
В этой статье мы углубимся в архитектуру и операционные механизмы декодера в моделях трансформаторов, которые являются неотъемлемой частью таких задач, как перевод языка и генерация текста. Мы опишем последовательную обра ботку входных матриц, начиная с внедрения токенов, масштабируемых по количеству единиц, через применение исключения для регуляризации и создание future and memory масок. Эти шаги гарантируют, что декодер может эффективно управлять конт екстом и зависимостями внутри последовательностей. Мы также рассмотрим ряд преобразований, которые происходят в каждом слое декодера, включая процессы self-attention и cross-attention. Это включает в себя вычисление queries, keys и values, а также применение нормализации и dropout на различных этапах.
Наконец, мы обсудим, как выходные данные декодера преобразуются в логиты, готовые к генерации прогнозов, и выделим последовательность вызовов функций и классов, которые организуют эти сложные операции. С помощью данной статьи мы стремимся обеспечить всестороннее понимание роли декодера в архитектурах трансформаторов.
Декодер
В ДЕКОДЕР ВЕКТОРНОЕ ПРЕДЛОЖЕНИЕ ТОКЕНОВ целевого ЯЗЫКА:
- Сгенерированная матрица входов с использованием функции tf.nn.embedding_lookup умножается на квадратный корень из num_units (в нашем примере num_units=4) → inputs = inputs *. (Изображение 1 - num_units)

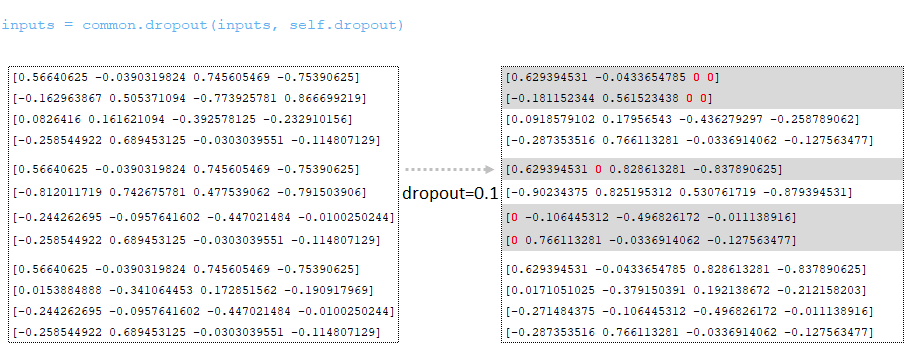
- Применяется dropout (параметр dropout из файла конфигурации). (Изображение 2 - dropout )
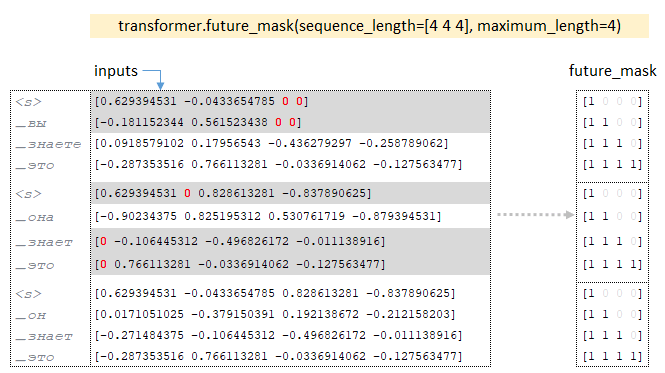
- По размерности батчей матрицы входов строится тензор future_mask с помощью функции future_mask. При обучении декодера будущие токены последовательности будут скрыты, декодер имеет доступ только к текущему токену и предыдущим токенам. (Изображение 3 - future_mask)
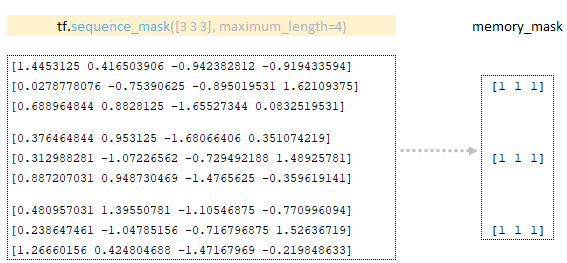
- Тензор memory_mask формируется с использованием матрицы, полученной в кодере с помощью функции tf.sequence_mask. (Изображение 4 - memory_mask )
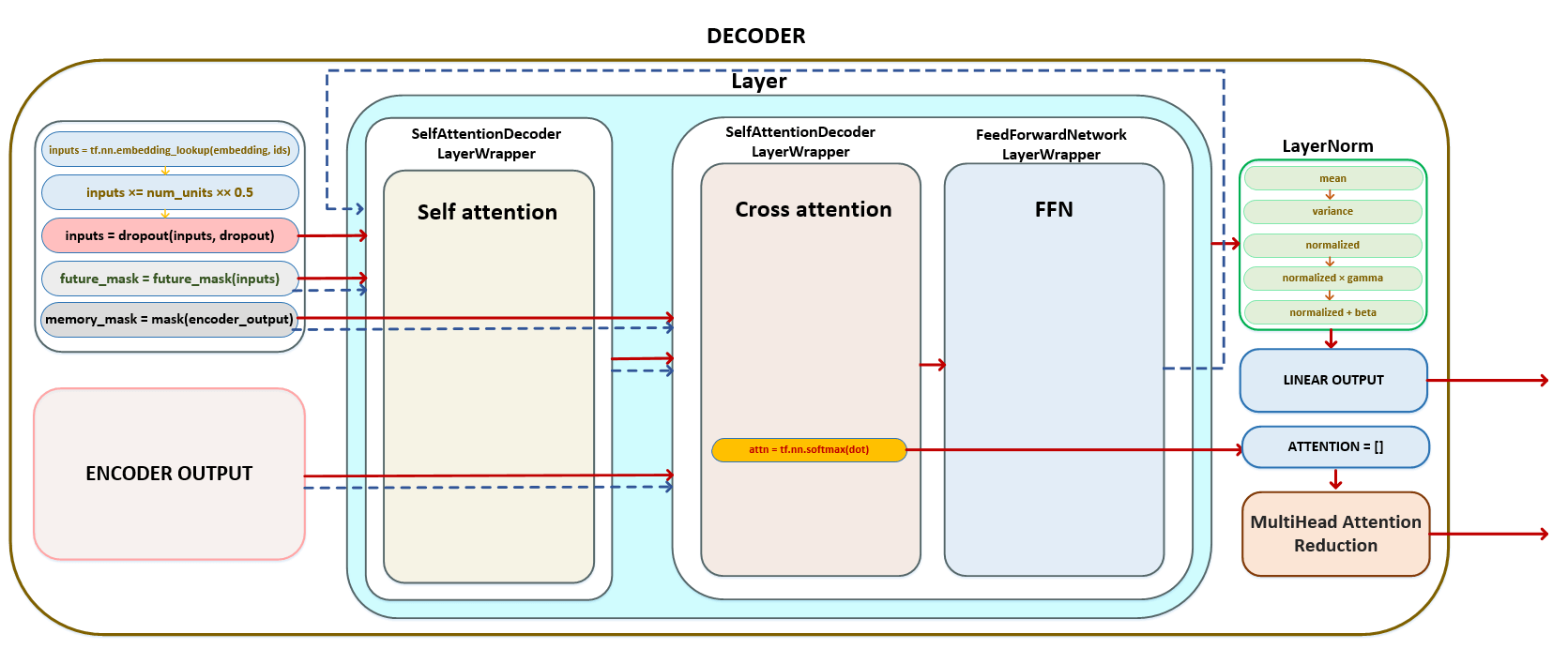
- В цикле для каждого слоя, равного числу параметра Layers, в слой передаются матрица inputs, тензор future_mask, тензор memory_mask и полученная после кодера матрица encoder_outputs, результат, возвращаемый layer - inputs, передается в следующий слой. Например, если у нас есть 6 слоев, результат первого слоя будет входным результатом для второго слоя и т. д. Из каждого слоя матрица внимания, сформированная в слое cross_attention (или encoder-decoder attention ), возвращается и сохраняется в списке. (Изображение 5 — матрица внимания)

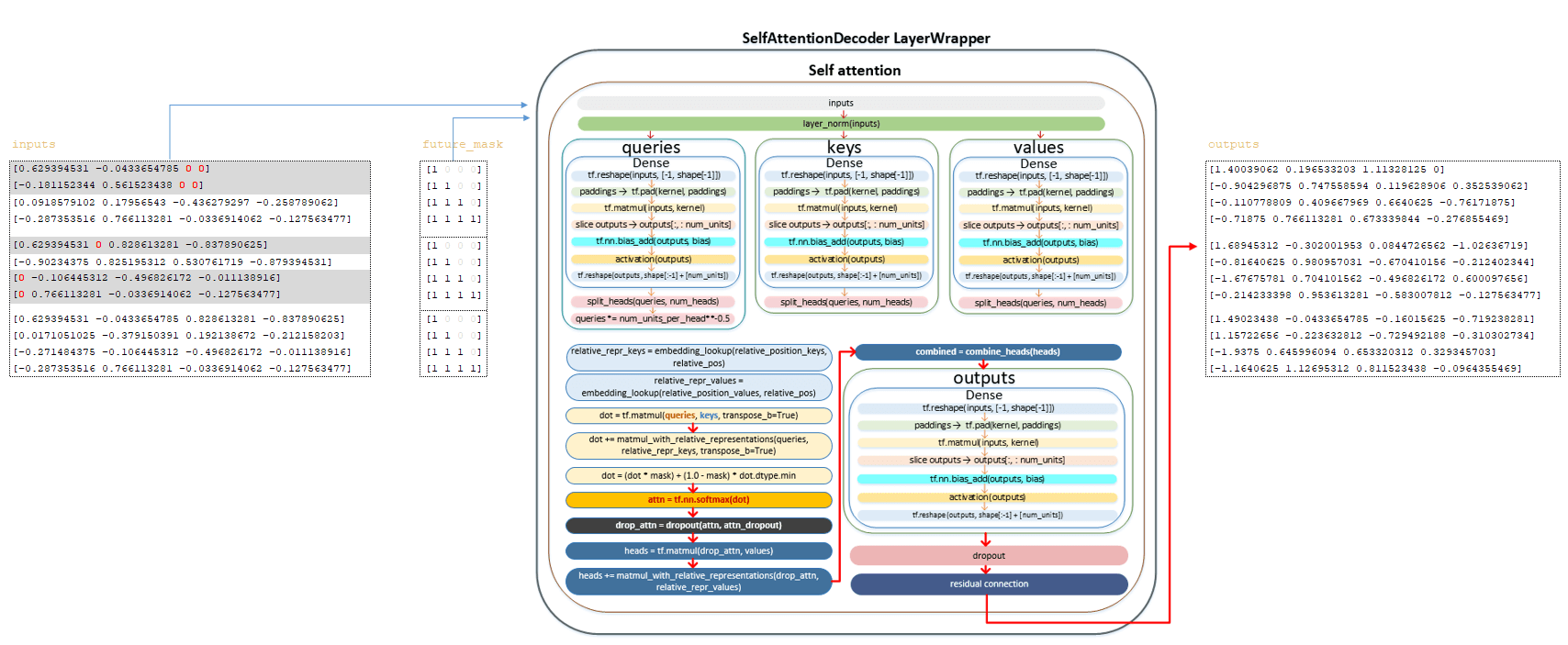
В каждом слое происходят преобразования, описанные ниже. Inputs матрица и матрица future_mask преобразуются с использованием слоя self-attention. Полный механизм матричных преобразований описан в разделе кодировщика. Здесь мы перечислим основные шаги:
━ 1) inputs матрица проходит через слой нормализации;
━ 2) вычисляется queries матрица и делится на количество голов;
━ 3) матрица queries, деленная на количество голов, делится на квадратный корень из num_units_per_head ;
━ 4) вычисляются keys матрица и делится на количество голов;
━ 5) вычисляются values матрица и делится на количество голов;
━ 6) вычисляются матрицы relation_repr_keys и relation_repr_values ;
━ 7) получается скалярное произведение матриц requests и keys ;
━ 8) матрица запросов умножается на матрицу relation_repr_key;
━ 9) матрица matmul_with_relative_representations добавляется к скалярному произведению матриц;
━ 10) преобразование с матрицей future_mask ;
━ 11) применяется функция активации softmax ;
━ 12) применяется dropout (параметр awareness_dropout из файла конфигурации);
━ 13) умножение на values матрицу для формирования heads матрицы;
━ 14) умножение на матрицу relation_repr_values ;
━ 15) сложение heads матрицы с матрицей matmul_with_relative_representations ;
━ 16) объединение heads ( heads матрица) в общую матрицу;
━ 17) линейное преобразование;
━ 18) применяется dropout (параметр dropout из файла конфигурации);
━ 19) применяется residual connection (механизм остаточной связи).
После вышеуказанных преобразований получаем матрицу выходов. (Изображение 6 - outputs матрица)
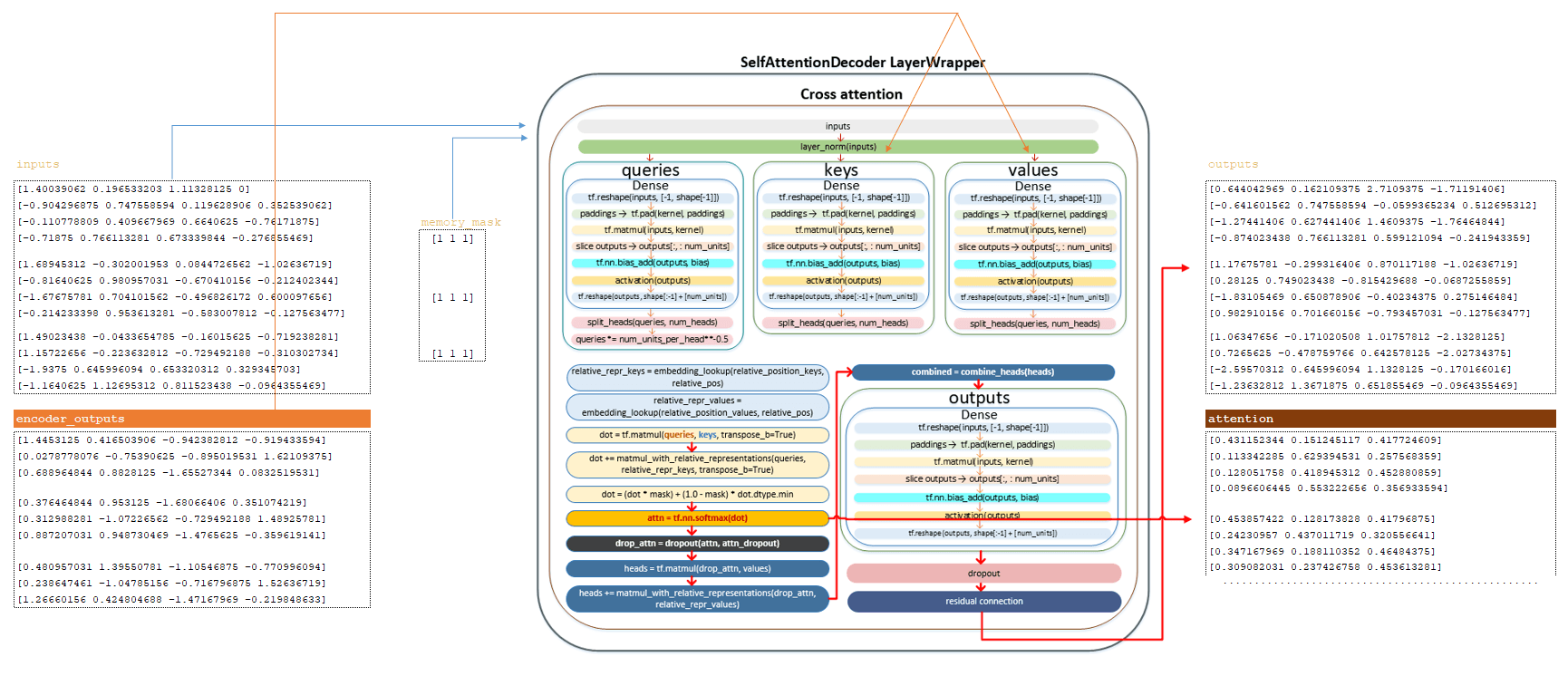
Матрица после слоя self awareness, матрица memory_mask и матрица, полученная в encoder_outputs, подаются на вход слоя cross awareness. Полный механизм матричных преобразований описан в разделе encoder. Здесь мы перечислим основные шаги:
━ 1) матрица inputs пропускается через слой нормализации;
━ 2) вычисляется queries матрица и делится на количество голов;
━ 3) матрица queries, деленная на количество голов, делится на квадратный корень из num_units_per_head ;
━ 4) матрица keys вычисляется из матрицы encoder и делится на количество голов;
━ 5) матрица values вычисляется с использованием матрицы encoder и делится на количество голов;
━ 6) вычисляется матрица relation_repr_keys и relation_repr_values ;
━ 7) получается скалярное произведение матриц queries и keys ;
━ 8) матрица queries умножается на матрицу relation_repr_key ;
━ 9) матрица matmul_with_relative_representations добавляется к скалярному произведению матриц;
━ 10) преобразование с матрицей memory_mask ;
━ 11) применяется функция активации softmax, получаем матрицу attention, которая возвращается из этого слоя;
━ 12) применяется dropout (параметр awareness_dropout из файла конфигурации);
━ 13) умножение на матрицу values для формирования матрицы heads ;
━ 14) умножение на матрицу relation_repr_values ;
━ 15) сложение матрицы heads с матрицей matmul_with_relative_representations ;
━ 16) объединение heads ( heads матрица) в общую матрицу;
━ 17) линейное преобразование;
━ 18) применено dropout (параметр dropout из файла конфигурации);
━ 19) применен механизм residual connection ( остаточного соединения).
После вышеуказанных преобразований получаем матрицу outputs и attention. (Изображение 7 - матрица outputs и attention)
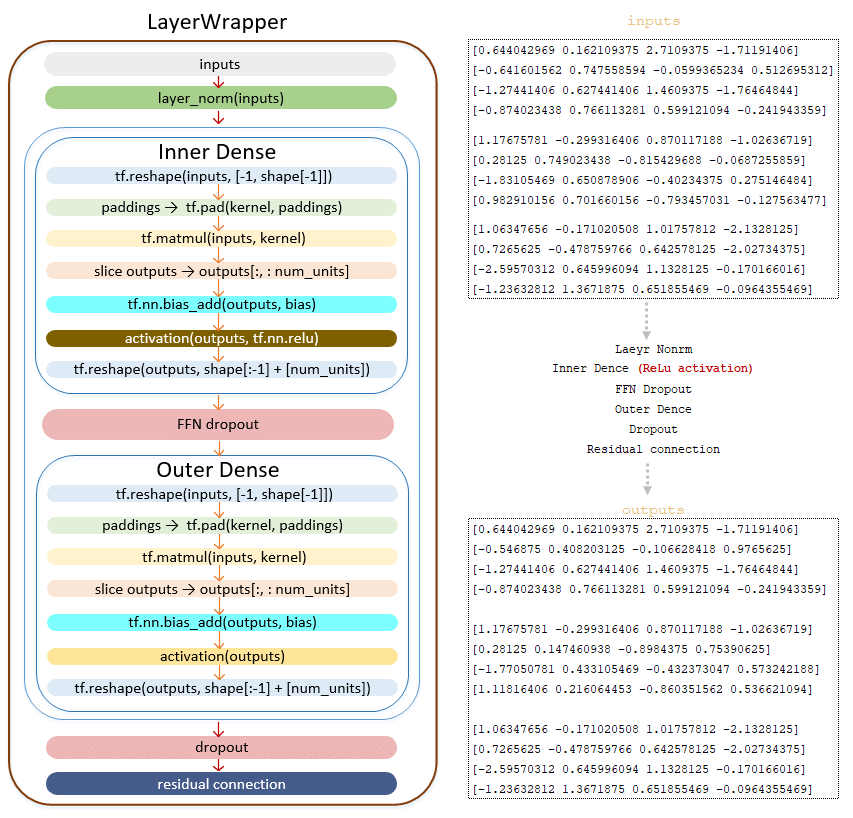
Матрица outputs передается в Feed Forward Network (с еть прямого распространения ):
━ 1) применяется слой нормализации LayerNorm () ;
━ 2) линейное преобразование класса Dense(). Линейное преобразование с функцией активации ReLU tf.nn.relu;
━ 3) применяется dropout (параметр ffn_dropout из файла конфигурации);
━ 4) линейное преобразование класса Dense() ;
━ 5) применяется dropout (параметр dropout из файла конфигурации);
━ 6) применяется механизм остаточного соединения.
(Изображение 8 - outputs матрица)
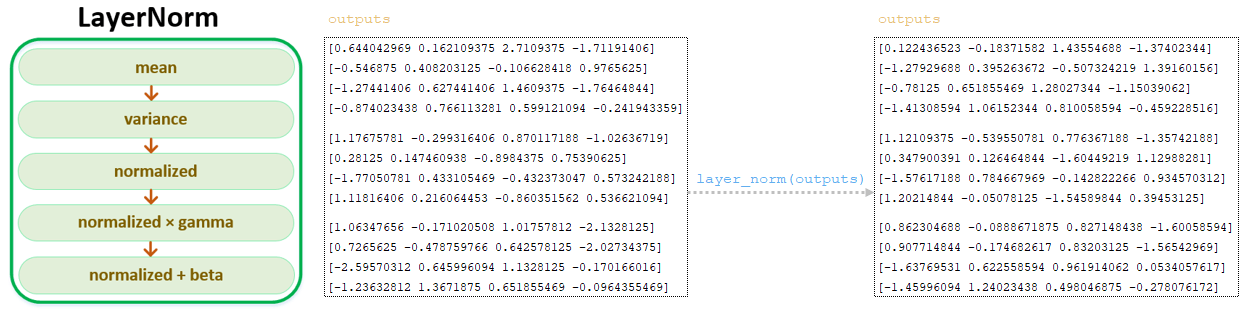
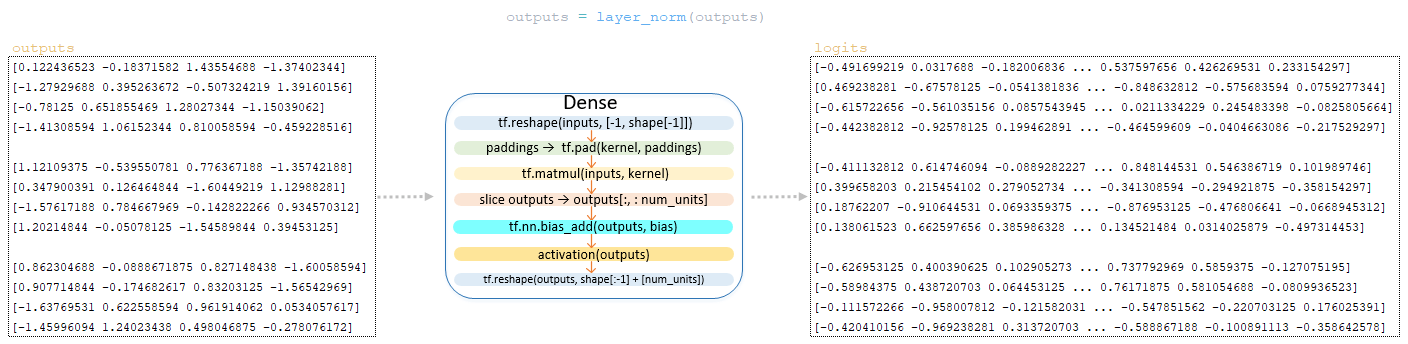
После преобразования матрицы outputs с помощью Feed Forward Network, полученная матрица outputs проходит слой нормализации LayerNorm (). (Изображение 9 - LayerNorm)
Массив матриц attention из каждого слоя преобразуется с использованием указанной стратегии обработки. Стратегией по умолчанию является FIRST_HEAD_LAST_LAYER, т. е. будет взята матрица attention, полученная на последнем слое, и из этой матрицы будет взята первая голова. (Изображение 10 - MultiHeadAttentionReduction )

Матрица outputs после слоя нормализации преобразуется выходным линейным слоем декодера, размерность которого составляет vocab_size x num_units (в нашем примере 26 x 4 ), для формирования логит-матрицы. Это преобразование в декодере является заключительной операцией. (Изображение 11 - логит-матрица)
Таким образом, после преобразований в декодере токенов целевого языка на выходе декодера мы имеем две матрицы - матрицу logits и матрицу значений attention из последнего слоя cross attention. Схематически полный цикл преобразований в декодере можно представить следующим образом. (Рисунок 12 - полный цикл преобразований в декодере)
Декодер. Упрощенная последовательность вызова:
├──def call() | class Model(tf.keras.layers.Layer) модуль model.py
├──def call() | class SequenceToSequence(model.SequenceGenerator) модуль sequence_to_sequence.py
├── def _decode_target() | class SequenceToSequence(model.SequenceGenerator) модуль sequence_to_sequence.py
├──def call() | class WordEmbedder(TextInputter) модуль text_inputter.py
├──def call() | class Decoder(tf.keras.layers.Layer) модуль decoder.py
├──def forward() | class SelfAttentionDecoder(decoder.Decoder) модуль self_attention_decoder.py
├──def _run() | class SelfAttentionDecoder(decoder.Decoder) модуль self_attention_decoder.py
├──def call() | class SelfAttentionDecoderLayer(tf.keras.layers.Layer) модуль layers/transformer.py
├──def call() | class LayerWrapper(tf.keras.layers.Layer) модуль layers /common.py
├──def call() | class MultiHeadAttention(tf.keras.layers.Layer) модуль layers/transformer.py
├──def call() | class Dense(tf.keras.layers.Dense) модуль layers /common.py
├──def call() | class LayerWrapper(tf.keras.layers.Layer) модуль layers /common.py
├──def call() | class MultiHeadAttention(tf.keras.layers.Layer) модуль layers/transformer.py
├──def call() | class Dense(tf.keras.layers.Dense) модуль layers /common.py
├──def call() | class LayerWrapper(tf.keras.layers.Layer) модуль layers /common.py
├──def call() | class FeedForwardNetwork(tf.keras.layers.Layer) модуль layers/transformer.py
├──def call() | class LayerNorm(tf.keras.layers.LayerNormalization) модуль layers/common.py
├──def reduce() | class MultiHeadAttentionReduction модуль layers/transformer.py
├──def call() | class Dense(tf.keras.layers.Dense) модуль layers /common.py
Заключение
В заключение, декодер в моделях трансформаторов является жизненно важным компонентом, который эффективно генерирует последовательности целевого языка. С помощью ряда тщательно структурированных слоев он обрабатывает входные вложения, применяет механизмы внимания и производит логиты для окончательных прогнозов. Используя такие методы, как маскирование, нормализация и dropout, декодер обеспечивает надежную производительность при захвате контекстных отношений. Понимание этих процессов дает ценную информацию о том, как модели трансформаторов достигают самых современных результатов в различных задачах обработки естественного языка.


