
Данная статья является продолжением первой части «Механизм инференса обученной модели при генерации последовательности», которая посвящена процессу генерирования вывода в модели генерации обучающей последовательности, иллюстрируя его архитектуру и функциональность на примере фразы «он знает это». В этой части мы рассмотрим оставшиеся три шага механизма генерации вывода.
Разбивая пошаговые операции, связанные с созданием последовательности, мы стремимся обеспечить полное понимание того, как эти модели производят последовательные и контекстуально соответствующие результаты. Это исследование не только поможет понять основные механизмы генерации последовательностей, но и заложит основу для будущих улучшений в разработке и применении моделей.

Шаг 1
По матрице word_ids, полученной на шаге step = 0, мы извлекаем векторные представления токенов из целевой матрицы вложений обученной модели и вместе с матрицей encoder_outputs, продублированной на количество beam_size, подаем на вход декодера. Из декодера мы получаем матрицы logits и attention. (Изображение 1 – матрицы logits и attention )
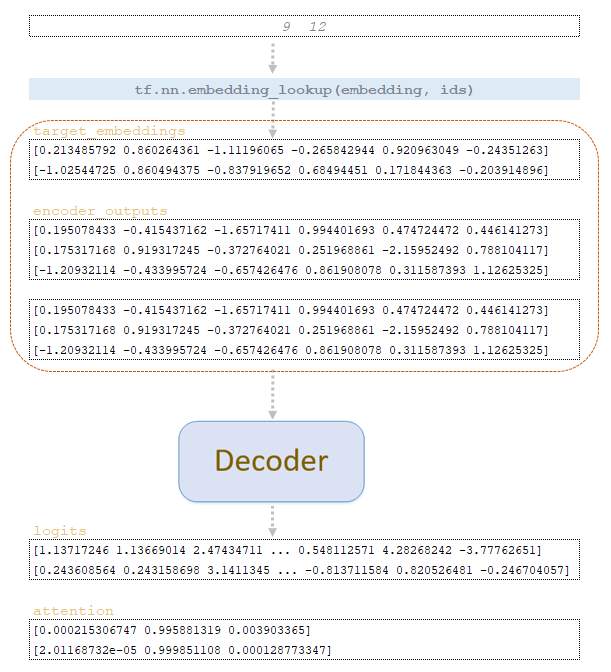
После прохождения вышеописанных операций после шага 1 мы получаем матрицы word_ids, cum_log_probs, finished и словарь extra_vars.
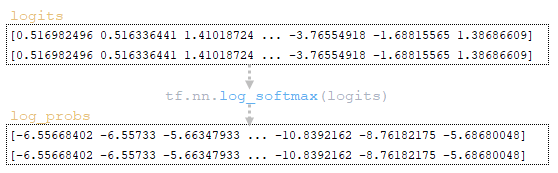
(Изображение 2a — logits и log_probs) (Изображение 2b — total_probs) (Изображение 2c — top_scores и top_ids) (Изображение 2d — матрицы word_ids, cum_log_probs, finished и словарь extra_vars )
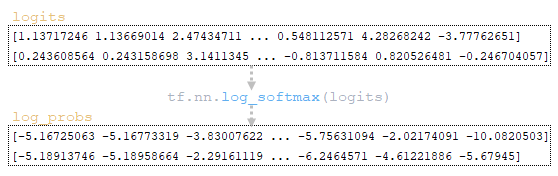

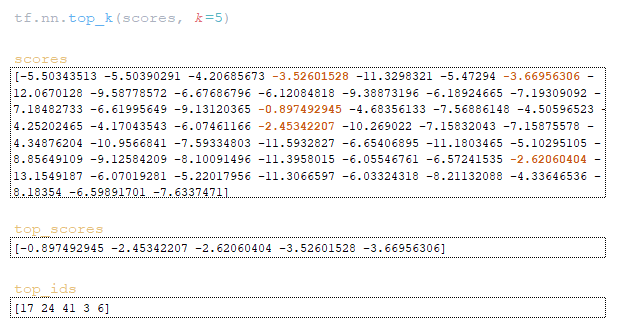

Шаг 2
По матрице word_ids, полученной на шаге step = 1, векторные представления токенов извлекаются из целевой матрицы вложений обученной модели и вместе с матрицей encoder_outputs, продублированной числом beam_size, подаются на вход декодера. Из декодера мы получаем матрицы logits и attention. (Изображение 3 – матрицы logits и attention, шаг 2)

Проходим вышеперечисленные операции и получаем после шага 2 матрицы word_ids, cum_log_probs, finished и словарь extra_vars.
(Изображение 4a — logits и log_probs) (Изображение 4b — total_probs) (Изображение 4c — top_scores и top_ids) (Изображение 4d — матрицы word_ids, cum_log_probs, finished и словарь extra_vars)

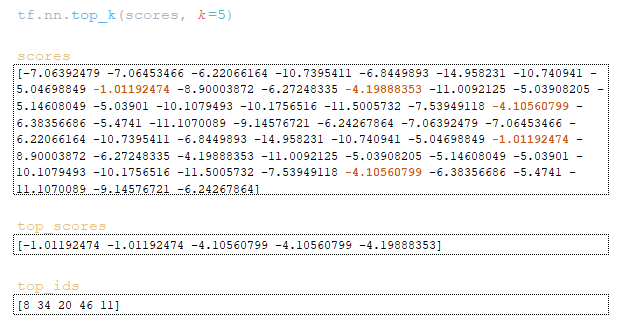

Шаг 3
Используя матрицу word_ids, полученную на шаге шаг = 2, мы извлекаем векторные представления токенов из целевой матрицы вложений обученной модели и вместе с матрицей encoder_outputs, продублированной числом beam_size, подаем ее на вход декодера. Из декодера мы получаем матрицы logits и attention. (Изображение 5 – матрицы logits и attention, шаг 3)
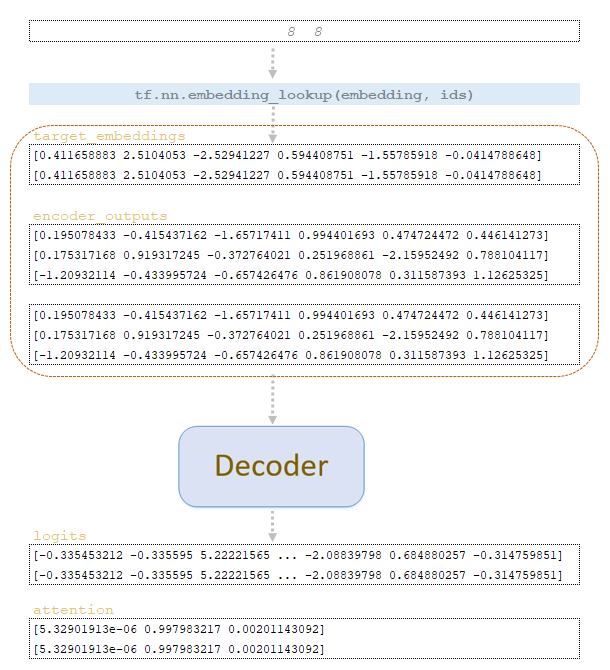
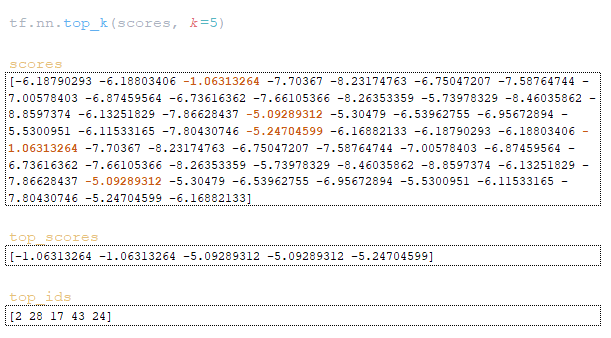
Проходим вышеперечисленные операции и получаем после шага 3 матрицы word_ids, cum_log_probs, finished и словарь extra_vars.
(Изображение 6a — logits и log_probs) (Изображение 6b — total_probs) (Изображение 6c — top_scores и top_ids) (Изображение 6d — матрицы word_ids, cum_log_probs, finished и словарь extra_vars )


На этом этапе цикл прерывается, поскольку декодер сгенерировал токены конца последовательности с id = 2.
Полученные последовательности id-токенов декодируются и получаются гипотезы перевода исходных предложений. Количество гипотез не может быть больше, чем beam_size , т.е. если мы хотим получить 3 альтернативных перевода, нам нужно установить beam_size =3.
Фактически в результате у нас есть 2 гипотезы, 1-я гипотеза будет содержать последовательности наиболее вероятных полученных токенов и несколько распределений. (Изображение 7 — target_tokens )
Заключение
В этой статье мы изучили механизм вывода в обученной модели генерации последовательностей, используя в качестве примера фразу «он это знает». Мы обрисовали архитектуру модели, подробно описав, как токены представляются и обрабатываются посредством кодера и декодера. Подробно обсуждались ключевые компоненты процесса вывода, такие как инициализация параметров, применение лучевого поиска, вычисление логарифмических вероятностей и оценок. Мы выделили пошаговые операции, связанные с созданием последовательности, в том числе преобразование и обновление матриц на каждой итерации.
В конечном итоге этот механизм позволяет модели генерировать последовательности, соответствующие контексту, что в конечном итоге приводит к генерации гипотез для перевода. Изучение этого процесса не только углубляет наше понимание генерации последовательностей, но также помогает нам улучшить архитектуру и производительность будущей модели.


