чем ниже WER, тем точнее система распознает речь. Мы включили эту метрику в оценку, так как она широко используется в отрасли и позволяет сравнивать общую качество различных систем.
- Показатель ошибки символов (CER). Эта метрика измеряет ошибки на уровне символов, а не слов. Она дает более детализированное представление о том, насколько точно система может обработать каждое произнесенное слово. Это важно для сценариев, где каждая буква имеет значение, например, при работе с сложными терминами или именами. Более низкий CER указывает на более точное распознавание речи системой.
- Время обработки аудио. Эта метрика показывает, сколько времени системе требуется для обработки одной минуты аудио. Скорость обработки особенно важна для компаний, работающих с большими объемами данных или в реальном времени, где быстрый отклик системы критичен. Меньшее время обработки — лучшее поведение системы.
Оценка этих метрик помогает не только понять точность системы, но и оценить, как она работает в реальных условиях, где важны не только точность, но и скорость, гибкость и адаптивность.
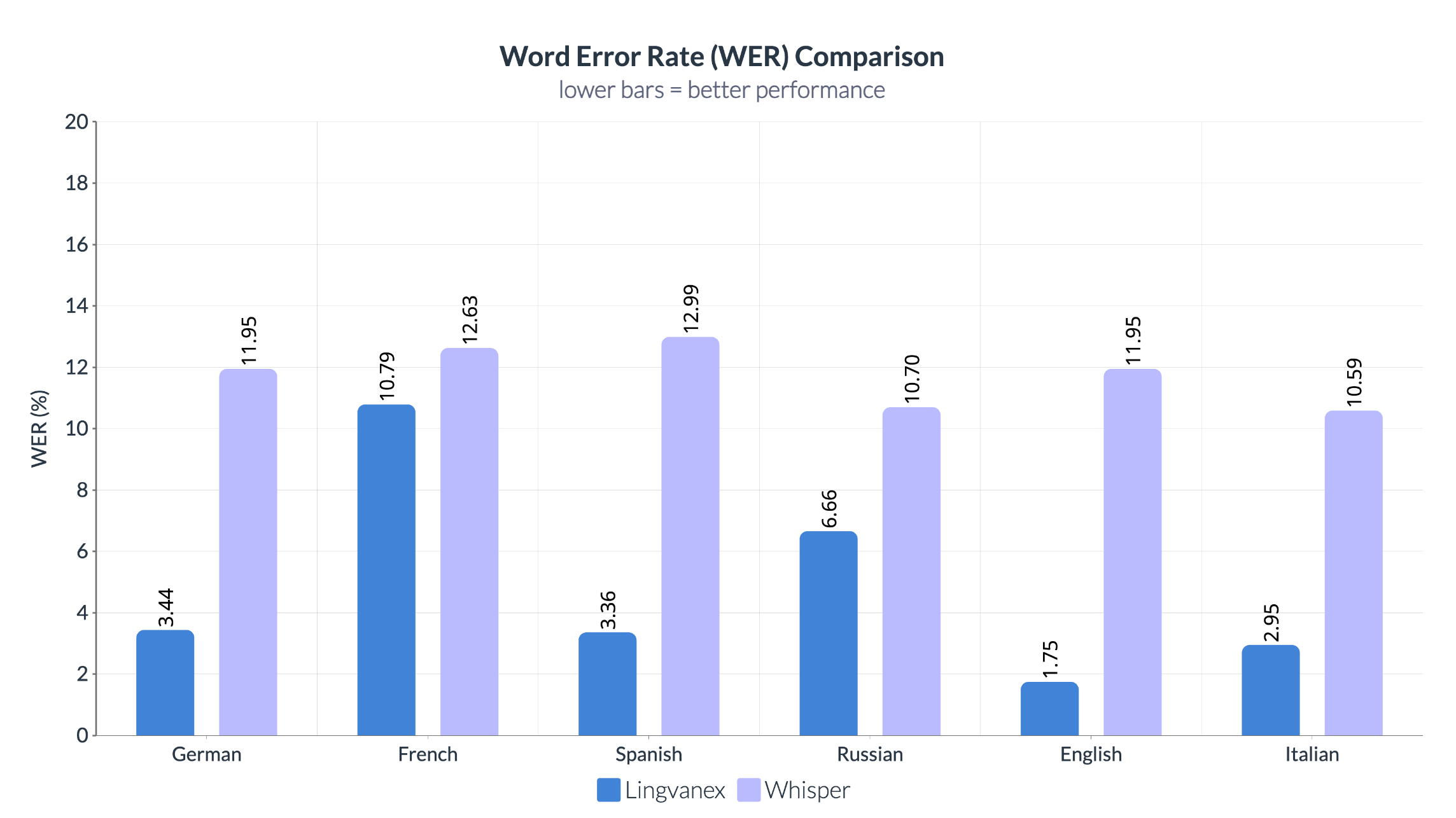
Сравнение показателей WER между Lingvanex и Whisper показывает значительное преимущество системы Lingvanex по всем языкам. Lingvanex стабильно демонстрирует низкие показатели ошибок, особенно в английском языке (1,75%) и немецком (3,44%), что свидетельствует о высокой точности распознавания речи. В то же время Whisper показывает значительно более высокие значения WER по всем языкам, превышая 10% в каждом случае.
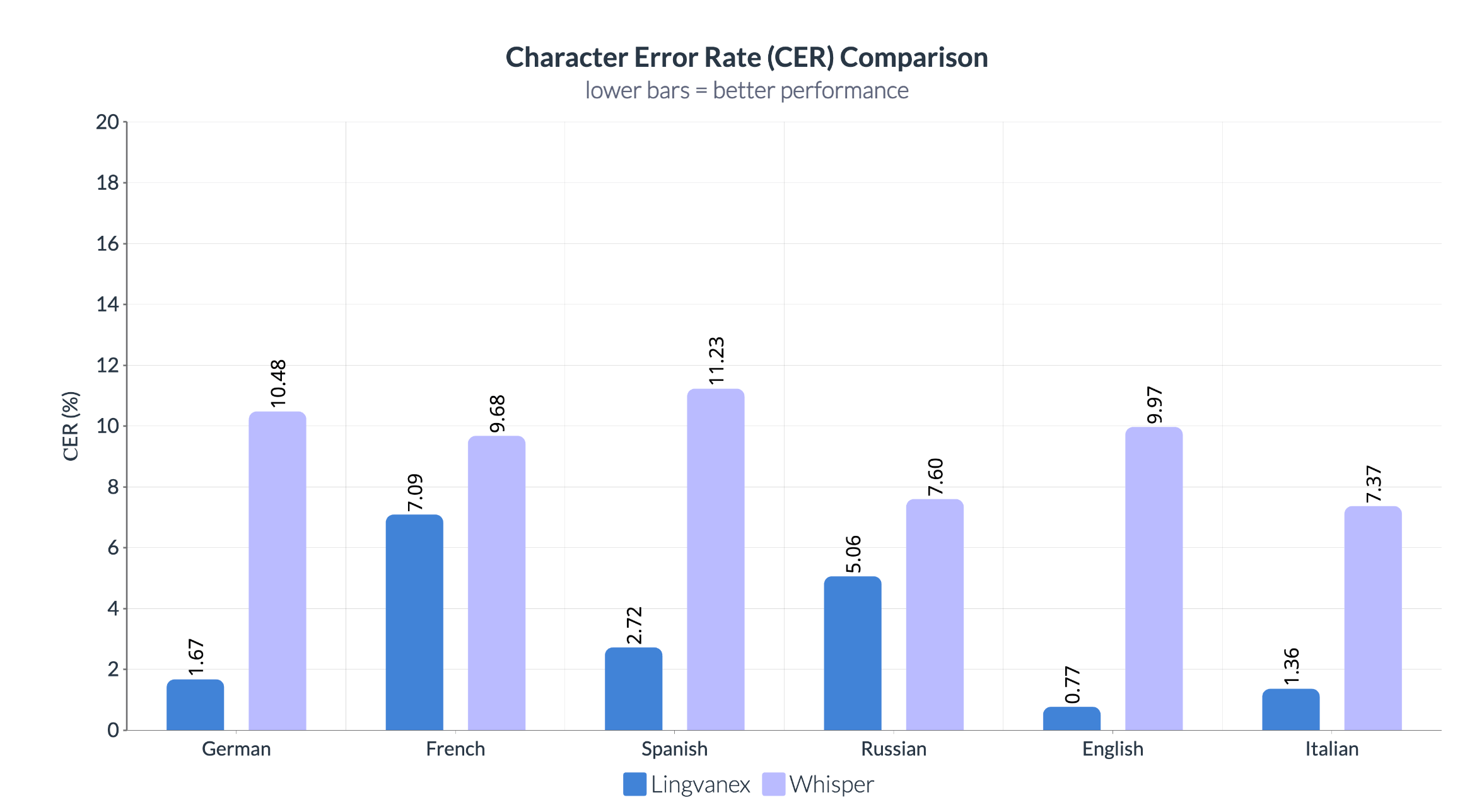
Что касается CER, то Lingvanex также значительно превосходит Whisper. Lingvanex демонстрирует минимальные ошибки на уровне символов, особенно в английском (0,77%) и немецком (1,67%) языках, что подчеркивает внимание системы к деталям и точность. В то время как Whisper показывает высокие значения CER, что указывает на менее точную обработку символов при распознавании речи.
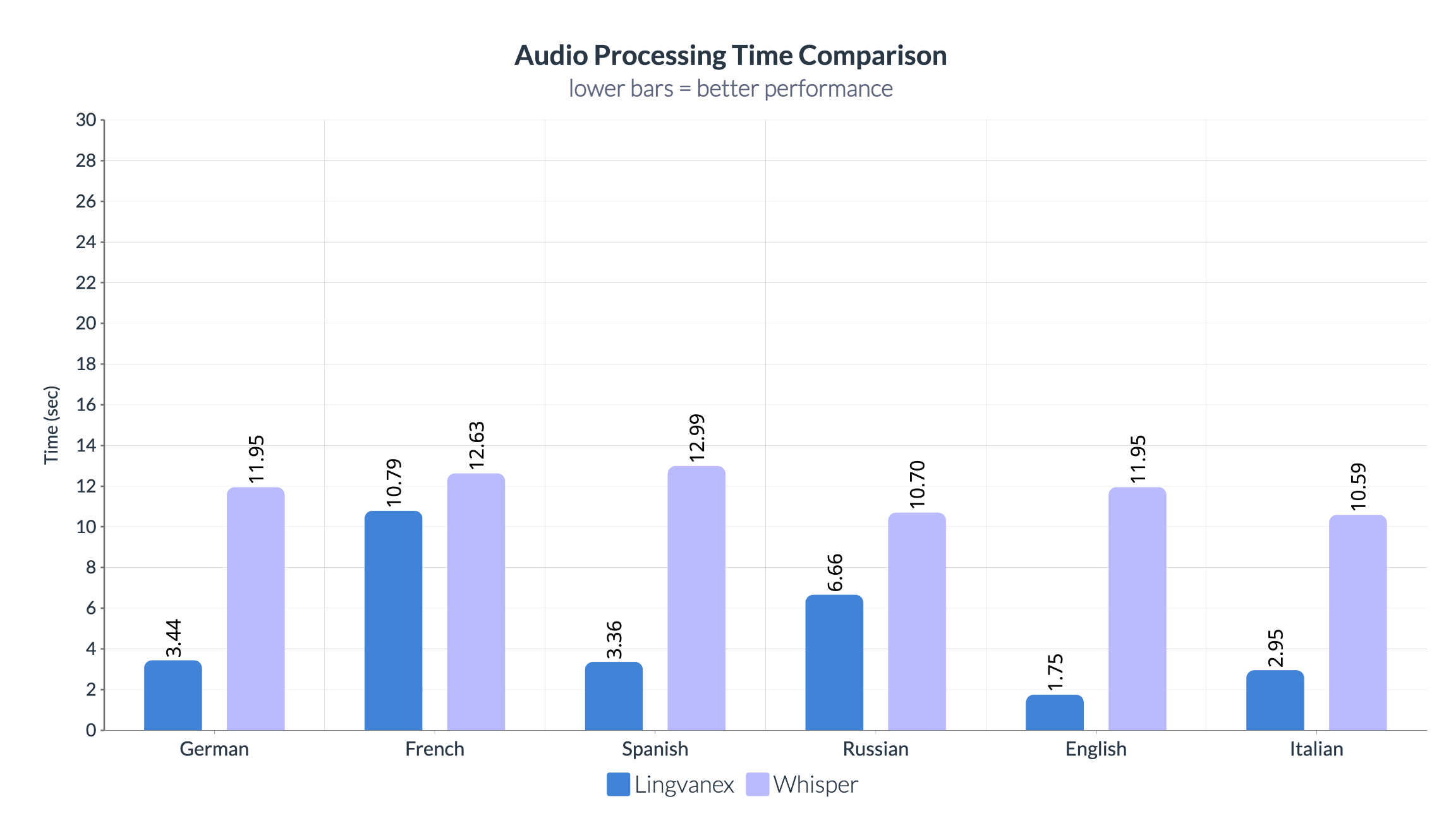
Сравнение времени обработки аудио между Lingvanex и Whisper выявляет еще одно значительное преимущество Lingvanex. Lingvanex обрабатывает одну минуту аудио намного быстрее, чем Whisper. Например, для распознавания одной минуты аудио на английском языке Lingvanex требуется всего 3,44 секунды, в то время как Whisper обрабатывает ту же минуту аудио за 16,33 секунды.
На основе всех трех сравнений (WER, CER и времени обработки) можно сделать вывод, что Lingvanex превосходит Whisper по всем ключевым параметрам. Lingvanex обеспечивает более точное распознавание речи как на уровне слов, так и на уровне символов, а также обрабатывает аудиоданные значительно быстрее. Эти преимущества делают Lingvanex предпочтительным выбором для компаний, стремящихся оптимизировать свои голосовые сервисы, минимизировать ошибки и обеспечить высокую производительность при обработке аудиофайлов в реальном времени.
Lingvanex: решение ваших задач распознавания речи
На основе сравнительных тестов и реальных отзывов клиентов можно выделить несколько ключевых преимуществ программного обеспечения Lingvanex для распознавания речи:
- Гибкость и настройка. Мы предлагаем уникальные возможности для адаптации системы под конкретные потребности бизнеса, включая настройку модели для терминологии, специфичной для отрасли, и требования безопасности.
- Снижение времени обработки данных. Lingvanex значительно ускоряет обработку аудио. Одна минута аудио обрабатывается всего за 3,44 секунды, что в разы быстрее, чем у конкурентов.
- Повышение продуктивности сотрудников. Автоматизация процессов распознавания речи с помощью Lingvanex снижает нагрузку на сотрудников, которые ранее занимались ручной транскрипцией.
- Улучшение клиентского опыта. Lingvanex обеспечивает качественное взаимодействие с клиентами по всему миру благодаря точности распознавания акцентов и диалектов, а также способности обрабатывать записи с несколькими говорящими, даже в шумной среде.
- Снижение затрат на обработку данных. Высокая точность и скорость работы Lingvanex сокращают расходы на аутсорсинг транскрипции и другие ручные процессы, связанные с обработкой голосовых данных.
- Бесшовная интеграция в бизнес-процессы. Lingvanex легко интегрируется с существующими системами через API и SDK, что позволяет быстро внедрить систему без необходимости дополнительной разработки или адаптации.
- Поддержка различных форматов данных. Lingvanex работает с широким диапазоном аудиоформатов, от стандартных WAV и MP3 до более специализированных OGG и FLV.
- Безопасность данных. Lingvanex предлагает локальные решения для компаний, работающих с конфиденциальной информацией, обеспечивая полное соответствие требованиям защиты данных.
Заключение
При выборе системы распознавания речи компаниям необходимо учитывать множество факторов — от точности и устойчивости к шуму до поддержки множества языков и гибкости в интеграции. Lingvanex является лидером на рынке распознавания речи, так как предлагает комплексные решения, которые не только соответствуют самым высоким стандартам, но и легко адаптируются под уникальные потребности каждого бизнеса.
Компании, которые уже внедрили Lingvanex, смогли решить задачи, которые не под силу другим системам — будь то работа с акцентами, шумом или сложной терминологией. Мы не предлагаем один инструмент для решения любых задач, мы создаем систему, которая учитывает особенности каждого клиента, предоставляя результаты, на которые можно полагаться.
Lingvanex — это не просто технология, это инструмент, который помогает вашему бизнесу работать лучше, быстрее и точнее. Если ваша цель — улучшить ключевые процессы работы с голосовыми данными и увидеть реальные результаты, а не теоретические обещания, Lingvanex станет вашим надежным партнером.


