
В этой статье мы описываем вызовы, связанные с разработкой мобильной версии системы нейронного машинного перевода. Цель состоит в том, чтобы максимизировать качество перевода при минимизации размера модели. Мы объясняем весь процесс реализации переводческого движка, используя языковую пару английский-испанский в качестве примера. Описываем проблемы, с которыми столкнулись, и решения, которые были реализованы.
Основные методы, использованные в этой работе, включают:
- Выбор данных с использованием восстановления n-грамм;
- Добавление специального слова в конец каждого предложения;
- Генерация дополнительных примеров без финальной пунктуации.

Последние два метода были разработаны для создания модели перевода, которая генерирует предложения без конечной точки или других знаков препинания. Восстановление Редких n-грамм также было использовано впервые для создания нового корпуса, а не только для усовершенствования набора данных в определённой области.
В конечном итоге мы получаем модель малого размера, которая обеспечивает достаточно хорошее качество для повседневного использования.
Подход Lingvanex
L ingvanex — это бренд лингвистических продуктов компании Nordicwise LLC, которая специализируется на оффлайн-переводах и словарных приложениях для мобильных и десктопных платформ. В сотрудничестве с компанией Sciling, которая занимается решениями в области машинного обучения "под ключ", была разработана компактная модель перевода с английского на испанский для мобильных устройств. Основной целью было обеспечение точности перевода в повседневных ситуациях, особенно для путешественников, которые могут не иметь доступа к интернету из-за роуминговых тарифов, отсутствия местных SIM-карт или плохой связи в некоторых районах. Для достижения этой цели проект сосредоточился на минимизации размера модели с использованием методов выбора данных, с целевым размером модели не более 150 МБ.
Были проведены эксперименты для определения ключевых влияющих на размер модели факторов, включая размер словаря, векторные представление слов и архитектуру нейронной сети. Во время реализации возникли несколько переводческих проблем, что потребовало разработки соответствующих решений. Качество полученного продукта было оценено по сравнению с ведущими мобильными переводчиками от Google и Microsoft, что продемонстрировало эффективность финальной модели для практического использования в путешествиях.
Описание данных
Данные, использованные для обучения модели перевода, были получены из корпуса OPUS. Всего было использовано 76 миллионов параллельных предложений. Также мы использовали корпус Tatoeba для набора данных/набора для разработки (DS), описанного в разделе о фильтрации данных. Tatoeba — это поддерживаемая коллективными усилиями бесплатная интернет-база примеров предложений, предназначенная для изучающих языки. Набор для разработки также был создан из корпуса Tatoeba путём выбора 2 тысяч случайных пар предложений. Основные метрики корпуса Tatoeba приведены в таблице 1. В качестве тестового набора мы создали небольшой корпус наиболее часто используемых английских предложений, найденных на различных веб-сайтах. Мы также добавили несколько униграммных и биграммных предложений. В целом было отобрано 86 предложений.
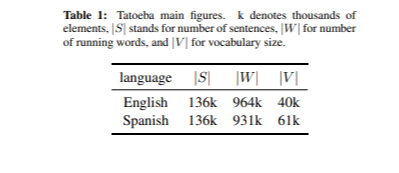
Зависимость от размера модели
При решении задачи уменьшения размера модели основной проблемой является определение гиперпараметров, которые оказывают наибольшее влияние на размер. Перед реализацией системы нейронного машинного перевода (NMT) были проведены эксперименты, сравнивающие размер модели с общим размером словаря и размером векторных представлений слов (Рисунок 1). Были обучены различные модели с варьированием этих гиперпараметров.
В начальном эксперименте рекуррентный слой состоял из 128 единиц с одним слоем как на стороне энкодера, так и на стороне декодера. Общие размеры словарей (V) (исходный и целевой) были уменьшены до разных уровней |V| = {5k, 10k, 20k, 50k и 100k}, основываясь на наиболее частотных словах из корпуса Opus с равномерным распределением между исходным и целевым словарями, при этом размер исходного и целевого словаря был установлен как |V|/2. Кроме того, анализировались различные размеры векторных представлений слов |ω| = {64, 128, 256, 512}.
Затем был исследован эффект различных скрытых единиц и числа слоев, при этом размер векторных представлений был зафиксирован на |ω| = 128. Результаты показали, что количество слоев оказывает минимальное влияние на размер модели, особенно по сравнению с количеством скрытых единиц и размером векторных представлений. Этот анализ предоставляет основу для выбора подходящих значений гиперпараметров при сохранении размера модели в пределах целевого значения 150 МБ.
Фильтрация данных
Фильтрация данных состояла из двух основных этапов. Во-первых, были удалены предложения, длиннее 20 слов, поскольку мобильные переводчики предназначены для перевода коротких предложений. Во-вторых, была выполнена выборка данных с использованием метода Восстановления Редких n-грамм. Эта методика направлена на выбор предложений из доступных двуязычных данных, которые максимизируют покрытие n-грамм в рамках меньшего, специализированного набора данных.
Подход включал сортировку полного набора данных по показателю редкости каждого предложения с целью приоритизации наиболее информативных. Пусть χ представляет собой множество n-грамм в предложениях, которые подлежат переводу, а w — это одна из этих n-грамм. C( w ) обозначает количество w в обучающем наборе исходного языка, а t — пороговое значение для определения, когда n-грамма считается редкой. N( w ) — это количество w в исходном предложении f. Оценка редкости предложения f вычисляется по формуле (1):
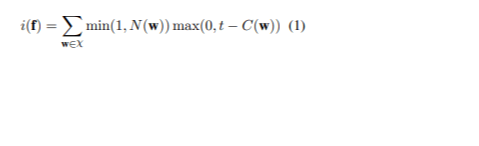
Для 60 миллионов предложений из корпуса Opus было извлечено до 5 n-грамм из корпуса Tatoeba, максимальное количество вхождений каждой n-граммы было установлено на 30. Для управления временем выполнения корпус был разделён на шесть частей, с выполнением выборки отдельно для каждой части перед объединением результатов. В финальном процессе выбора была проведена проверка, чтобы убедиться, что ни одна n-грамма не превышает порог частоты вхождений. В результате этот процесс дал набор данных из 740,000 предложений с размером словаря 19,400 слов на исходном языке и 22,900 слов на целевом языке, что в сумме даёт комбинированный словарь из 42,400 слов. Пример был основан на токенизированном и строковом корпусе.
Экспериментальная настройка
Система была обучена с использованием фреймворка глубокого обучения OpenNMT, который ориентирован на разработку моделей последовательность-в-последовательность для различных задач, включая машинный перевод и суммаризацию. Для выбранного обучающего набора данных была применена методика кодирования пар байтов (BPE), которая затем использовалась для обучения, разработки и тестирования. Для модели использовалась рекуррентная нейронная сеть с долгосрочной и краткосрочной памятью (LSTM), включающая слой глобального внимания для улучшения перевода за счет фокусирования на конкретных частях исходного предложения. Входные данные также использовались для предоставления векторов внимания на последующие временные шаги, однако это имело заметный эффект только при наличии четырех или более слоев.
Обучение проводилось в течение 50 эпох с использованием оптимизатора Adam и коэффициента обучения 0,0002. Лучшая модель была выбрана на основе самого высокого значения BLEU на наборе для разработки и использовалась для перевода тестового набора. Из-за малого размера тестового набора была проведена человеческая оценка качества перевода.
Результат и анализ
Мы обучили различные типы нейронных сетей, основываясь на идеях, изложенных в разделе о зависимости от размера модели. В каждом эксперименте мы настраивали гиперпараметры, сохраняя общий размер словаря фиксированным на уровне 42,4 тыс. слов. Таблица 2 показывает значения гиперпараметров для каждого эксперимента, а также показатели BLEU и размеры моделей.
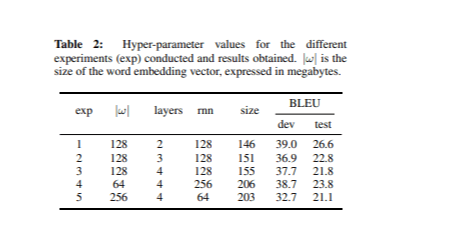
Модель с наилучшими результатами, измеренными по показателю BLEU на наборе для разработки, имела 2 слоя и 128 единиц в рекуррентном слое при размере встраивания 128. Примечательно, что размер этой модели был также минимальным среди перечисленных в Таблице 2.
Обнаруженные проблемы и их решения
Анализ переводов из тестового набора выявил три ключевые проблемы, для каждой из которых были предложены конкретные решения.
1. Проблема повторяющихся слов
Лучшая модель корректно переводила предложения длиной более семи слов, но часто генерировала повторяющиеся слова в очень коротких предложениях (например, "perro perro perro" ). Эта проблема была связана с разницей в длине предложений между обучающими и тестовыми данными, поскольку в обучающем наборе было мало коротких предложений (Рисунок 2).
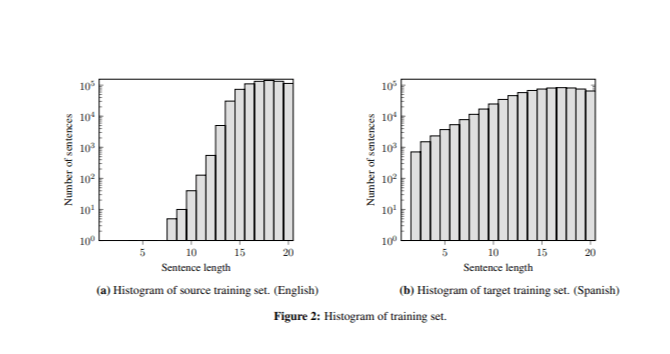
Для смягчения этой проблемы мы скорректировали функцию оценки Восстановления Редких n-грам, добавив шаг нормализации (2).
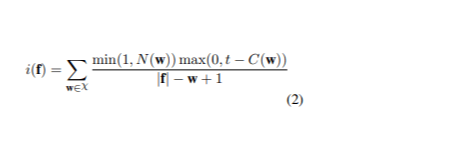
После применения оценки редкости для выбора данных, мы выбрали набор данных из 667 000 предложений. В Таблице 3 показана средняя длина предложений на исходном и целевом языках до и после применения нормализации длины предложений.
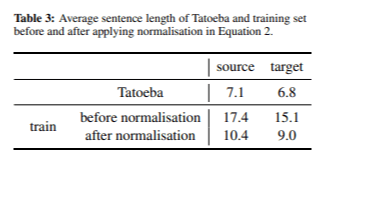
Процесс нормализации позволил нам добиться значительно более коротких предложений как на исходном, так и на целевом языках. Модель достигла значения BLEU 36,3 на этапе разработки и 22,8 на этапе тестирования при общем размере модели 121 МБ. Хотя эти результаты немного ниже, чем в предыдущих экспериментах, мы считаем, что BLEU не всегда является лучшим показателем качества перевода. Ручной анализ подтвердил, что проблема повторяющихся слов была эффективно решена.
2. Ожидание знаков препинания
Модель генерировала некорректные переводы для очень коротких предложений (например, переводила "dog" как "amor"), если не был добавлен знак препинания (например, "dog."). Это было связано с ожиданием модели наличия знака препинания в конце предложения; 94% предложений в обучающем наборе заканчивались знаком препинания. Для решения этой проблемы были предложены два решения:
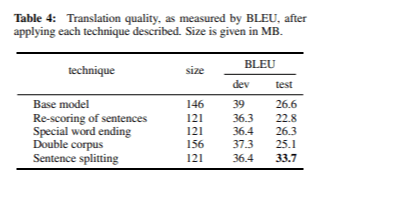
- Специальное окончание слова: Мы добавили специальный токен @@ в конец каждого предложения. Этот подход обучает модель распознавать, что каждое предложение заканчивается на @@, при этом предпоследнее слово может быть как знаком препинания, так и не быть им. Эта техника была реализована как этапы предварительной и постобработки, поэтому она называется специальным окончанием слова. Модель, использующая эту технику, достигла значения BLEU 36,4 на этапе разработки и 26,3 на этапе тестирования после 21 эпохи, при размере 121 МБ.
- Двойной корпус: Мы расширили обучающий корпус, объединив все существующие предложения, которые заканчивались знаками препинания, убрав эти символы. Это позволило модели обучиться, что предложения могут заканчиваться как со знаком препинания, так и без него. В этом случае размер модели увеличился до 156 МБ, при этом модель достигла значения BLEU 37,3 на этапе разработки и 25,1 на этапе тестирования.
Обе методики эффективно решали проблему ожидания знаков препинания.
Однако, из-за большего размера и более низкого значения BLEU стратегии с двойным корпусом, мы решили использовать технику специального окончания слова.
3. Пропущенные сегменты
Было замечено, что при переводе сегментов, содержащих несколько коротких предложений, переводилось только первое из них (например, "Thank you. That was really helpful." становилось "Gracias.").
Для решения этой проблемы был введен этап предварительной обработки для разделения сегментов на основе знаков препинания. Это изменение увеличило количество сегментов с 86 до 118 в тестовом наборе. После этого переводы значительно улучшились, достигнув значения BLEU 36,4 на этапе разработки и 33,7 на этапе тестирования — наивысшего зафиксированного значения на данный момент.
Окончательная оценка
Таблица 4 подводит итоги оценок BLEU, полученных после применения каждого из решений, описанных в разделе "Обнаруженные проблемы и их решения". После применения нормализованного показателя редкости, специального окончания слова и предварительной обработки построенных предложений, мы улучшили качество тестового набора примерно на 7 баллов BLEU.
При окончательной оценке нашей системы перевода мы сравнили её качество с мобильными переводчиками Google и Microsoft. Таблица 5 представляет собой оценки BLEU и размеры моделей для каждого переводчика в тестовом наборе.
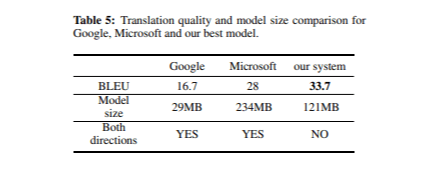
В целом, все три системы продемонстрировали высокое качество перевода, хотя были замечены некоторые незначительные различия. Наша модель особенно хорошо справлялась с знаками препинания и заглавными буквами, в то время как Google Translate часто ошибался в расстановке знаков препинания и редко использовал заглавные буквы. Это может объяснить, почему Google Translate получил более низкую оценку BLEU по сравнению с двумя другими системами, несмотря на меньший размер модели. Кроме того, модели Google и Microsoft являются двусторонними, что означает, что для справедливого сравнения размер нашей модели должен быть удвоен (2 × 121 МБ).
Заключение
В этой статье описан процесс разработки компактной мобильной нейронной системы машинного перевода для английского и испанского языков. Мы использовали метод выбора данных для улучшения качества обучающих данных и внесли коррективы для улучшения качества перевода. Были предложены решения для устранения проблем с повторяющимися словами и отсутствующими переводами в сегментах. Наша модель превзошла мобильные переводчики Google и Microsoft по показателям BLEU, особенно в обработке знаков препинания и заглавных букв. При размере 121 МБ наша модель оказалась меньше, чем первоначально предполагалось, при этом она все еще обеспечивает хорошее качество перевода в контекстах, связанных с путешествиями. Полученные переводы естественны и понятны, подходят для использования в офлайн-режиме. Текущие усилия, включая такие методы, как сокращение веса, направлены на дальнейшее улучшение качества и уменьшение размера модели.


