
В этой статье мы рассмотрим механизм вывода в обученной модели, используя строку «он знает это» в качестве примера. Мы опишем архитектуру модели, которая точно воспроизводит процесс обучения, и рассмотрим различные компоненты, участвующие в преобразовании входных токенов в осмысленные предсказания. Ключевые параметры, такие как размер словаря, количество единиц, слоев и «голов» внимания, будут рассмотрены для предоставления контекста для функциональности модели.

Обзор архитектуры модели
Рассмотрим механизм вывода обученной модели на примере следующей строки _он_знает_это. Архитектура модели, для наглядности, будет примерно такой же, как в рассмотренном примере механизма процесса обучения:
- vocab: 26
- num_units: 6
- num_layers: 1
- num_heads: 2
- ffn_inner_dim: 12
- maximum_relative_position: 8
Представление токена и обработка кодировщиком
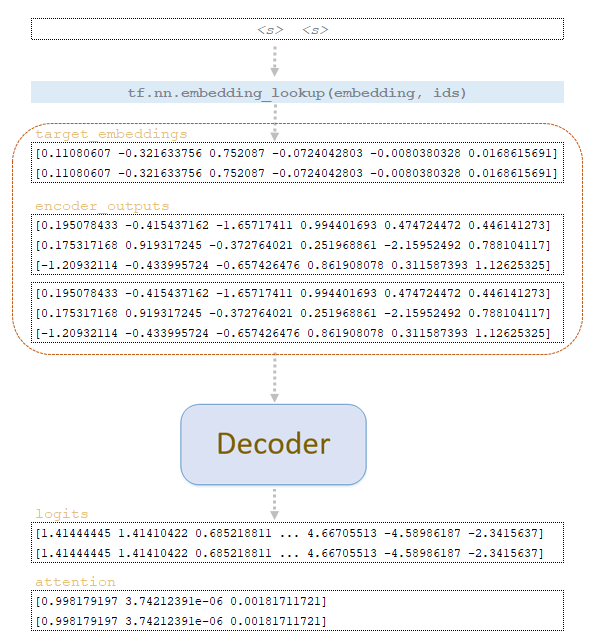
Для каждого токена векторное представление токена извлекается из исходной матрицы встраивания обученной модели и подается на вход кодировщика. В кодировщике происходят абсолютно все те же преобразования, что и при обучении модели. Отличие в том, что к матрицам не применяется механизм дропаута. После преобразований в кодировщике мы получаем encoder_outputsmatrix. (Изображение 1 - Матрица encoder_outputs)

Параметры и инициализация вывода
Далее рассмотрим пример вывода со следующими параметрами. В нашем случае были использованы следующие параметры вывода:
- beam_size = 2
- length_penalty = 0.2
- coverage_penalty = 0.2
- sampling_topk = 5
- sampling_temperature = 0.5
Затем применение функции tfa.seq2seq.tile_batch(encoder_outputs, beam_size) позволяет дублировать матрицу значений, полученную после кодировщика, на величину beam_size. Выход представляет собой матрицу значений * размер луча, в нашем случае два. (Изображение 2 — Выходы кодировщика * размер луча)

Вторым шагом является инициализация переменных:
1) размер пакета для перевода, в нашем примере batch_size = 1;
2) матрица start_ids, содержащая индексы токенов начала последовательности <s> по размерности beam_size → start_ids = tfa.seq2seq.tile_batch (start_ids, beam_size) = [1 1];
3) матрица finished, заполненная нулями, с типом данных boolean и размерностью batch_size * beam_size → tf.zeros ([batch_size * beam_size], dtype=tf.bool)] = [0 0];
4) матрица initial_log_probs → tf.tile ([0.0] + [-float(“inf”)] * (beam_size - 1), [batch_size]) = [0 -inf];
5) инициализируется словарь с дополнительными переменными extra_vars, который содержит следующие переменные:
- parent_ids: tf.TensorArray(tf.int32, size=0, dynamic_size=True) → []
- sequence_lengths: tf.zeros([batch_size * beam_size], dtype=tf.int32) → [0 0]
- accumulated_attention: tf.zeros([batch_size * beam_size, attention_size]), где attention_size размер матрицы encoder_outputs (tf.shape(encoder_outputs)[1] = 3) → [[0 0 0] [0 0 0]]
Затем в цикле повторяем до тех пор, пока не достигнем максимального значения (максимальное значение по умолчанию — maximum_decoding_length = 250) или до конца последовательности токен сгенерирован.
Шаг 0
По матрице start_ids из целевой матрицы эмбеддингов обученной модели извлекаются векторные представления токенов и вместе с дублированной на число beam_size матрицей encoder_outputs подаются на вход декодера. В декодере происходят абсолютно все те же преобразования, что и при обучении модели. Разница в том, что не формируется тензор future_mask, а также не применяется механизм dropout. (Изображение 3 - процесс декодера)
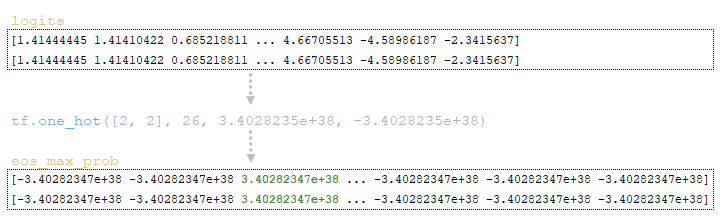
Переменные batch_size = 1 и vocab_size = 26 формируются по размерности матрицы логитов, полученной от декодера. Далее с помощью функции tf.one_hot(tf.fill([batch_size], end_id), vocab_size, on_value=logits.dtype.max формируется матрица eos_max_prob, где:
- tf.fill([batch_size], end_id); end_id — индекс токена конца последовательности </s> → [2 2];
- logits.dtype.max — максимальное значение типа данных tf.float32, которое равно 3.4028235e+38 или 340282350000000000000000000000000000000000;
- logits.dtype.min — это максимальное значение типа данных tf.float32, которое равно -3,4028235e+38 или -34028235000000000000000000000000000000000.
Таким образом, на выходе получается матрица eos_max_prob размером 2 x 26, где элементы с индексом 2 будут заполнены максимальным значением, а все остальные элементы будут заполнены минимальным значением. (Изображение 4 — матрица eos_max_prob)
Используя функцию tf.where (tf.broadcast_to (tf.expand_dims (finished, -1), tf.shape(logits)), x=eos_max_prob, y=logits), где матрица finished меняет размерность: tf.expand_dims([0, 0], -1) → [ [0][0]], получаем массив значений по размерности матрицы logits: tf.shape(logits) → [2 26] и увеличиваем размерность: tf.broadcast_to ([[0], [0]], [2, 26]) → [[0 0 0 0 ... 0 0 0 0], [0 0 0 0 ... 0 0 0]].
Поскольку готовая матрица содержит нули, а расширенная матрица содержит нули, значения конечной матрицы заполняются значениями из матрицы logits.
Матрица log_probs вычисляется из матрицы logits с помощью функции tf.nn.log_softmax(logits). (Изображение 5 — Матрица log_probs)

Если coverage_penalty != 0, дополнительно выполняются следующие действия:
- матрица finished модифицируется и преобразуется с помощью функции tf.math.logical_not([0, 0]) для формирования матрицы not_finished → [1 1];
- результирующая матрица размерно модифицируется tf.expand_dims (tf.cast( not_finished, awareness.dtype), 1) → [[1], [1]] ;
- полученная матрица умножается на матрицу внимания; (Изображение 6 - матрица внимания)
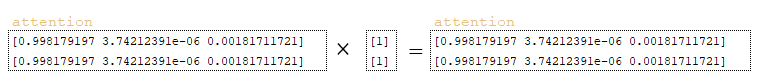
- формируется переменная collected_attention. (Изображение 7 - переменная collected_attention )
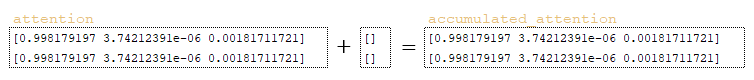
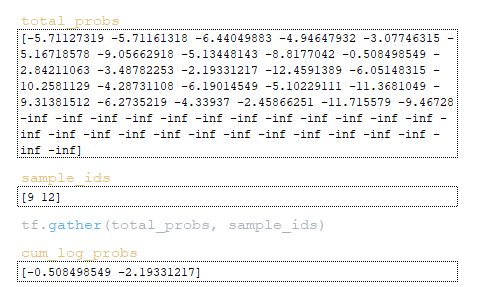
Затем матрица total_probs формируется путем сложения матрицы log_probs и инвертированной матрицы cum_log_probs → log_probs + tf.expand_dims (cum_log_probs, 1). (Изображение 8 - матрица total_probs)
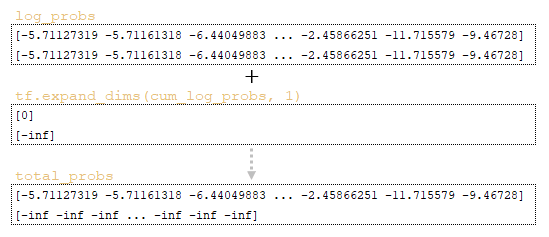
По матрицам total_probs, sequence_lengths, finished и collected_attention рассчитываются scores. Расчет баллов включает следующие шаги:
1) Исходная матрица scores → scores = total_probs инициализируется матрицей total_probs (Изображение 9 - матрицы total_probs и scores);
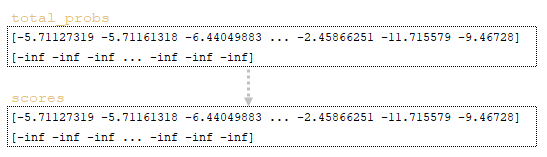
2) Если length_penalty != 0, выполнить следующие действия:
- формируется матрица expand_sequence_lengths - матрица sequence_lengths размерно изменяется tf. expand_dims ( sequence_lengths, 1) → [[0], [0]] ;
- к матрице expand_sequence_lengths добавляется единица и матрица приводится к типу значений log_probs - tf.cast( expand_sequence_lengths + 1, log_probs.dtype) → [[0], [0]] + 1 = [[1], [1]] ;
- формируется матрица sized_expand_sequence_lengths - к полученной выше матрице прибавляется константа 5 и делится на константу 6: (5.0 + expand_sequence_lengths ) / 6.0 → (5 + [1]) / 6 = [[1], [1]].
- формируется матрица sized_sequence_lengths - матрица sized_expand_sequence_lengths возводится в степень, указанную в параметре length_penalty: tf.pow(sized_expand_sequence_lengths, length_penalty) → [[1]**0.2, [1]**0.2] = [[1], [1]] ;
- значения матрицы корректируются путем целочисленного деления на матрицу penalized_sequence_lengths → баллы /= penalized_sequence_lengths. (Изображение 10 - баллы)

3) Если coverage_penalty != 0, то выполняем следующие действия:
- матрица equal формируется матрицей collected_attention с помощью функции tf.equal(accumulated_attention, 0.0) tf.expand_dims (sequence_lengths, 1), т.е. проверяем элементы матрицы на равенство нулю; (Изображение 11 - матрица equal)

- матрица collected_attention используется для формирования матрицы единиц ones_like с помощью функции ones_like"> tf.ones_like(accumulated_attention); (Изображение 12 - матрица ones_like)

- с помощью функции where">tf.where(equal, x=ones_like, y=accumulated_attention) переопределяется матрица collected_attention, где значения будут браться из x, если элемент из equal равен единице, в противном случае из y. Так как все элементы матрицы equal равны нулю, то все значения будут браться из y; (Изображение 13 - матрица collected_attention)

- формируется матрица coverage_penalty - из матрицы collected_attention берется минимальное значение и unit и вычисляется логарифм, после чего элементы суммируются tf.reduce_sum (tf.math.log(tf.minimum( accumulated_attention , 1.0)), axis=1) ; (Изображение 14 - матрица coverage_penalty )

- полученная на предыдущем шаге матрица coverage_penalty умножается на матрицу finished coverage_penalty *= finished ; (Изображение 15 - coverage_penalty )

- Матрица scores корректируется на указанное значение coverage_penalty из параметров и вычисленной матрицы coverage_penalty - scores += self. coverage_penalty * tf.expand_dims(coverage_penalty, 1). (Изображение 16 - матрица scores)
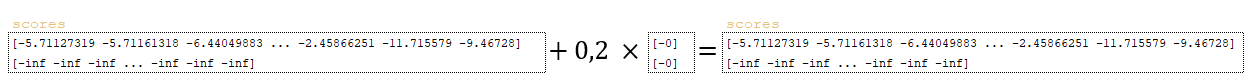
Следующий шаг включает работу с матрицами scores и total_probs. Матрица scores преобразуется с помощью tf.reshape (scores, [-1, beam_size * vocab_size]). (Изображение 17 - матрица scores)
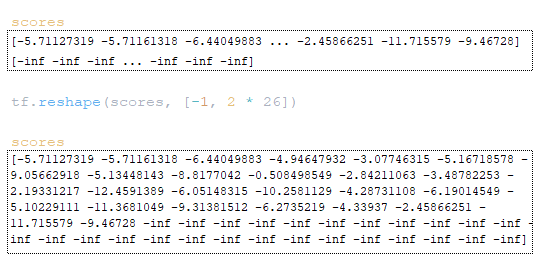
Матрица total_probs преобразуется с помощью tf.reshape (scores, [-1, beam_size * vocab_size]). (Изображение 18 - матрица total_probs)
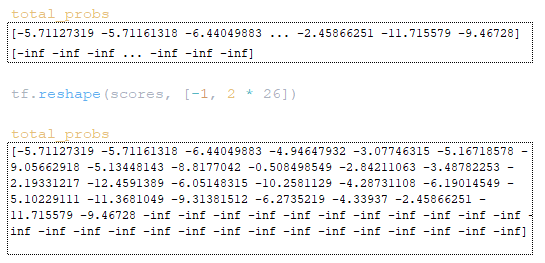
Следующий шаг — вычисление идентификаторов целевых токенов sample_ids и оценок для этих токенов sample_scores:
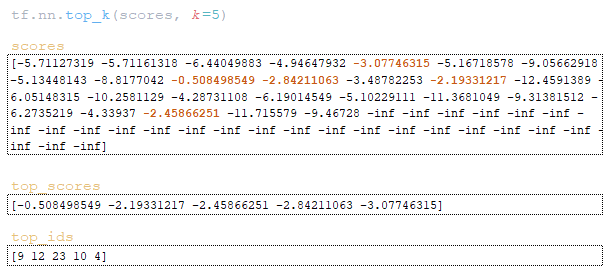
- с помощью функции tf.nn.top_k находим максимальные значения и их индексы top_scores, top_ids = tf.nn.top_k(scores, k=sampling_topk) (если параметр sampling_topk не указан, то k будет равен beam_size); (Изображение 19 — матрица top_scores и top_ids)
- матрица top_scores делится на значение параметра sampling_temperature ; (Изображение 20 — параметр sampling_temperature )
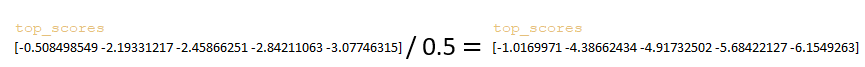
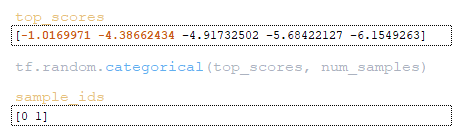
- из скорректированной матрицы top_scores с помощью функции tf.random.categorical извлекаются индексы элементов в ряду beam_size ; (Изображение 21 — sample_ids)
- по индексам элементов с помощью функции tf.gather извлекаются индексы токенов из матрицы top_ids; (Изображение 22 - индексы токенов)
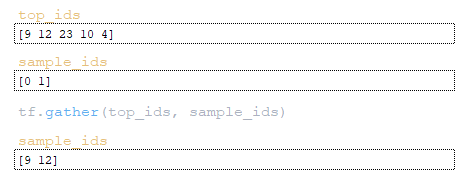
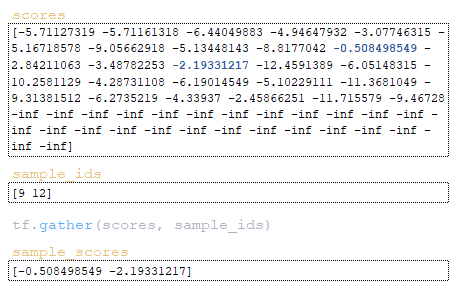
- по индексам элементов оценки для этих токенов извлекаются из матрицы оценок с помощью функции tf.gather. (Изображение 23 - матрица sample_scores)
Затем формируется матрица cum_log_probs из полученных значений sample_ids из матрицы total_probs. (Изображение 24 - Матрица cum_log_probs) Матрица word_ids формируется путем деления остатка на значение vocab_size → word_ids = sample_ids % vocab_size = [9 12] % 26 = [9 12].
Целочисленным делением на значение vocab_size формируется матрица beam_ids → beam_ids = sample_ids // vocab_size = [9 12] // 26 = [0 0 0] из полученных значений sample_ids, целочисленным делением на значение vocab_size.
Используя полученные матрицы word_ids и beam_ids и значение beam_size, формируется матрица beam_indices → beam_indices = (tf.range (tf.shape(word_ids)[0]) // beam_size) * beam_size + beam_ids = ([0 1] // 2) * 2 + [0 0 0] = [ 0 0].
Дальнейший шаг включает перераспределение матриц sequence_lengths, finished и sequence_lengths следующим образом:
- матрица sequence_lengths → sequence_lengths = tf.where(finished, x= sequence_lengths, y= sequence_lengths + 1); (Изображение 25 - матрица sequence_lengths )

После этого работа со словарем extra_vars будет осуществляться следующим образом:
- матрица finished → finished = tf.gather(finished, beam_indices ) → tf.gather([0 0], [0 0]) = [0 0] ;
- матрица sequence_lengths → finished = tf.gather ( sequence_lengths, beam_indices ) → tf.gather([1 1 1], [0 0]) = [1 1].
- матрица sequence_lengths сохраняется в словаре extra_vars по ключу sequence_lengths → extra_vars = {“ sequence_lengths ”: sequence_lengths };
- beam_ids и текущие значения шагов записываются в словарь extra_vars по ключу parent_ids → extra_vars = {“parent_ids”: parent_ids.write(step, beam_ids)};
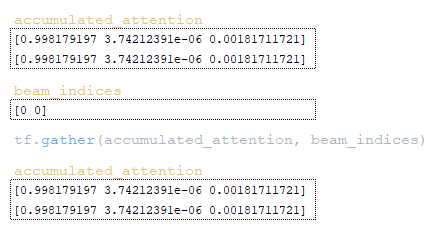
- матрица collected_attention сохраняется в словаре extra_vars по ключу collected_attention → tf.gather( accumulated_attention, beam_indices); (Изображение 26 - матрица collected_attention )
Это завершает шаг 0, матрицы word_ids, cum_log_probs, finished и словарь extra_vars передаются в начало цикла и всего процесса, описанного выше. (Изображение 27 - матрицы word_ids, cum_log_probs,finished и словарь extra_vars)

Заключение
В этой статье мы тщательно изучили механизм вывода обученной модели, используя пример строки «он знает это». Мы начали с описания архитектуры модели и основных параметров, которые определяют ее структуру, таких как размер словаря, количество единиц и слоев. Процесс представления токенов и обработки кодировщика был подробно описан, подчеркивая преобразование входных токенов через кодировщик без применения дропаута, тем самым обеспечивая согласованность с этапом обучения. Мы обсудили инициализацию параметров вывода и циклическую структуру, которая управляет итеративным процессом декодирования, выделив различные задействованные матрицы, включая log_probs, total_probs и управление штрафами.
Во второй части этой статьи мы рассмотрим шаг 1, шаг 2 и шаг 3 соответственно, где также будут раскрыты детали механизма вывода.


