
Lingvanex разрабатывает решения для машинного перевода уже более семи лет. Каждый месяц мы обрабатываем миллиарды строк данных на более чем 100 языках для обучения языковых моделей, которые демонстрируют исключительные результаты. Но как нам удается поддерживать такой широкий диапазон языков, постоянно улучшая качество перевода месяц за месяцем?
В этой статье мы поделимся результатами наших исследований и инструментами, которые способствуют нашему успеху. Также рассмотрим мощный инструмент, предназначенный для улучшения качества перевода текста. Мы обсудим, как этот инструмент помогает в подготовке данных, обучении моделей перевода и тестировании их производительности. Разбив процесс на этапы, мы постараемся дать четкое представление о том, как перевод языков может быть улучшен с помощью систематических процессов.

Ключевая информация о Data Studio
Data Studio — это инструмент для работы с задачами обработки естественного языка (NLP), который необходим для улучшения качества перевода текста. С помощью Data Studio можно обучать модели перевода, настраивать различные параметры для этих тренировок, токенизировать данные, фильтровать их по различным параметрам, собирать метрики, создавать данные для обучения, тестирования и валидации и многое другое.
Общий процесс создания языковой модели выглядит так:
Предобработка данных: этап подготовки данных перед обучением модели.
Фильтрация с использованием структурных и семантических фильтров.
Сбор общего набора данных: удаление избыточности, равномерное распределение тем и длин, сортировка.
Тегирование для классификации данных.
Загрузка общего набора данных в Data Studio для проверки.
Создание данных для валидации и тестирования модели.
Обучение модели.
Проведение тестов качества: структурные и семантические, измерение метрик.
Обнаружение ошибок в переводах, анализ ошибок в наборах данных, их исправление и дополнение переведенным монокорпусом при необходимости.
Повторение этапа сбора общего набора данных.
Подготовка данных
Для создания языковой модели для перевода текста требуется 3 типа данных:
1) Набор данных для обучения
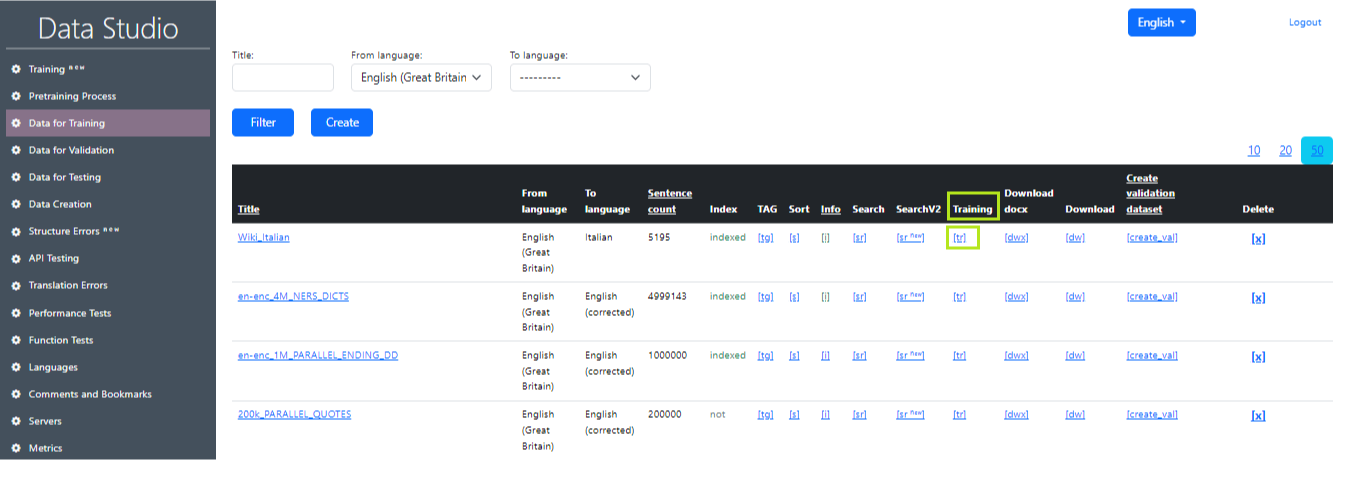
Набор данных, который используется для обучения языковой модели. Это пары предложений на разных языках (исходный и целевой). При обучении модели можно использовать несколько наборов данных одновременно. Важно учитывать согласованность формата и структуры данных, чтобы модель могла правильно использовать информацию из всех обучающих наборов данных. Это рабочее окно отображает подготовленные крупные наборы данных, на которых обучается модель ИИ для перевода. Пример рабочего экрана «Обучающие данные» в Data Studio показан на рис. 1.
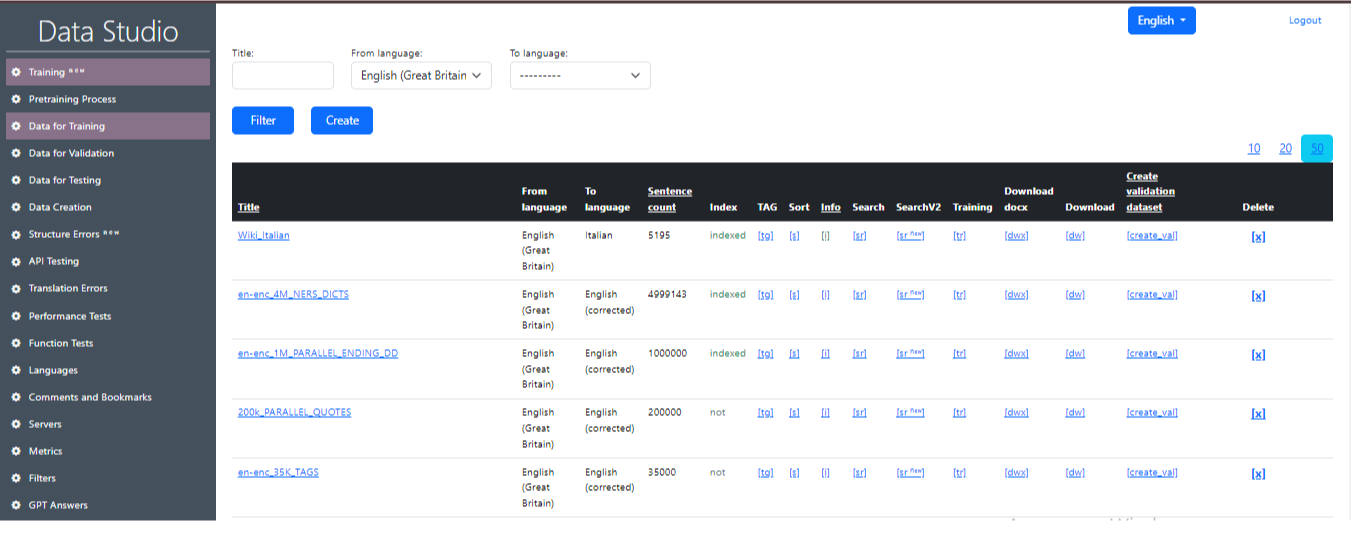
Описание значений в таблице «Обучающие данные»:
- Title: Заголовок, определяющий название записи.
- From language: Язык, с которого выполняется перевод.
- To language: Язык, на который выполняется перевод.
- Sentence count: Количество строк (предложений) в файле.
- Index: Отображает, индексирован ли набор данных (для быстрого доступа к нему).
- Tag: Заменяет определенный процент чисел в наборе данных на <tag>. Это необходимо для логики, которая помечает слова, которые не должны быть переведены (при обучении модели). Процент замены задается в настройках. Когда замена происходит, создается новый набор данных с названием (tag) в конце.
- Sort: Сортирует набор данных по количеству слов в предложении и по алфавиту, чтобы его было удобно анализировать визуально. Когда замена происходит, создается новый набор данных с названием (sorted) в конце.
- Info: Предоставляет информацию о наборе данных.
- Search: Поиск определенных слов и фраз в наборе данных. Эта функциональность необходима для нахождения предложений с неправильным переводом в наборе данных. Например, когда "cat" переведено как "dog".
- Training: Перемещает набор данных на страницу обучения.
- Download: Загружает архив с набором данных на ваш компьютер в формате .txt.
- Download_docx: Загружает архив с набором данных на ваш компьютер в формате .docx.
- Create validation dt: Создает файл валидации из обучающих данных. Параметры задаются в настройках.
- Delete: Удаляет запись.
2) Набор данных для валидации
Этот набор данных используется для оценки производительности модели в процессе обучения. Он помогает оптимизировать параметры модели и предотвращает переобучение, позволяя оценить, как хорошо модель обобщает данные, которых она не видела в процессе обучения.
Например, предположим, что у нас есть предложения на английском языке и их соответствующие переводы на французский. Обучающий набор данных будет содержать эти пары предложений. Модель будет обучаться на этом наборе данных, пытаясь предсказать правильные французские переводы для английских предложений. После обучения модели на обучающих данных мы можем оценить ее производительность на новых данных. Для этого мы используем набор данных для валидации, который также содержит пары английских предложений и их французские переводы. Мы подаем английские предложения из набора данных для валидации в модель и сравниваем её предсказания с реальными французскими переводами из этого набора данных. Это позволяет нам оценить, как хорошо модель обобщает на данные, которых она не видела раньше.
Использование обучающих и валидационных наборов данных помогает создать более точные и обобщенные модели, которые могут эффективно переводить новые предложения на другие языки. Пример рабочего экрана «Валидационные данные» в Data Studio показан на рис. 2.
3) Набор данных для тестирования
Этот набор данных необходим для тестирования качества обученных моделей с использованием файлов, которые в нём хранятся, разделенных по вкладкам. После того как модель и гиперпараметры окончательно настроены с использованием обучающих и валидационных наборов, тестовый набор используется для оценки производительности модели. Пример рабочего экрана «Тестовые данные» в Data Studio показан на рис. 3.
Процесс предварительного обучения
Ранее процессы токенизации и обучения модели выполнялись одновременно, что приводило к неэффективному использованию GPU (аренда серверов оплачивается вне зависимости от того, идет ли обучение модели или нет), пока токенизация не завершалась на CPU. Для оптимизации использования ресурсов был разработан процесс «Предварительного обучения». Теперь токенизация выполняется отдельно от обучения, что позволяет моделям обучаться на GPU без перерывов. Пример рабочего экрана «Процесс предварительного обучения» в Data Studio и одна из вариаций задач pre_trained показаны на рис. 4 и 5.
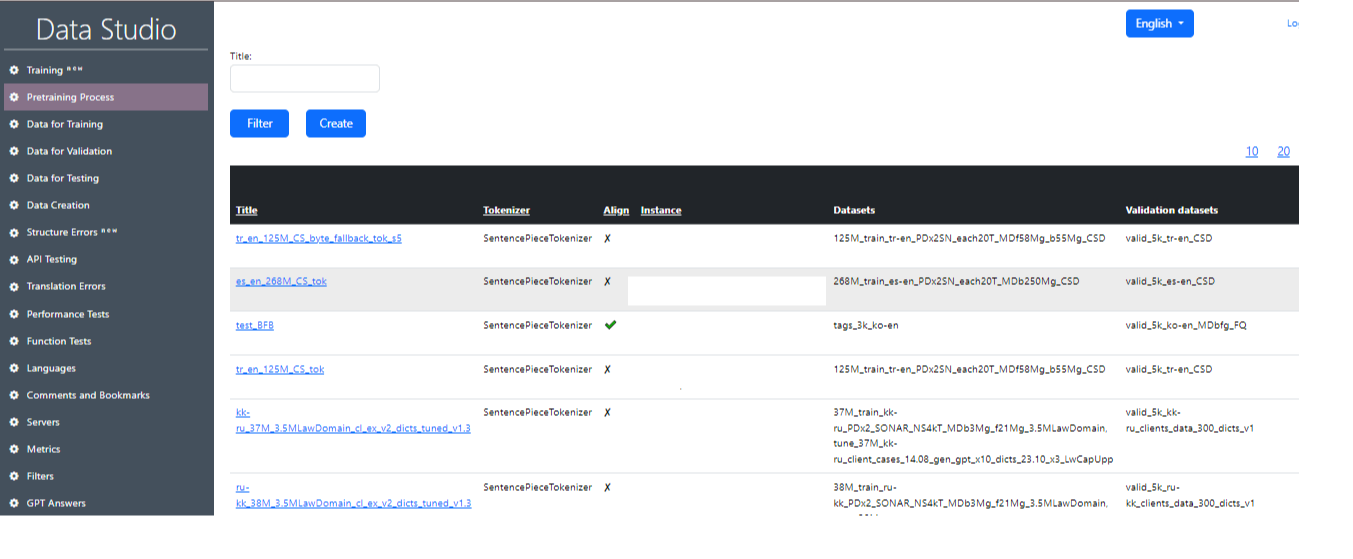
Качество перевода обученной модели зависит от:
- Обучающих данных;
- Установленных параметров для нейронной сети во время обучения;
- Параметров инференса;
- Форматирования текста до подачи его в нейронную сеть (разбиение длинных предложений на короткие фрагменты с последующим склеиванием переводов, приведение различных кавычек и других символов к стандартным).
Процедура проведения «Процесса предварительного обучения»
Для выполнения токенизации необходимо выполнить следующие действия:
Нажмите «Создать» (Create) на главном экране раздела «Процесс предварительного обучения» (рис. 6).

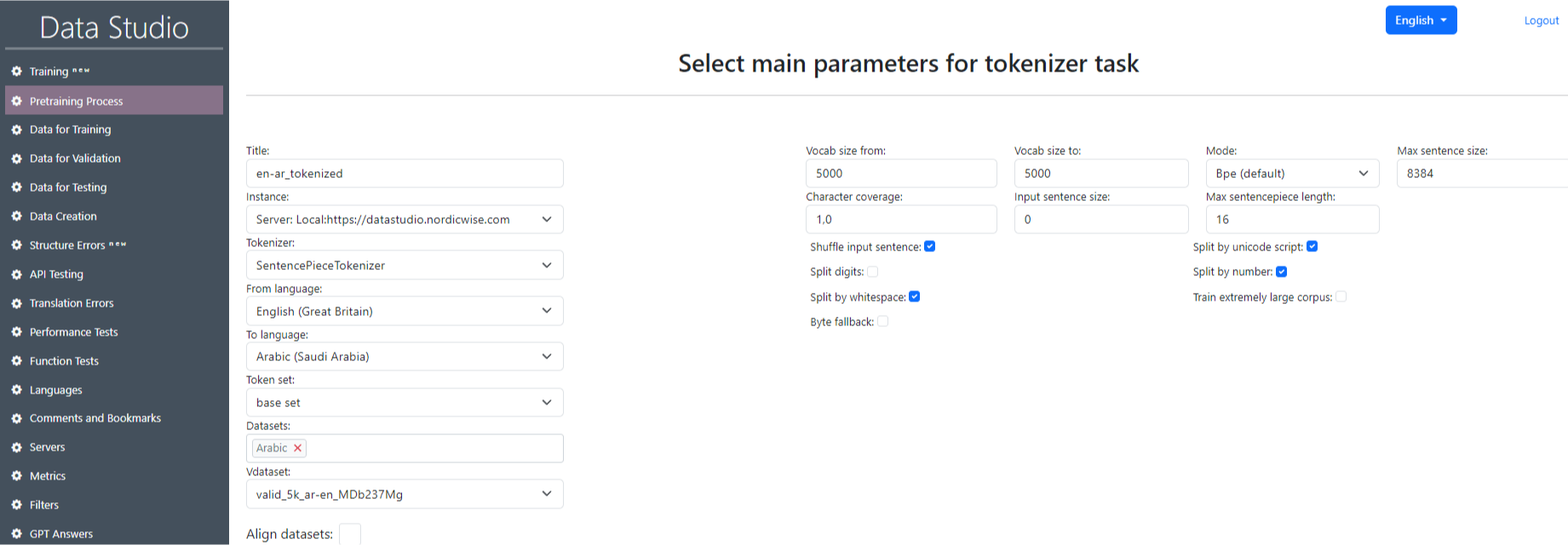
На открывшейся странице «Выберите основные параметры для задачи токенизации» заполните все поля, используя таблицы 3.1 «Параметры токенизации», 3.2 «Параметры токенизации SentencePieceTokenizer» и 3.3 «Параметры токенизации OpenNMTTokenizer». Нажмите «Отправить» (Submit). После этого созданная задача отобразится в таблице на главной странице раздела.
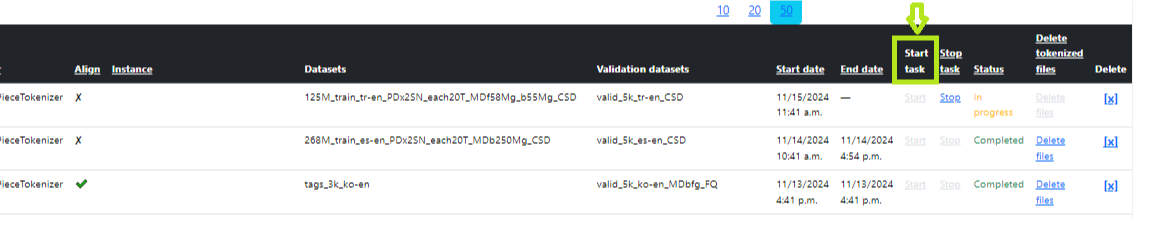
На главной странице раздела найдите созданную задачу и нажмите «Запустить» (Start) напротив нашей задачи (рис. 7 — Запуск токенизации). После запуска статус будет In_queue, немного позже — Started, по завершении — Completed. Вы можете запустить несколько процессов токенизации одновременно. В этом случае после создания нажмите «Запустить» (Start) для каждого процесса. Все задачи будут помещены в очередь и выполняться последовательно одна за другой. После запуска все задачи будут иметь статус «In_queue». После успешного выполнения статус будет последовательно обновляться на Completed. После успешной токенизации набор данных станет доступен для выбора в поле «Данные для предварительного обучения» в разделе «Обучение V2».
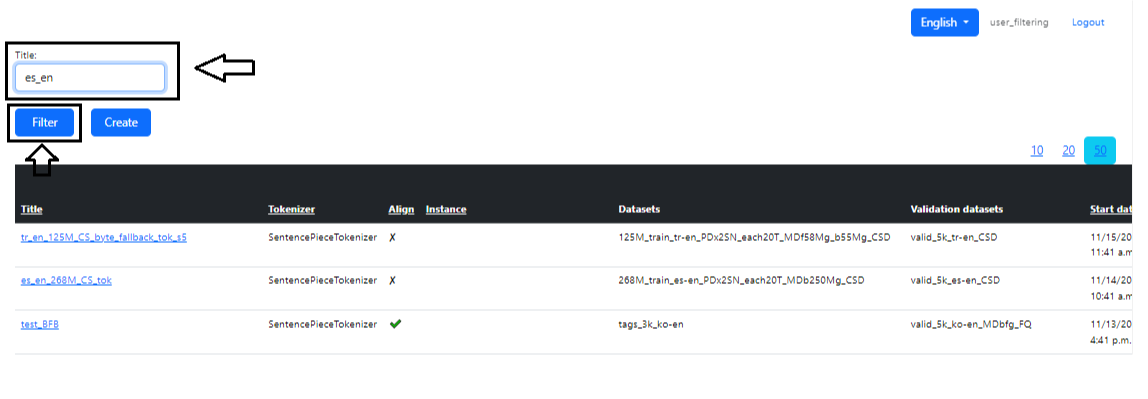
На главной странице раздела есть поиск по нужной задаче. Для этого необходимо ввести название задачи или его часть в поле «Название» и нажать «Фильтр» (Filter). Также можно сортировать данные прямо в таблице, кликнув по названиям колонок (рис. 8 — Поиск).
Чтобы удалить задачу, нужно нажать на крестик в колонке «Удалить» (Delete) напротив задачи, которую необходимо удалить (рис. 9 — Удаление).

Обучение
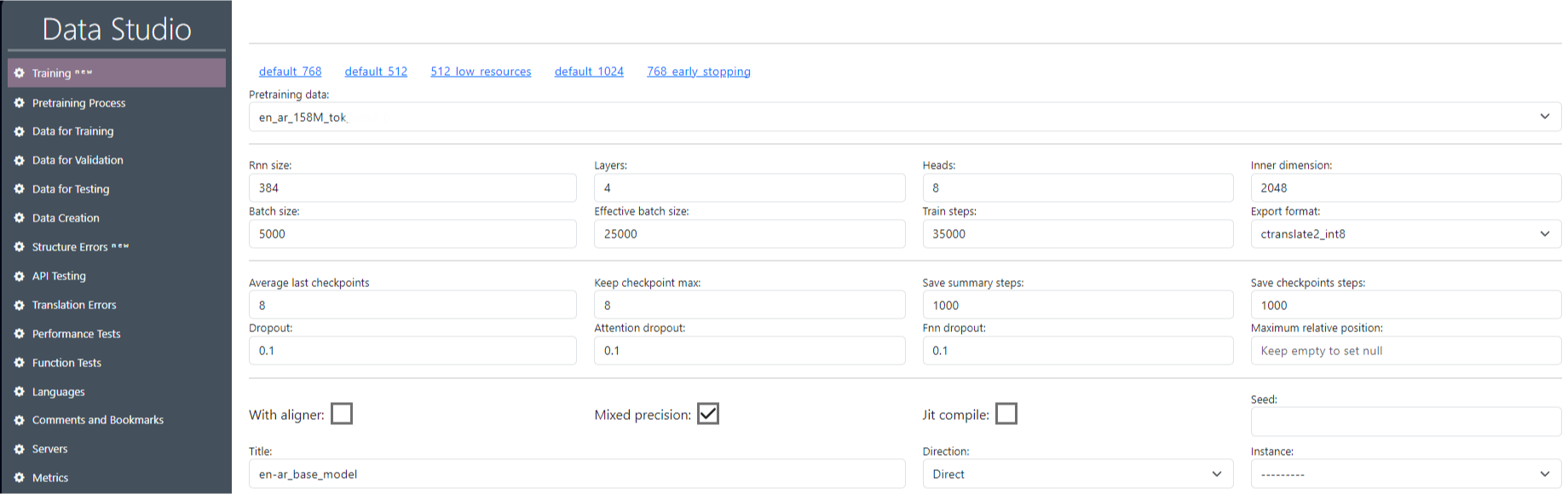
Каждое обучение создает модель для одного направления перевода, например, с английского на французский. Чтобы создать переводчик, например, с русского на английский, необходимо обучить модель в другом направлении. Если мы создаем модель перевода с английского на язык X, то в параметре Direction указываем «Direct», если с языка X на английский, то в параметре Direction указываем «Reverse». Первые и вторые языки не обязательно должны быть английскими, «Direct» просто указывает, что выбор языков From и To осуществляется слева направо. Перед началом обучения необходимо установить параметры для этого обучения (рис. 10).
Чтобы провести обучение модели, необходимо выполнить следующие шаги:
Добавить обучающие данные. Нажмите на «tr» (рис. 11) в строке нужного набора данных в таблице «Обучающие данные». После этого набор данных станет доступен для выбора в разделе «Обучение».
Добавить валидационные данные. Нажмите на «tr» (рис. 12) в строке нужного набора данных для валидации в таблице «Валидационные данные». После этого набор данных для валидации станет доступен для выбора в разделе «Обучение».
В разделе «Обучение» укажите все необходимые параметры (параметры токенизации SentencePieceTokenizer и OpenNMT Tokenizer, а также параметры модели), а также название обучения.
Выберите нужные обучающие и валидационные наборы данных.
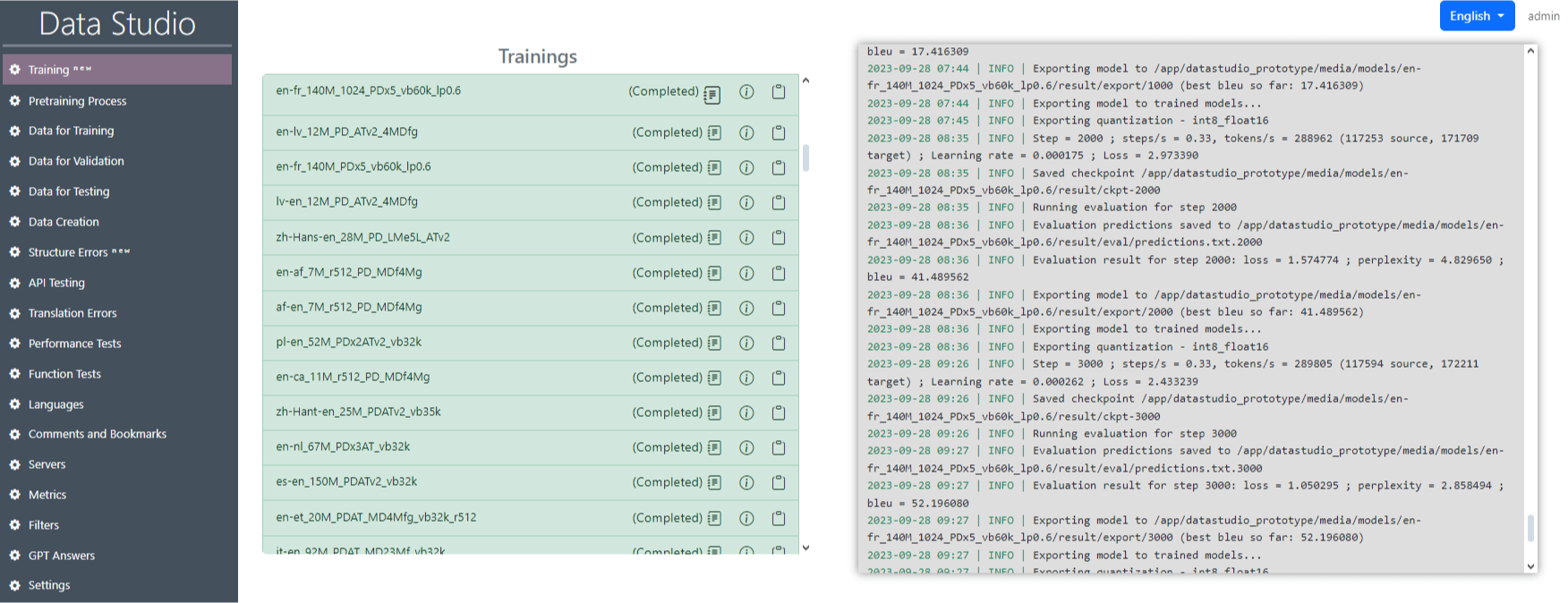
Нажмите на кнопку «Создать и запустить» (Create and run) (рис. 13). После этого начнется обучение, и записи начнут появляться в журнале (рис. 14)

Тестирование
В Data Studio есть два специальных раздела для отслеживания качества перевода: API Testing и Structure Errors. Рассмотрим каждый из них более подробно.
Тестирование API
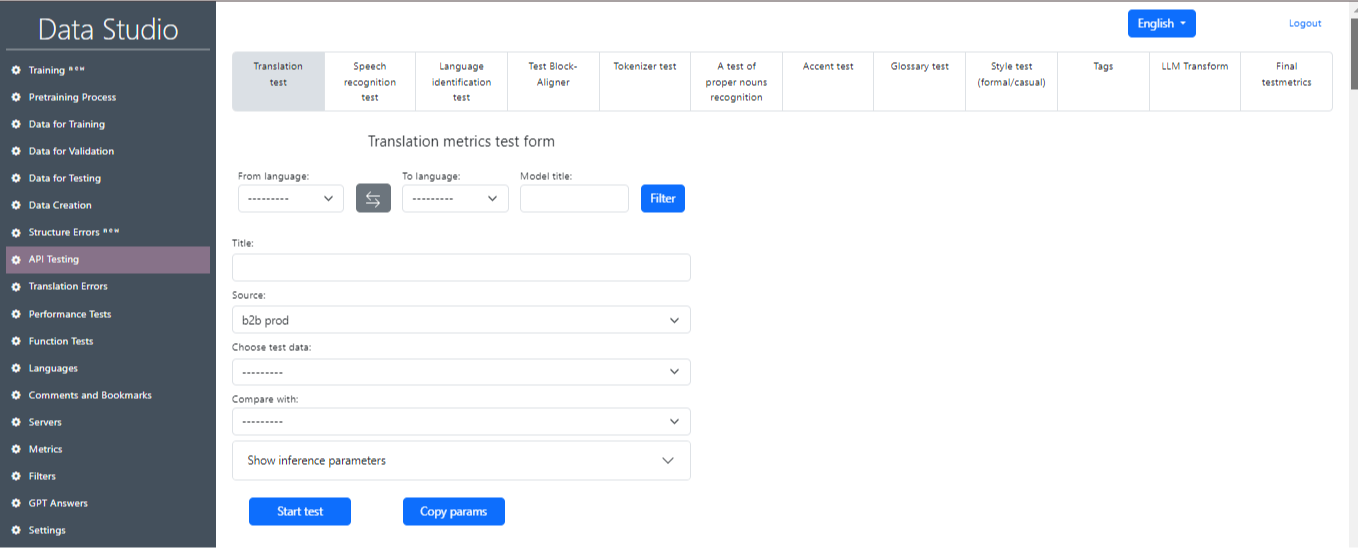
Раздел «Тестирование API» предназначен для проверки обученной модели по таким пунктам, как тест перевода, тест распознавания речи, тест определения языка и другие (рис. 15). Также доступна сводная таблица с итоговыми метриками теста (рис. 16).
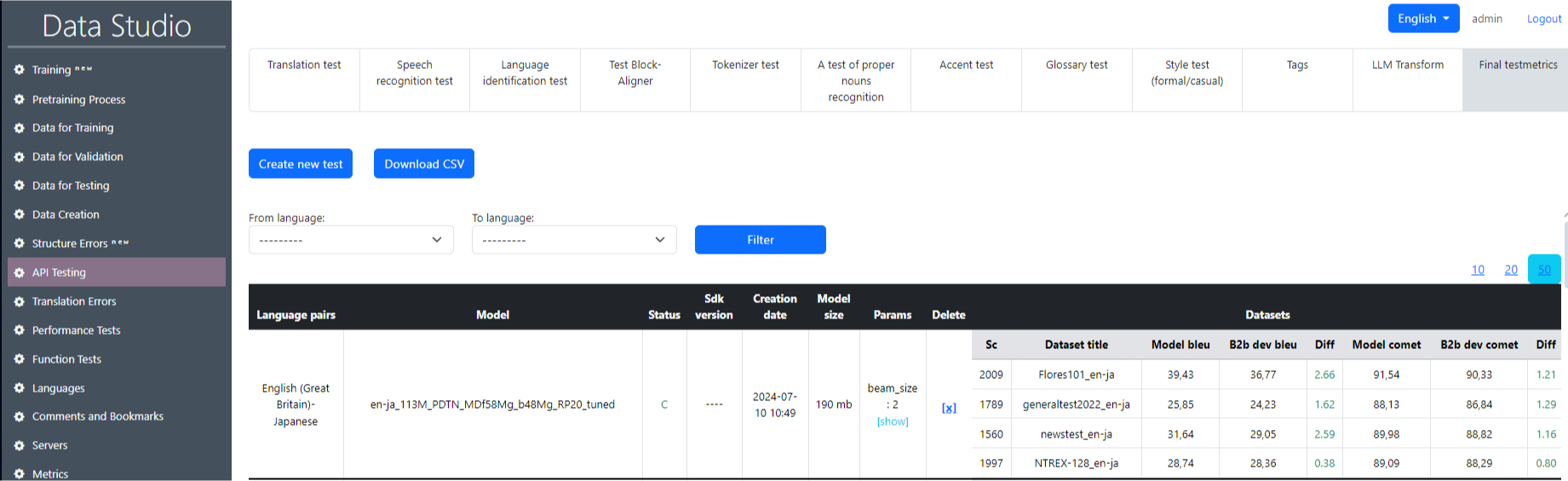
Вот описание того, что представляют собой каждая колонка и метрика в этом разделе:
- Date: Временная метка, когда был выполнен каждый тест.
- From/To Language: Исходный и целевой языки для тестирования перевода.
- Status: Указывает на статус теста перевода (все помечены как Completed).
- Model: Конкретная модель, использованная для перевода (некоторые поля могут быть пустыми, это означает, что модель не указана).
- Test Dataset: Набор данных, использованный для тестирования, например, flores200, ntrex-128 или другие, представляющие собой различные коллекции данных для тестирования перевода.
- Number of Sentences: Количество предложений в тестовом наборе данных.
- Server: Имя сервера, использованного для выполнения теста.
- BLEU: Метрика, оценивающая качество перевода путем сравнения машинного перевода с одной или несколькими эталонными версиями перевода. Более высокие значения BLEU обычно указывают на более высокое качество перевода.
- BLEU ref: Эталонный балл BLEU, возможно, указывающий на идеальный или предыдущий эталонный результат.
- BLEU diff: Разница между текущим значением BLEU и эталонным баллом, отмеченная зеленым (положительная разница) или красным (отрицательная разница).
- COMET: Еще одна метрика качества перевода, более чувствительная к контексту, чем BLEU.
- COMET ref: Эталонный балл COMET.
- COMET diff: Разница в балле COMET относительно эталонного.
- Translation Time: Время, затраченное на выполнение перевода, чаще всего в секундах.
- Delete: Возможность удалить запись о тесте.
Первое различие выводит балл BLEU, второе — балл COMET. BLEU и COMET — это метрики, используемые для оценки качества машинного перевода:
- BLEU: статистическая метрика, измеряющая пересечение n-грамм (последовательностей слов) между машинным переводом и эталонными переводами. Она проста, быстра и широко используется, но не учитывает синонимы или контекст.
- COMET: нейронная метрика, использующая глубокое обучение для оценки перевода, сравнивая исходный текст, эталонный и получившийся после перевода. Она лучше улавливает смысл и контекст, более точно соответствуя человеческой оценке, но является вычислительно затратной.
Файл с результатами тестирования выглядит следующим образом (рис. 17). Интерфейс предоставляет разбивку качества перевода между различными версиями переводов для отдельных предложений в наборе данных.
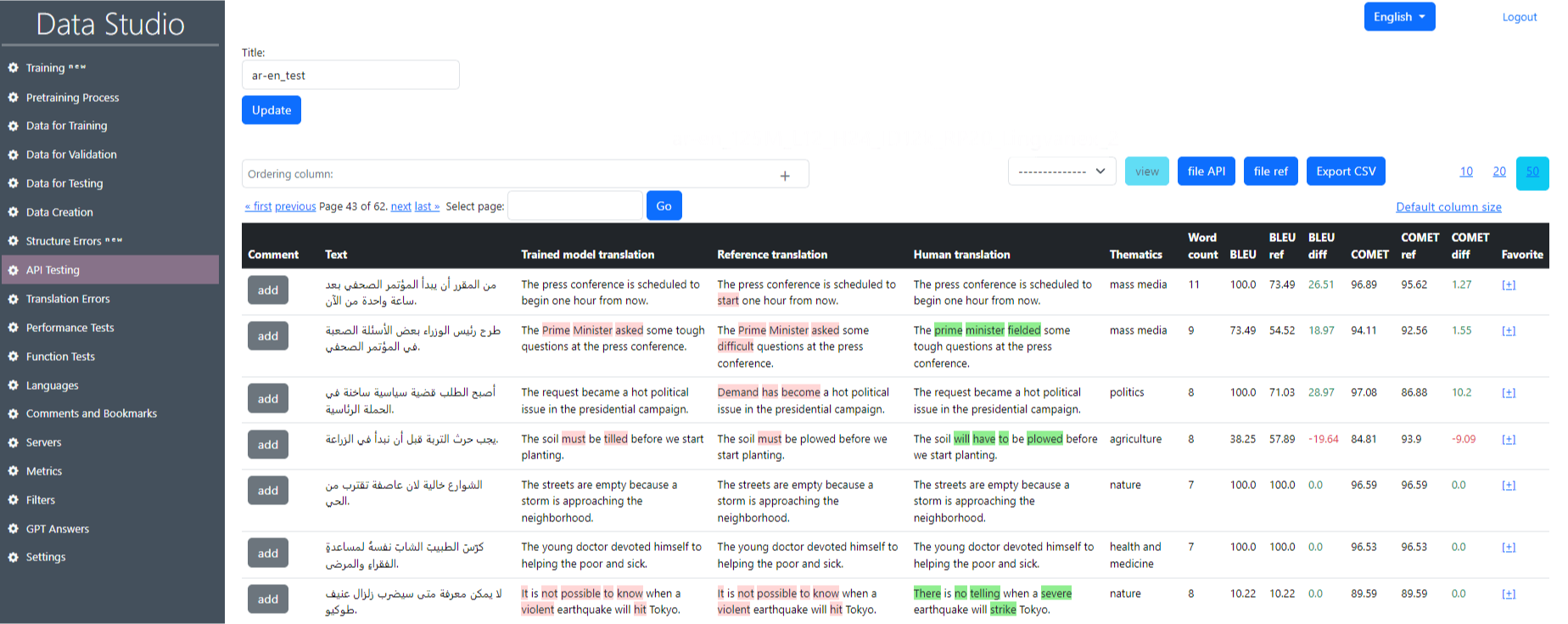
- Comment: Возможность добавить описание или оставить комментарий.
- Text: Исходный текст, который был отправлен на перевод.
- Reference translation: Результат модели API/эталонного файла.
- Human translation: Перевод, выполненный человеком.
- Thematics: Тематика перевода.
- Word count: Количество слов в предложении.
- BLEU: Метрика оценки качества перевода.
- BLEU ref: Эталонная метрика из файла.
- BLEU diff: Разница между метриками BLEU ref и BLEU.
- COMET: Метрика оценки качества перевода.
- COMET ref: Эталонная метрика из файла.
- COMET diff: Разница между метриками COMET ref и COMET.
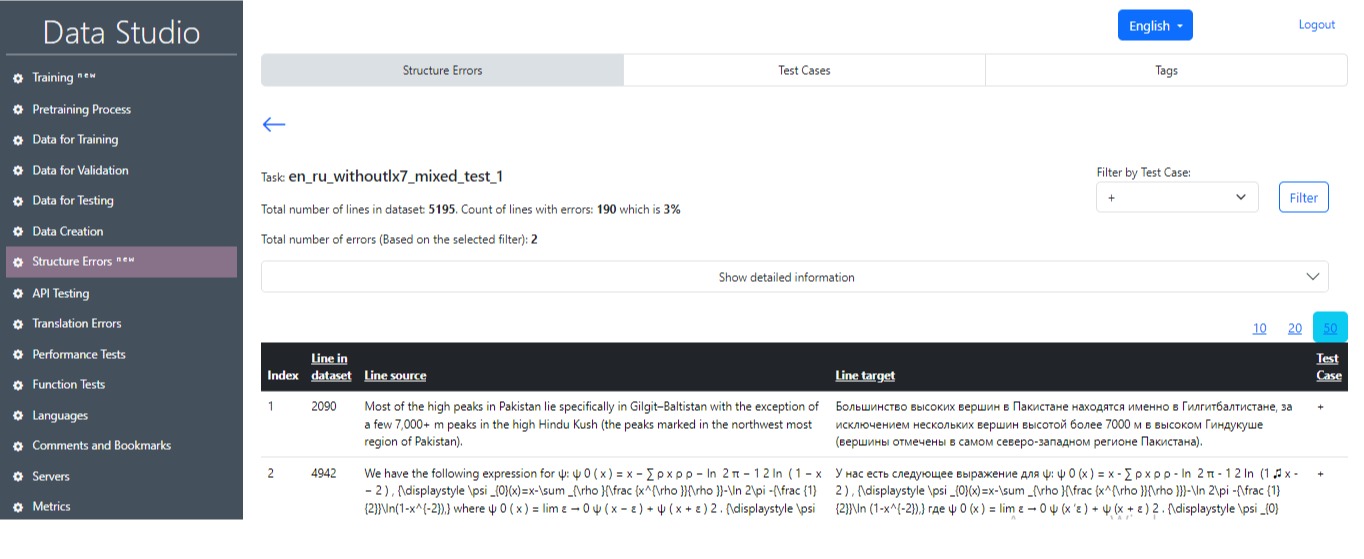
Структурные ошибки
Основная страница раздела «Структурные ошибки» показана на рис. 18 и содержит несколько дополнительных разделов:
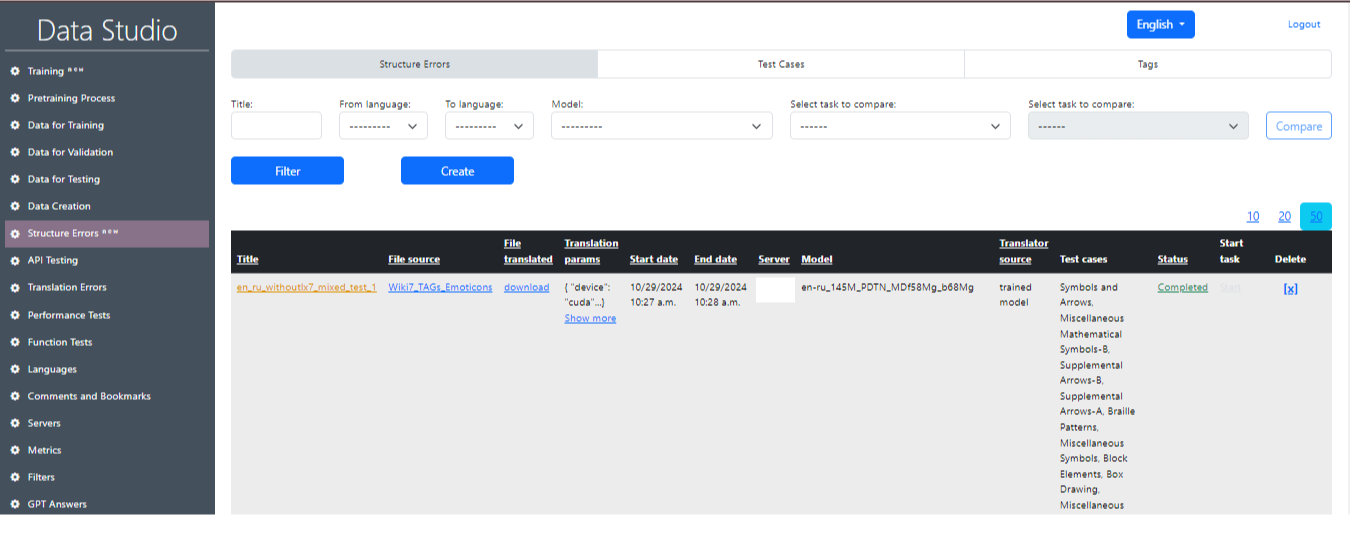
1) Структурные ошибки::
- Title: Это поле позволяет ввести заголовок для структурной ошибки.
- From language: В выпадающем списку можно выбрать исходный язык.
- To language: В выпадающем списку можно выбрать целевой язык.
- Model: В выпадающем списку можно выбрать модель, которая будет использоваться.
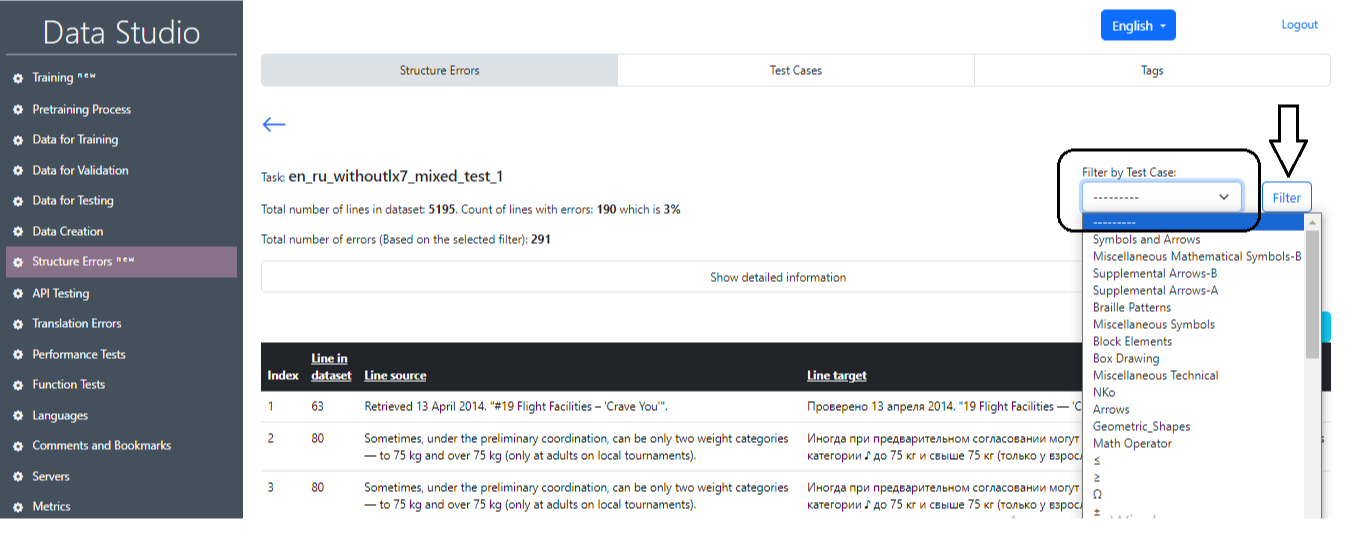
- Select task to compare: Выбор задачи с lx7 и без lx7 для сравнения результатов двух тестов.
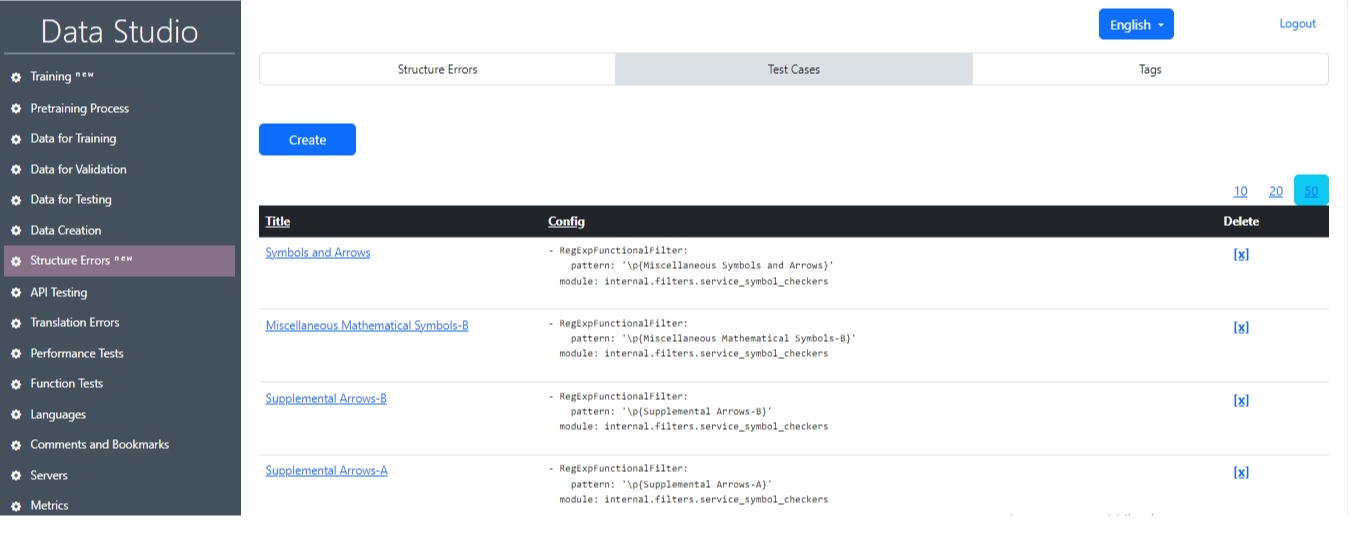
2) Тестовые случаи (рис. 19): Этот раздел отображает тестовые случаи, используемые для нахождения ошибок. Работа этих тестов основана на регулярных выражениях и фильтрах.
3) Теги (рис. 20): В этом разделе пользователь может выбрать конкретную группу тестовых случаев. Эти тестовые случаи сгруппированы по категориям задач, например, Символы, Разное и т.д., или по языкам.
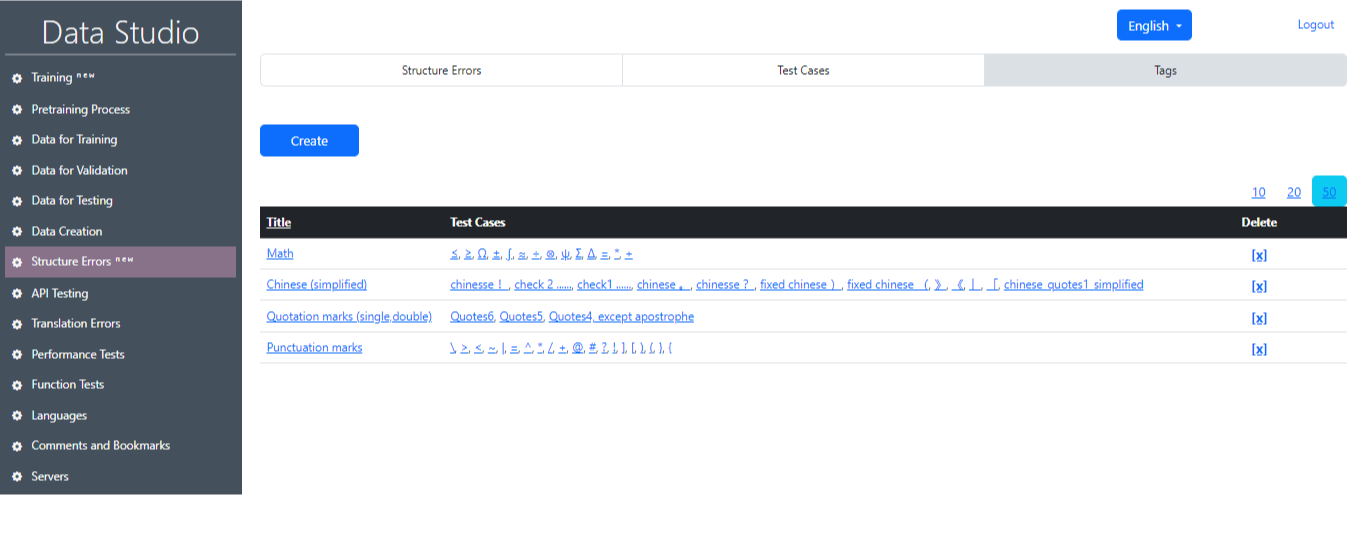
Рис. 21 показывает детализированный вид конкретной задачи перевода в интерфейсе Data Studio. Рассмотрим основные разделы и информацию, представленную в интерфейсе:
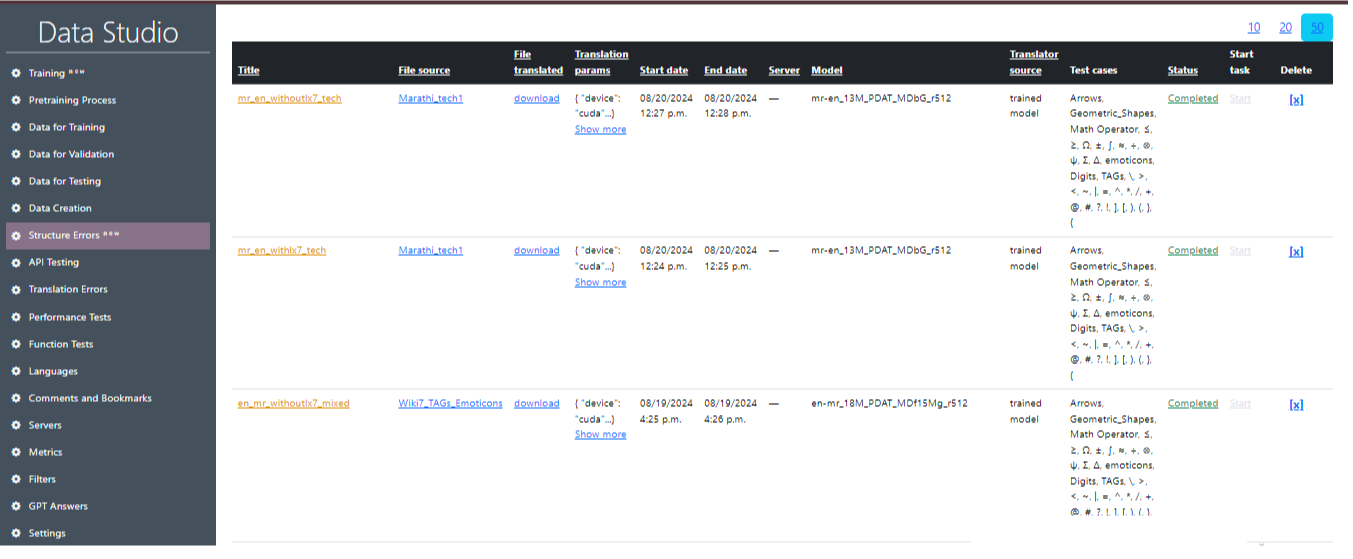
- Title: Отображает название или наименование задачи перевода.
- File source: Показывает источник файла, использованного для перевода.
- Translation Parameters: В этом разделе указаны детали перевода, включая используемое устройство (GUDA или CPU), перевод с lx7 или без, compute_type и beam_size.
- Start date: Информация о дате и времени, когда задача была начата.
- End date: Информация о дате и времени завершения задачи.
- Server: Сервер, который использовался для выполнения задачи
- Model: Модель, которая использовалась для перевода.
- Translation source: Источник перевода.
- Test Cases: Тестовые случаи, использованные в задаче, или группа тестовых случаев.
- Status: Этот блок отображает все завершенные и текущие задачи.
- Start Task: Эта колонка показывает статус задачи перевода.
- Delete: Удаление задачи.
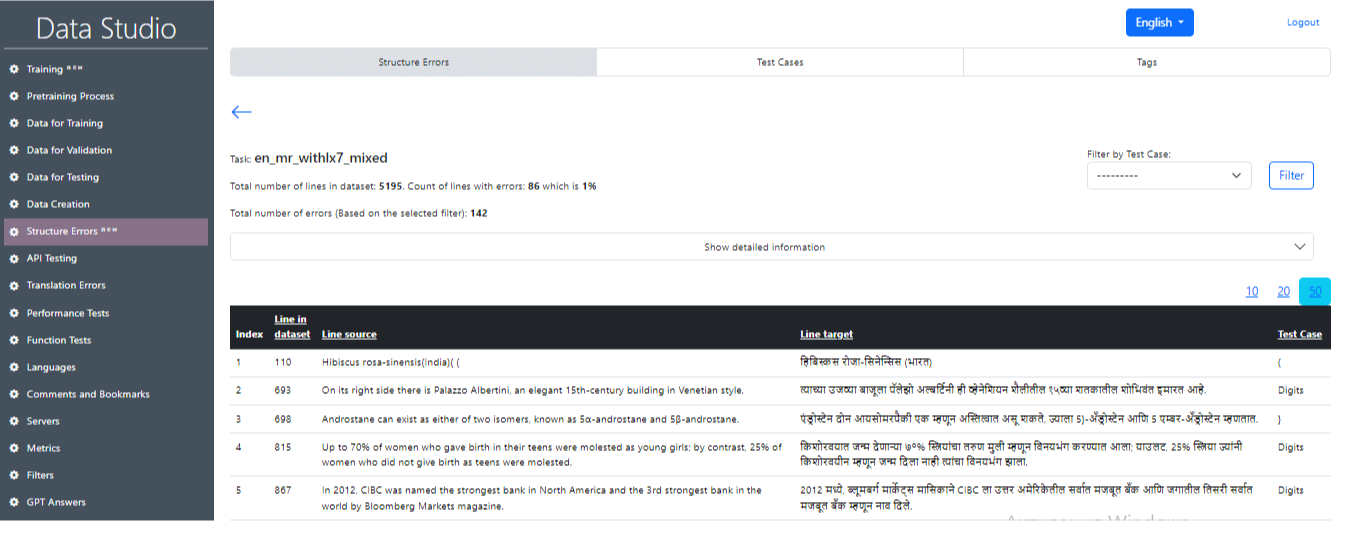
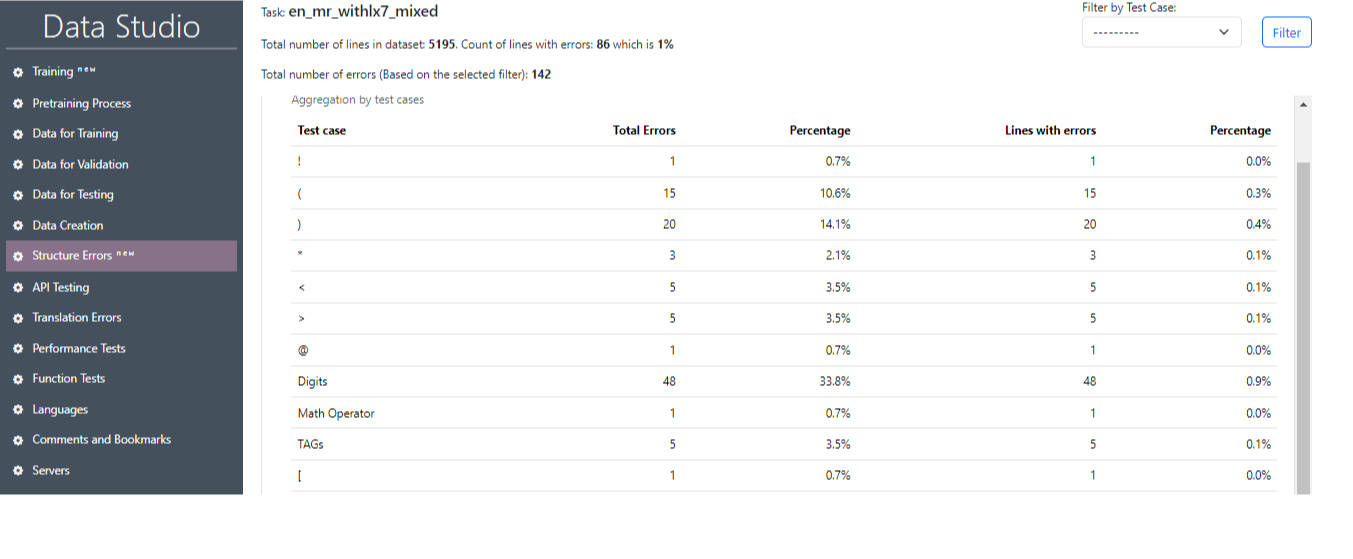
После успешного завершения задачи можно получить основную информацию о результатах тестирования (рис. 22), где будут отображены основные статистические данные (рис. 23), а также номера предложений, содержащих ошибку, и соответствующие тестовые случаи. Также есть возможность выбрать отдельный тестовый случай и предложения с этим тестом, нажав на кнопку «Фильтр» (Filter) (рис. 24, рис. 25).
Заключение
В этой статье мы рассмотрели возможности Lingvanex Data Studio — мощного инструмента, предназначенного для улучшения качества машинного перевода. Обрабатывая большие объемы данных и применяя системные подходы к обучению, валидации и тестированию моделей, мы добиваемся исключительных результатов перевода на широкий спектр языков. Мы обсудили ключевые этапы разработки эффективных языковых моделей, включая подготовку данных, обучение и строгие методологии тестирования. Интеграция обучающих, валидационных и тестовых наборов данных гарантирует, что наши модели не только обучаются эффективно, но и хорошо обобщают данные, с которыми не сталкивались ранее.
Благодаря непрерывным исследованиям и инновационным инструментам, которые находятся в нашем распоряжении, мы продолжаем совершенствовать процессы перевода, улучшая точность и производительность с каждым месяцем.


