
Перевод с одного языка на другой — одна из наиболее востребованных и сложных задач в современном многоязычном мире. Долгое время этот процесс осуществлялся исключительно силами профессиональных людей-переводчиков. Однако в последние десятилетия появилась технология, способная взять на себя часть этой работы — машинный перевод. Различают несколько видов машинного перевода, один из них — статистический машинный перевод.
Что такое статистический машинный перевод?
Статистический машинный перевод (англ. Statistical machine translation, SMT) — это метод машинного перевода, при котором перевод генерируется на основе статистических моделей, основанных на анализе двуязычных корпусов текста.
История возникновения статистического машинного перевода
В 1949 году Уоррен Уивер, один из пионеров информатики, опубликовал работу, в которой предложил использовать принципы теории информации Клода Шеннона для автоматического перевода текстов. Уивер представил идею, что перевод можно рассматривать как статистическую задачу - определение наиболее вероятных соответствий между словами и фразами двух языков на основе анализа больших коллекций параллельных текстов.
Однако в то время вычислительные мощности и доступные наборы данных были недостаточными для реализации этого подхода. Поэтому идеи Уивера не получили широкого развития вплоть до конца 1980-х годов. В этот период исследователи из Исследовательского центра Томаса Дж. Уотсона IBM вновь обратились к концепции статистического машинного перевода.
Таким образом, первоначальные концептуальные идеи и их дальнейшее развитие в 1980–90-х годах привели к практической реализации и широкому распространению статистического машинного перевода.
Как работает статистический машинный перевод?
Статистический машинный перевод рассчитывает наиболее вероятное значение каждого слова или фразы в предложении, используя статистические методы. Чем чаще встречается вариант перевода, тем выше вероятность, что он верный.
Статистический машинный перевод работает следующим образом:
1. Сбор параллельных корпусов данных. Собираются большие коллекции текстов на двух языках, где каждый текст на одном языке имеет соответствующий перевод на другом. Эти параллельные тексты используются в качестве обучающих данных для системы перевода.
2. Обучение моделей. На основе параллельного корпуса обучаются вероятностные модели перевода. Модели учатся предсказывать, какой перевод слова или фразы является наиболее вероятным.
3. Перевод. Когда нужно перевести новый текст, статистическая модель анализирует его и генерирует наиболее вероятный перевод каждого слова и фразы. Таким образом, весь текст переводится путем поиска наиболее вероятных переводческих соответствий.
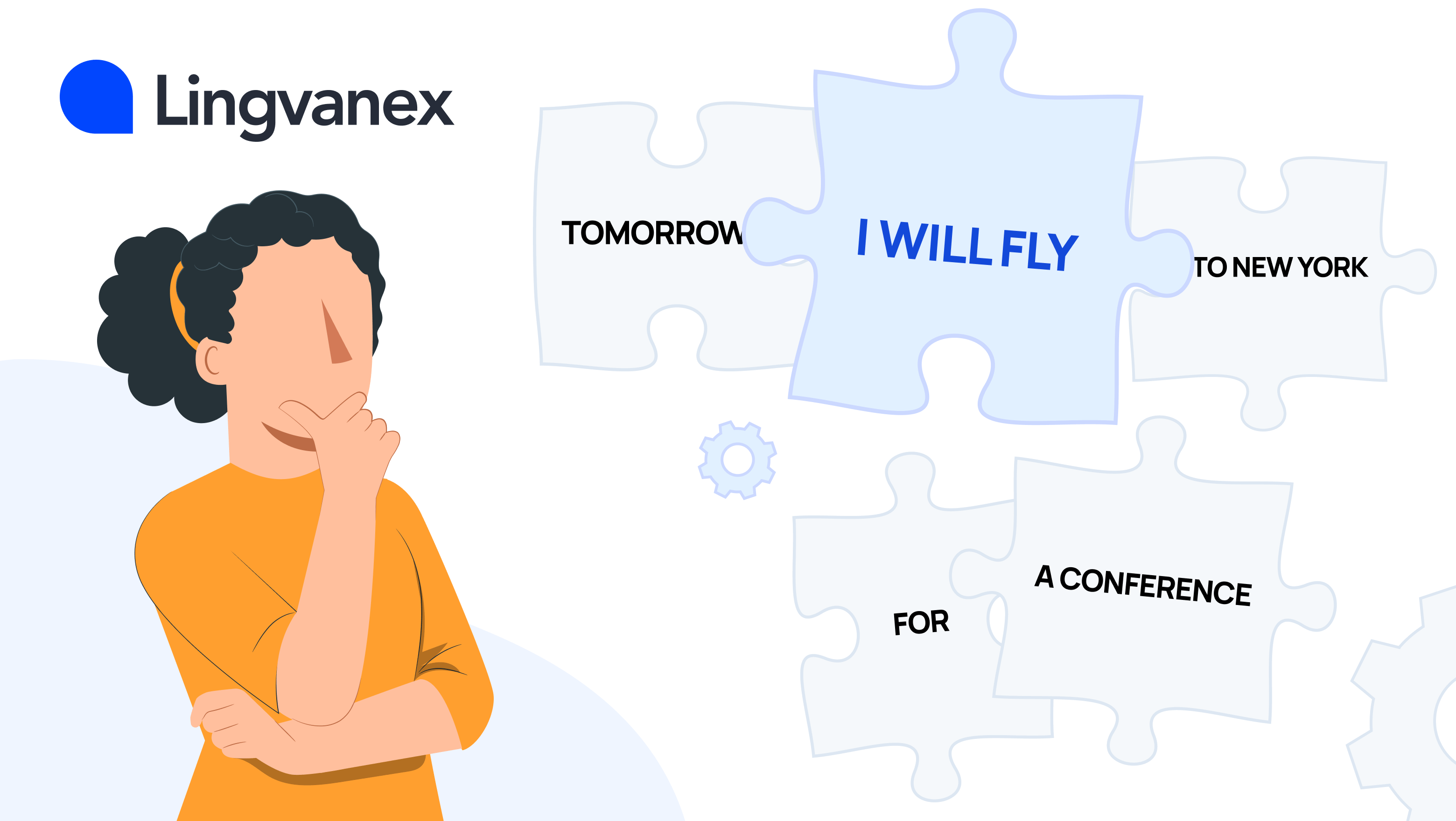
Рассмотрим на примере фразы «Завтра я полечу в Нью-Йорк на конференцию». Сначала система разбивает текст на слова или фразы. В данном случае: «Завтра», «я», «полечу», «в Нью-Йорк», «на конференцию». В нашем случае «завтра» может переводиться как «tomorrow», «я» — как «I», «полечу» может переводиться как «will fly» / «am flying» / «fly», «в Нью-Йорк» — «to New York», «на конференцию» может переводиться как «for a conference» или «to a conference». Для каждой комбинации переводов оценивается вероятность на основе частоты встречаемости в параллельных текстах. Например: Tomorrow I will fly to New York for a conference / Tomorrow I am flying to New York for a conference и т.п. Система выбирает наиболее вероятную комбинацию переводов. В данном случае, это I'm flying to New York tomorrow for a conference.
Этапы тренировки статистических моделей машинного перевода
Сбор обучающих данных
Первый шаг в создании машины SMT — сбор большого количества двуязычных текстов. Их берут из переводной литературы, многоязычных веб-сайтов и документов. От качества и разнообразия учебного материала зависит точность перевода.
Фразовый или n-граммный перевод
На данном этапе исходные предложения разбиваются на более мелкие части — фразы. Их длина варьируется от отдельных выражений до более длинных последовательностей. Машина распознает и сопоставляет единицы языка на исходном и целевом языках.
Подсчет вероятностей
После сопоставления система вычисляет вероятность того, что фраза на одном языке будет переведена определенным образом на другом. Делается это на основе переводов в обучающих текстах. Чем чаще встречается вариант перевода, тем выше его вероятность.
Языковое моделирование
Затем происходит языковое моделирование получившегося контента — оценка вероятности последовательности слов в исходном и целевом языках. Это улучшает грамматическую корректность и связность сгенерированных переводов, помогает учитывать контекст и лингвистические особенности текста.
Декодирование
На этом этапе автоматический переводчик ищет наиболее подходящий перевод для каждой исходной фразы. Чтобы оценить несколько вариантов учитываются статистические оценки и такие алгоритмы, как лучевой поиск или динамическое программирование.
Переупорядочивание и постобработка
На этом этапе программа использует статистические данные из огромного количества текстов чтобы учесть особенности языков для получения нового связного текста. В разных, даже родственных языках, грамматика и порядок слов в предложении может значительно различаться.
Например, в русском языке порядок слов довольно гибкий, в немецких придаточных предложениях глагол часто ставится в конец, в английском языке порядок слов строго фиксирован: подлежащее, сказуемое, дополнение. В испанском языке, например, обычно прилагательное следует за существительным, но в некоторых случаях оно может стоять перед ним, это слегка меняет заложенный смысл. Часто личные местоимения просто опускаются, поскольку лицо можно определить по форме глагола.
Оценка
На финальном этапе человек оценивает качество переводов статистической системы с помощью метрик, как например BLEU (Bilingual Evaluation Understudy). Результаты оценки используются для улучшения статистических моделей, обучающих данных и конфигурации системы.
Методы оценки качества машинного перевода
Для оценки общей эффективности результатов машинного перевода было разработано несколько метрик. Вот несколько часто используемых:
BLEU (Bilingual Evaluation Understudy)
BLEU является наиболее популярной метрикой, которая измеряет сходство между сгенерированным переводом и одним или несколькими эталонными переводами. Она рассчитывает точность путем оценки n-грамм (непрерывных последовательностей фраз) в переводе-кандидате и эталонных переводах. Чем выше показатели BLEU, тем лучше качество перевода.
COMET (оценка машинного перевода на основе консенсуса)
COMET — это метрика, которая принимает во внимание не только машинный перевод и эталон, но и переводимый текст-первоисточник. Оценивает адекватность и эквивалентность.
METEOR (Метрика для оценки перевода с явным упорядочиванием)
METEOR - метрика чувствительная к порядку слов и синонимам.
TER (Translation Edit Rate)
TER показывает, сколько правок нужно сделать человеку в полученном переводе, чтобы он полностью соответствовал эталонному. Эти правки могут включать добавление, удаление и замену слов, а также изменение порядка слов в предложении. Чем ниже показатели TER, тем лучше перевод.
NIST (Национальный институт стандартов и технологий)
NIST — это метрика оценки, разработанная Национальным институтом стандартов и технологий США для оценки качества автоматического машинного перевода. Она использует точность и запоминание n-грамм для оценки результатов машинного перевода по сравнению с эталонными переводами.
ROUGE (Recall-Oriented Understudy for Gisting Evaluation)
ROUGE измеряет совпадение n-грамм между переводом устройства и эталонным переводом.
HTER (Human-focused Translation Edit Rate)
HTER — метрика, сочетающая компьютерную оценку с человеческими суждениями. Она, как и TER, измеряет дистанцию редактирования между переводом, созданным системой, и эталонными переводами. Однако при этом правки сравниваются с вариантами, отредактированными переводчиками-людьми, чтобы оценить влияние на усилия по редактированию.
Важно отметить, что ни одна метрика не может охватить все аспекты. Выбор метрики зависит от конкретных целей. Для получения более полной информации о качестве перевода наряду с метриками часто используются человеческий субъективный анализ.
Метрики для улучшения систем машинного перевода
Метрики используются в различных областях для измерения различных аспектов производительности, эффективности, качества или прогресса. Они предоставляют количественные данные, которые можно использовать для оценки успеха или неудачи определенного процесса, системы или проекта. Вышеуказанные метрики могут быть использованы для улучшения структур перевода с помощью следующих методов:
Бенчмаркинг и сравнение
Метрики, такие как BLEU, METEOR, TER и NIST, позволяют проводить объективные сравнения между системами машинного перевода. Сравнивая результаты работы различных систем с помощью этих метрик, разработчики могут определить, какая система работает лучше, и использовать ее в качестве базовой для аналогичных улучшений.
Настройка системы
Метрики являются механизмом обратной связи в процессе разработки модели машинного перевода. Подсчитывая рейтинги метрик для разных итераций или вариантов машинного перевода, разработчики могут определить влияние конкретных модификаций. Это позволяет качественно настроить процесс обучения и выявить области, требующие доработки.
Выбор обучающих данных
Оценивая качество переводов, выполненных на специальных учебных наборах данных, разработчики могут определить, какие наборы данных дают более высокие результаты, и ориентироваться на них при обучении системы.
Оптимизация параметров
Системы машинного перевода имеют параметры, которые можно регулировать для повышения общей производительности: размер словаря, способы декодирования и обработки текста, архитектура нейронной сети. Для оптимизации этих параметров в качестве объективной характеристики можно использовать метрики.
Анализ ошибок
Метрики помогают выявить конкретные виды ошибок, допускаемых автоматическими системами машинного перевода. Это позволяет разработчикам получить представление о слабых сторонах устройства и сконцентрироваться на решении конкретных задач по его совершенствованию.
Заключение
Статистический машинный перевод стал важным шагом вперед в развитии систем автоматического перевода, но он имеет свои ограничения. Статистические системы не всегда может уловить нюансы и контекст исходного текста. В настоящее время наиболее продвинутым и эффективным видом машинного перевода считается гибридный, его использует компания Lingvanex. Смысл гибридного машинного перевода заключается в смеси технологий статистического и нейронного.



