
В последние десятилетия системы распознавания речи сильно продвинулись — от громоздких голосовых сообщений до мгновенных субтитров в прямом эфире. 2025 году эта технология присутствует повсеместно: в голосовых помощниках, колл-центрах, переводческих приложениях и даже в юридических расшифровках. Однако вместе с громкими обещаниями «точности, как будто текст обрабатывал человек» растут и сомнения.
В реальных условиях бизнеса мы все еще сталкиваемся с серьезными ошибками. Спросите любую компанию, которая работает с поддержкой клиентов, голосовыми ботами или расшифровкой деловых встреч — технология часто подводит в самые важные моменты.
Почему? Потому что большинство моделей автоматического распознавания речи (ASR) обучаются и тестируются в идеальных условиях, а не в шумной, многоязычной и насыщенной речью среде, которая характерна для реального мира.
В этой статье мы расскажем, почему традиционные тесты часто вводят в заблуждение, как бизнесу стоит оценивать ASR-решения и почему Lingvanex находится на передовой нового поколения адаптивных систем распознавания речи, готовых к работе в корпоративной среде. Мы провели серию тестов, чтобы сравнить самые популярные API распознавания речи на рынке. Результаты получились неожиданными, но информативными и полезные для любой команды, создающей голосовые продукты.

Почему точная оценка распознавания речи критически важна для бизнеса
Распознавание речи перестало быть футуристической новинкой и стало важнейшей технологией, интегрированной в банковские приложения, платформы для видеоконференций, юридические программы и корпоративные сервисы поддержки. В 2025 году компании не просто применяют распознавание речи — они полностью на него полагаются.
Некачественное автоматическое распознавание речи — это не просто неудобство, а серьёзный финансовый риск. При ухудшении точности транскрипции страдает весь процесс:
- влияние на клиентский сервис: ошибки в распознавании речи в службе поддержки ведут к увеличению нерешенных проблем и падению уровня удовлетворенности клиентов.
- нарушение нормативных требований: неточные расшифровки в строго регулируемых областях (финансы, медицина) могут привести к нарушениям и наложению штрафов.
- потеря ценных данных: упущенные инсайты важных встреч или интервью негативно сказываются на развитии продуктов и выработке стратегии.
Проще говоря:
- Если ASR воспринимает «пометить заказ» как «поместить заказ» — это не просто ошибка, это потеря клиента.
- Если отдел комплаенса использует расшифровку встреч, в которой отсутствует половина финансовых терминов — вы нарушаете нормативные требования.
- Если голосовой ассистент распознаёт лишь половину испанских фраз — это ударит по вашим показателям NPS.
Ошибки в распознавании речи — не теоретическая проблема. Они стоят денег.
Реальность бросает вызов — идеальной речи не существует: пользователи говорят небрежно, проглатывают окончания, делают паузы и бормочут под нос, акценты и диалекты меняют звучание слов. При этом микрофоны часто передают искажённый звук, а фоновые голоса и шумы создают "акустический коктейль". По-настоящему полезное решение должно работать стабильно и адаптироваться к неидеальным условиям в реальном времени.
Вот почему качество так важно. Ведь распознавание — это не просто набор слов, это понимание смысла и эмоций, соблюдение нормативных требований. Если слова не распознаны, смысл теряется. Когда на кону репутация и результаты — требуется абсолютная точность без компромиссов.
Методология оценки работы систем распознавания речи
Чтобы получить реалистичную картину, как работают современные сервисы распознавания, мы разработали тесты, максимально приближенные к реальным сценариям — а не лабораторным условиям. Цель была проста: проверить, насколько хорошо каждая система справляется со сложностями повседневной речи в разных сферах, на разных устройствах и на разных языках. Для объективной оценки возможностей современных систем распознавания мы создали тесты, имитирующие реальные сценарии использования, а не стерильные лабораторные условия. Наша задача заключалась в том, чтобы определить, насколько эффективно каждая технология обрабатывает естественную речь с ее типичными сложностями — в различных сферах, на разных устройствах и языках.
Вот, что мы сделали.
Аудиозаписи
Мы подготовили подборку аудиозаписей, которые охватывают основные типы звукового контента в деловой среде:
- четкие студийные записи — для оценки точности в идеальных условиях;
- фрагменты телефонных переговоров — с ограниченной полосой частот и низким битрейтом;
- обсуждения в формате совещаний — с перекрывающимися репликами и разным темпом речи;
- фоновые записи из кафе и улиц — с помехами, шумами и посторонними разговорами.
Languages Tested
Для обеспечения репрезентативности тестирования были использованы аудиозаписи на 12 языках: английском, китайском (упрощенном), арабском, португальском, испанском, французском, немецком, итальянском, русском, украинском, казахском и польском.
Языки
Основное внимание уделялось двум показателям:
- 1. WER (Word Error Rate): Более низкий коэффициент WER указывает на более высокую точность распознавания речи. Мы включили WER в нашу оценку, поскольку он является общепринятым отраслевым стандартом, позволяющим проводить последовательное сравнение общей производительности системы.
- 2. CER (Character Error Rate): в отличие от WER, CER измеряет ошибки на уровне символов, обеспечивая более детальное представление о точности распознавания. Этот показатель играет существенное значение в ситуациях, когда важна каждая буква, например, при обработке технических терминов или собственных имен. Более низкий CER свидетельствует о том, что система может с большей точностью распознавать речевой ввод.
Подробнее о проблемах современных методик сравнения ASR и о том, как команда Lingvanex решает их читайте в статье.
Результаты, которые говорят сами за себя
Чтобы оценить работу сервисов в реальных условиях, мы провели параллельное тестирование Lingvanex и ведущих ASR-решений — Deepgram (Nova-2), AssemblyAI, Gladia и Speechmatics. Для сравнения были выбраны API, представляющие актуальные предложения на рынке готовых решений для преобразования речи в текст. Несмотря на различия в архитектуре, моделях развертывания и стратегических подходах, все они заявляют о высоком качестве и масштабируемости.
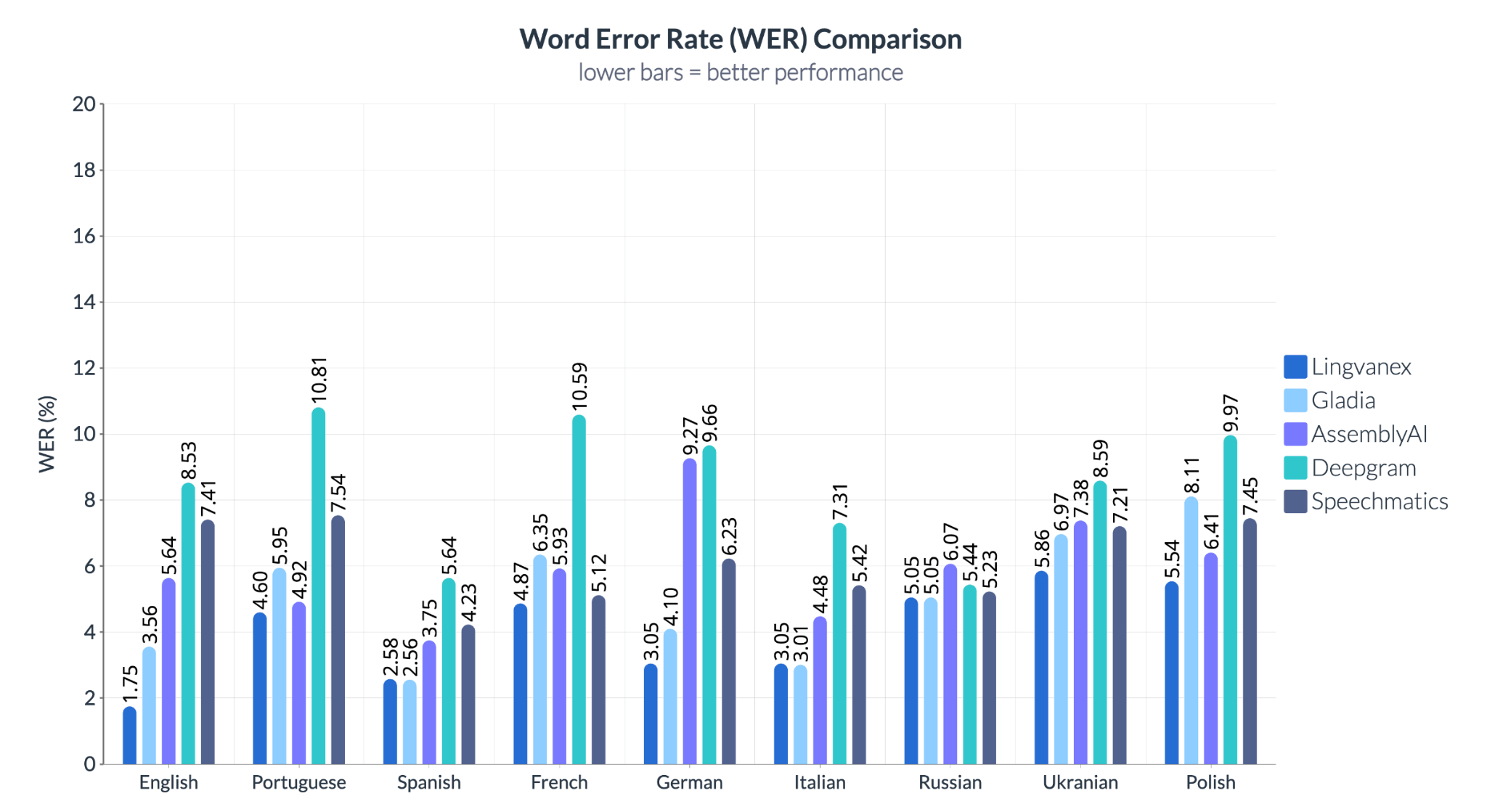
Результаты выявили существенные различия в эффективности работы систем в зависимости от языка и компании-разработчика. Lingvanex показал наиболее стабильные результаты, демонстрируя наименьшее количество ошибок по сравнению с другими сервисами, особенно в переводах с английского, немецкого и испанского — ключевых языков делового мира. В то же время Deepgram продемонстрировал слабые результаты при обработке португальской и французской речи, а у Speechmetrics наблюдалась нестабильность в работе со славянскими языками, включая украинский и польский.
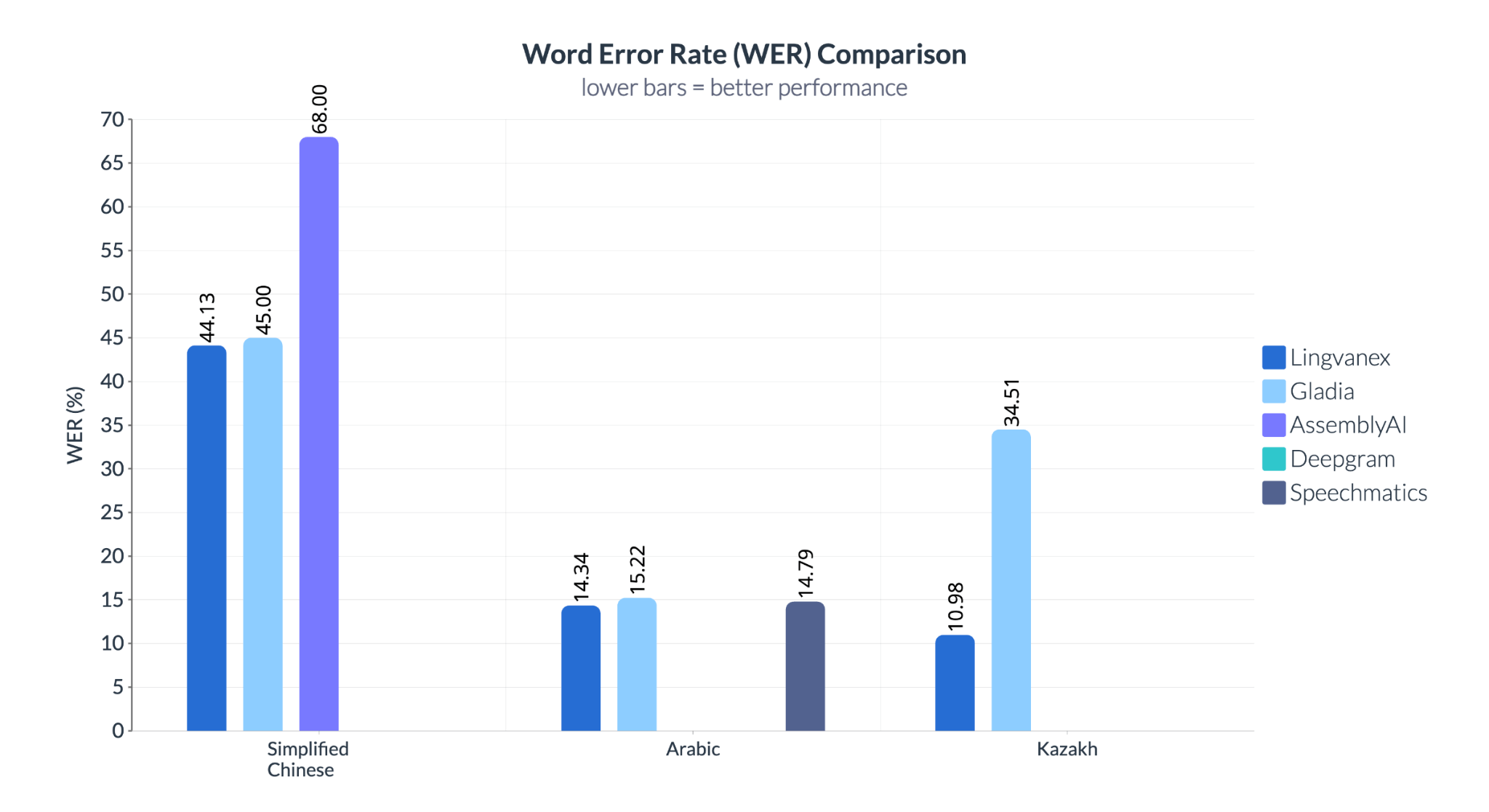
Различия особенно выражены для казахского языка: здесь Lingvanex показывает отличный результат с WER 10,98%, тогда как Gladia значительно уступает с 34,51%, что подтверждает способность Lingvanex эффективно работать с разными языками. В то же время для упрощенного китайского Speechmatics демонстрирует слабые результаты — WER 68%, в то время как у Lingvanex этот показатель значительно ниже (44,13%).
Корпоративная система распознавания речи – это не просто точный английский. Это универсальный инструмент, который одинаково хорошо понимает любые языки, акценты и работает даже в шумных условиях. В глобальном бизнесе поддержка лингвистического разнообразия – не преимущество, а стандарт. Если ваше решение спотыкается на арабском или китайском – о мировом рынке можно забыть.Lingvanex подтверждает свою эффективность там, где другие терпят неудачу — в реальных рабочих ситуациях.
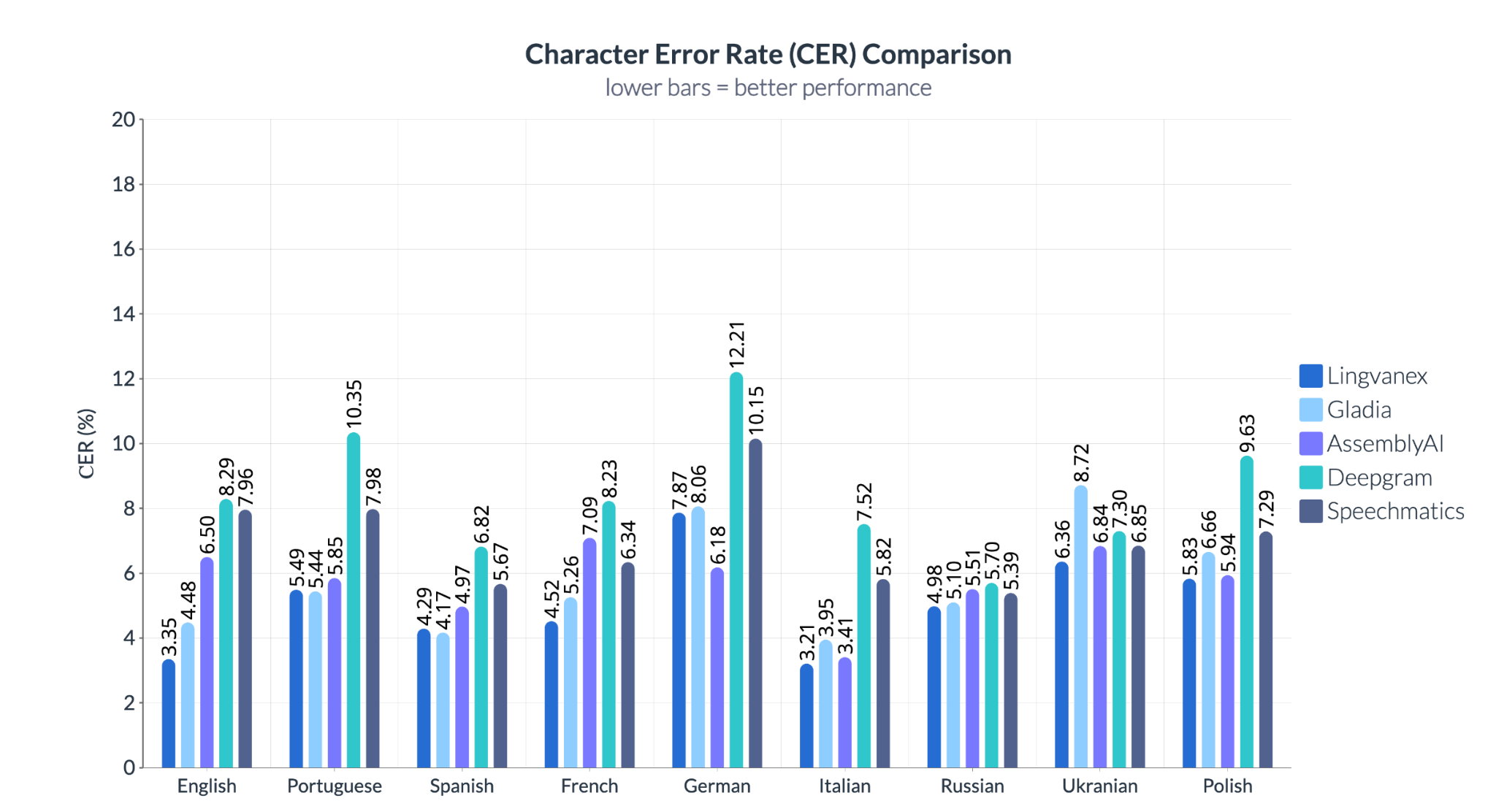
Lingvanex показывает стабильно высокую точность распознавания на уровне символов, что особенно важно для языков, где даже небольшие ошибки могут привести к серьезным последствиям, например, немецкого (6,18%) и английского (3,35%). В отличие от него, Deepgram демонстрирует значительные колебания в точности, достигая более 12% CER на немецком, что снижает его надежность для технических и юридических задач. Speechmatics уступает конкурентам в обработке английского и польского, а Gladia работает нестабильно, особенно плохо справляясь с казахским и славянскими языками.
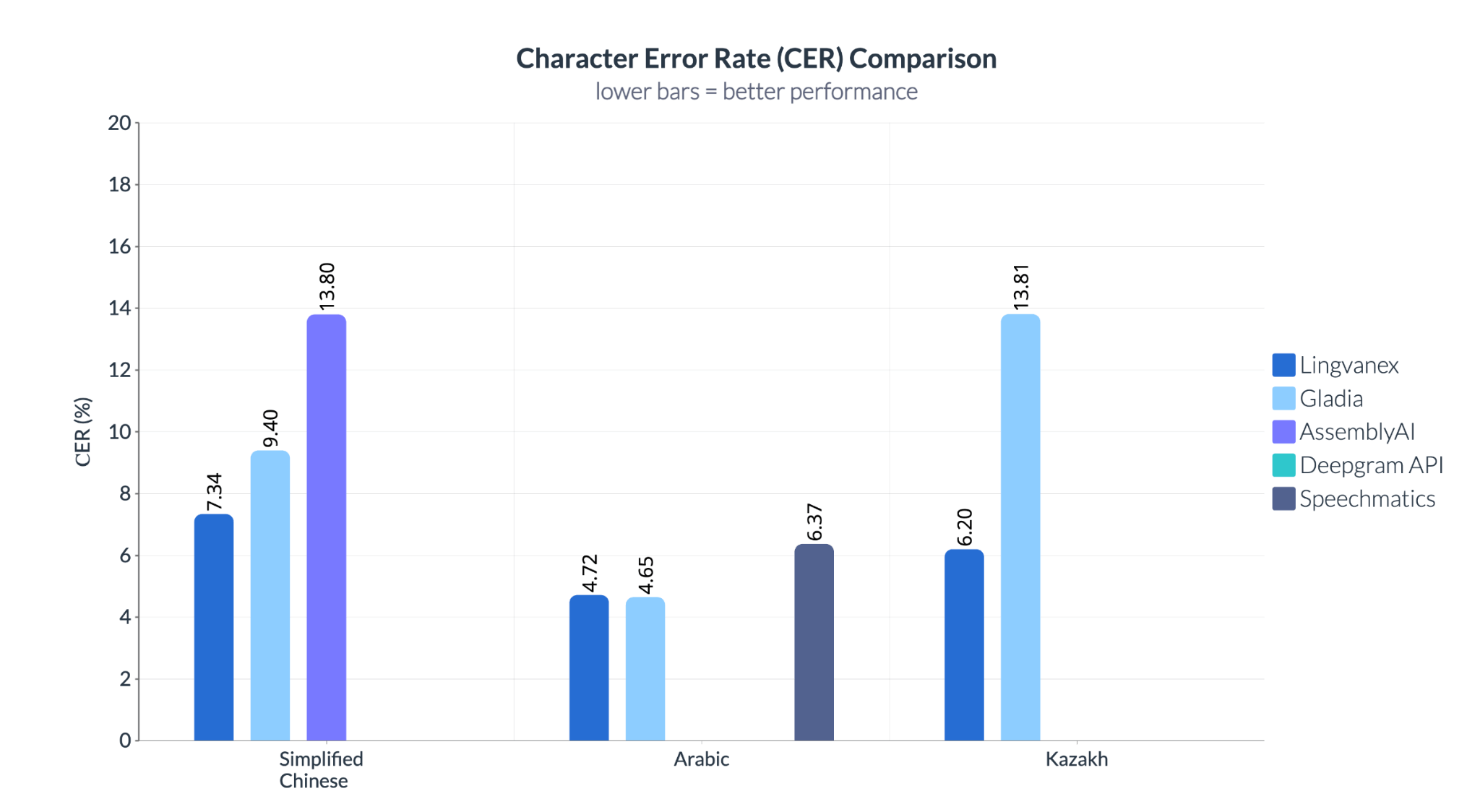
В китайском языке AssemblyAI демонстрирует более высокий процент ошибок — 13,8%, что почти вдвое превышает показатель Lingvanex (7,34%). Для казахского языка Gladia с CER 13,81% явно уступает в качестве распознавания, тогда как Lingvanex сохраняет высокую точность даже при недостатке лингвистических данных. В отличие от WER, оценивающего точность на уровне слов, CER позволяет выявлять даже незначительные ошибки транскрипции, что особенно важно при работе с именами, командами или узкоспециализированной терминологией.
По обеим метрикам — WER и CER — Lingvanex неизменно показывает:
- минимальный уровень ошибок по всем направлениям.
- стабильную работу с разными языками — от распространённых (английский, испанский) до редких (казахский, китайский).
- высокую точность даже в сложных условиях: фоновый шум, перекрывающаяся речь или ограниченные языковые данные.
Lingvanex — единственная система в данном сравнении, разработанная для практического применения, а не просто для демонстрации или работы исключительно с английским языком. Ее стабильные результаты для всех языков, метрик и условий шума доказывают:
Она точна. Она надежна. И она готова к масштабированию — по всему миру.
Lingvanex: адаптивное решение для вашего бизнеса
В отличие от облачных API, работающих только с STT, Lingvanex предоставляет единую платформу для распознавания речи, перевода и других инструментов для работы с текстом и речью — с полной гибкостью развертывания под ваши задачи.
Lingvanex обладает уникальными преимуществами:
- Максимальная гибкость и кастомизация. Возможность адаптировать систему под специфические задачи, включая обучение моделей на доменной лексике и соблюдение строгих требований безопасности.
- Молниеносная обработка данных. Обработка одной минуты аудио занимает всего 3,44 секунды — в разы быстрее большинства аналогов, что существенно повышает эффективность.
- Рост продуктивности сотрудников. Автоматизация распознавания снижает необходимость в расшифровке вручную, позволяя персоналу сосредоточиться на более важных задачах.
- Превосходное взаимодействие с клиентами. Благодаря качественному распознаванию разных акцентов, диалектов, даже при наличии фоновых шумов, обеспечивается более эффективное и приятное общение с клиентами по всему миру.
- Значительное сокращение затрат. Высокая скорость и точность существенно снижают расходы на аутсорсинг расшифровок и ручную обработку аудио.
- Бесшовная интеграция. Надёжные API и SDK обеспечивают быструю интеграцию без дорогостоящей доработки.
- Поддержка множества форматов. Совместимость с WAV, MP3, OGG, FLV и другими форматами гарантирует гибкость в работе с данными.
- Безопасность данных корпоративного уровня. Для организаций, работающих с конфиденциальной информацией, Lingvanex предлагает безопасные варианты локального развертывания, обеспечивающие строгое соблюдение стандартов защиты данных и нормативных требований.
Lingvanex — ваш партнёр в глобальной голосовой инфраструктуре
Голосовые технологии превращаются в ключевой инструмент для международного бизнеса, и это требует новых подходов:
- Традиционные системы распознавания речи не справляются со специализированными задачами.
- Метрики оценки должны учитывать не только точность распознавания слов, но и смысловую составляющую.
- Критически важными параметрами становятся гибкость, защита данных и возможность адаптации под конкретные задачи.
Lingvanex сочетает точность, производительность и гибкость отвечая требованиям предприятий разных отраслей — с беспрецедентной поддержкой многоязычности и реальных сценариев.
Независимо от того, создаете ли вы многоязычный голосовой бот, транскрибируете запись судебных заседаний или анализируете звонки в службу поддержки клиентов, Lingvanex предоставляет вам инструменты для точного, безопасного и масштабируемого распознавания речи.


