
В современном быстро меняющемся цифровом мире технологии распознавания речи становятся важным фактором. Они трансформируют способы коммуникации и наше взаимодействие с устройствами. С развитием приложений, от виртуальных ассистентов Siri и Alexa до передовых сервисов транскрипции, понимание особенностей различных систем распознавания речи становится критически важным.
В этой статье рассматривается технология локального распознавания речи Lingvanex, которая позволяет обрабатывать устную речь непосредственно на серверах организаций. Это безопасная и эффективная альтернатива облачным решениям отвечает уникальным потребностям предприятий. Ключевые особенности включают поддержку 91 языка, возможность настройки терминологии под отраслевые требования и быструю обработку аудио, значительно сокращающую время транскрипции.
Кроме того, статья исследует, как эта технология может быть полезна в различных отраслях, от повышения производительности сотрудников и улучшения взаимодействия с клиентами до обеспечения конфиденциальности данных. На примере анализа языковых моделей, особенно для менее распространенных языков, демонстрируется эффективность Lingvanex в таких секторах, как поддержка клиентов и образование. Внедрение системы Lingvanex предоставляет организациям ряд преимуществ для оптимизации процессов распознавания речи.

Краткий обзор технологии локального распознавания речи Lingvanex
Локальное распознавание от Lingvanex — это технология, которая позволяет организациям обрабатывать и анализировать устную речь локально, используя собственные серверы, а не полагаясь на облачные решения. Lingvanex предлагает систему распознавания речи на месте, разработанную с учетом специфических потребностей предприятий, предоставляя надежный и безопасный способ обработки речевых данных.
Ключевые особенности локального распознавания речи Lingvanex:
- Широкая поддержка языков. Система Lingvanex поддерживает 91 язык, что позволяет организациям транскрибировать и переводить устный контент с учетом различных языковых потребностей.
- Гибкость и настройка. Мы предоставляем возможность настройки системы для удовлетворения уникальных потребностей бизнеса, включая возможность адаптации моделей под отраслевую терминологию и протоколы безопасности.
- Сокращение времени обработки. Lingvanex значительно ускоряет обработку аудиоданных, обрабатывая одну минуту аудио всего за 3,44 секунды, что гораздо быстрее, чем многие конкурирующие решения.
- Улучшение клиентского опыта. Lingvanex улучшает взаимодействие с клиентами по всему миру, точно распознавая различные акценты и диалекты, а также позволяя обрабатывать записи с несколькими говорящими в сложных и шумных условиях.
- Экономия на обработке данных. Быстрая обработка и высокая точность Lingvanex сокращают затраты на аутсорсинг транскрипции и другие задачи ручной обработки голосовых данных.
- Бесшовная интеграция в бизнес-процессы. Lingvanex легко интегрируется в существующие системы через API и SDK, обеспечивая быструю реализацию без необходимости в масштабных разработках или изменениях.
- Поддержка множества форматов данных. Lingvanex совместим с различными аудиоформатами, включая такие популярные, как WAV и MP3, а также более специализированные форматы, такие как OGG и FLV.
- Конфиденциальность и безопасность данных. Для компаний, работающих с чувствительной информацией, Lingvanex предлагает локальные решения, которые полностью соответствуют нормативным требованиям по защите данных. Организации могут обрабатывать конфиденциальные документы в оффлайн-режиме, минимизируя риск утечки данных, поскольку информация не передается за пределы инфраструктуры компании.
- Безлимитная транскрипция. Организации могут воспользоваться неограниченными возможностями транскрипции за фиксированную ежемесячную плату, начиная с €400. Эта ценовая модель позволяет использовать систему в полном объеме без дополнительных затрат на основе объема данных.
Обзор производительности локального распознавания речи Lingvanex
Это исследование было проведено с целью сравнения производительности перевода различных языковых моделей для нескольких языковых пар, а именно: английский, испанский, португальский, французский, немецкий, арабский.
Для оценки качества перевода использовались два ключевых показателя: показатель ошибки слов (WER) и показатель ошибки символов (CER). WER измеряет количество неправильных слов в переводе по сравнению с исходным текстом и выражается в процентах. Чем ниже WER, тем точнее система распознает речь. CER, в свою очередь, оценивает точность перевода на уровне символов, также выраженную в процентах. Более низкий CER означает, что система более точно распознает речь. Оба показателя дают представление о производительности языковых моделей.
Для английского языка модель tuned_small достигла WER 9% и CER 4%, в то время как модель large-v3 имела WER 58% и CER 44,5%. Это дает разницу в 49% для WER и 40,5% для CER.
Для испанского языка модель tuned_small показала лучшие результаты с WER 11% и CER 5%, в то время как у модели large-v3 WER составил 68%, а CER — 45%, что означает разницу в 57% и 40% соответственно.
Во французском языке модель tuned_small показала WER 10% и CER 5%, в то время как у модели large-v3 WER составил 60%, а CER — 38,5%, что дает разницу в 50% и 22,5%.
Для немецкого языка модель tuned_large достигла WER 28% и CER 30%, по сравнению с WER 57,8% и CER 30% у модели large-v3, что указывает на разницу в 28% для WER и отсутствие разницы для CER.
Для арабского языка модель large-v3 показала WER 4% и CER 52%, в то время как модель tuned_large-v2 имела WER 4% и CER 2,2%, что приводит к разнице в 0% для WER и 49,8% для CER.
Наконец, для португальского языка модель tuned_large-v2 показала WER 10% и CER 35,3%, в то время как у модели large-v3 WER составил 51,86%, а CER — 26%, что дает разницу в 41,86% для WER и 9,3% для CER.
В целом, анализ показал различные уровни производительности среди протестированных моделей и языков, при этом модели tuned_small и large-v3 демонстрируют заметные различия в WER и CER. Это свидетельствует о том, что настройка модели значительно улучшила производительность, что в конечном итоге привело к высококачественному распознаванию речи для таких редких языков.
Ниже представлены таблицы с результатами по показателю WER (показатель ошибки слов) и CER (показатель ошибки символов) для шести языков (испанский, португальский, французский, немецкий, арабский и английский). В колонке «Разница» показана разница в производительности между моделью large-v3 и соответствующей настроенной моделью.
Таблица 1: Показатель ошибки слов (WER%)
| Язык | Настроенная модель | WER (%) Tuned | WER (%) Large-v3 | Разница |
|---|---|---|---|---|
| Английский | tuned_small | 9 | 58 | 49 |
| Испанский | tuned_small | 11 | 68 | 57 |
| Французский | tuned_small | 10 | 60 | 50 |
| Немецкий | tuned_large | 8 | 36 | 28 |
| Арабский | large-v3 | 4 | 52 | 48 |
| Португальский | tuned_large-v2 | 10 | 32 | 22 |
График 1 - Сравнение частоты ошибок в словах (WER)
нижние столбцы = лучшая производительность
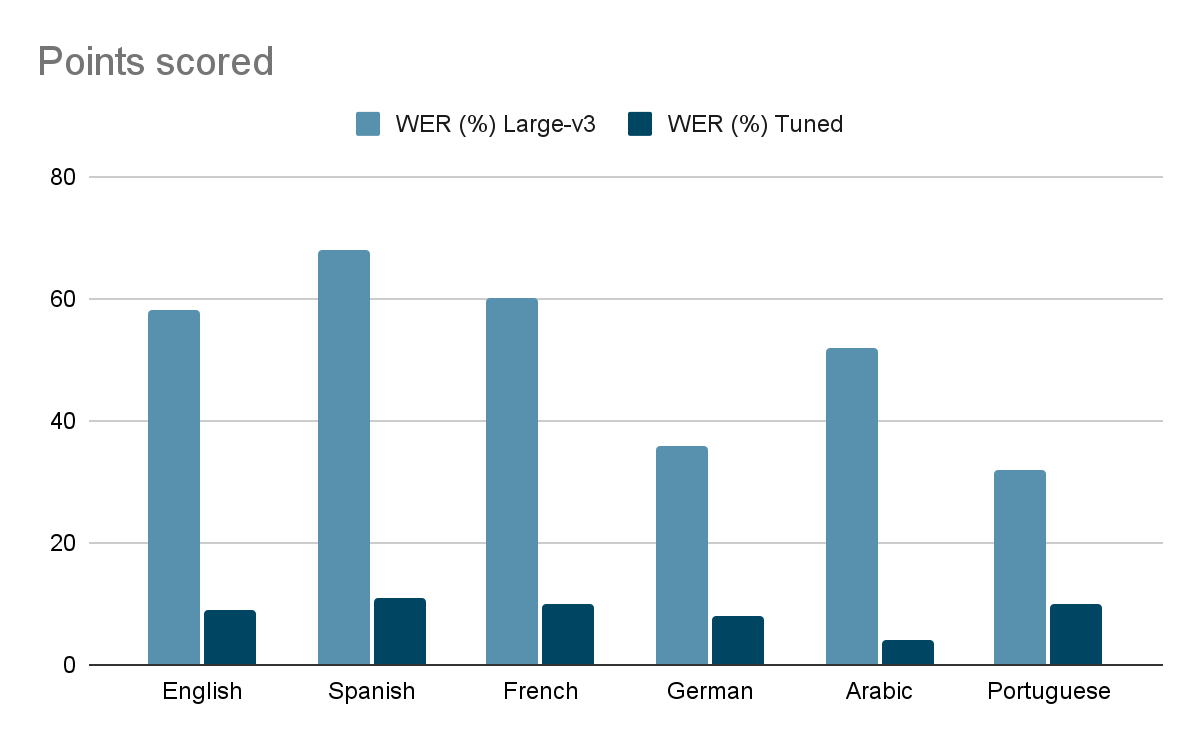
Таблица 2: Показатель ошибки символов (CER%)
| Язык | Настроенная модель | CER (%) Tuned | CER (%) Large-v3 | Разница |
|---|---|---|---|---|
| Английский | tuned_small | 4 | 44,5 | 40,5 |
| Испанский | tuned_small | 5 | 45 | 40 |
| Французский | tuned_small | 5 | 38,5 | 22,5 |
| Немецкий | tuned_large | 3 | 30 | 28 |
| Арабский | large-v3 | 4 | 25 | 21 |
| Португальский | tuned_large-v2 | 4 | 35,3 | 31,3 |
График 2 - Сравнения частоты ошибок в символах (CER)
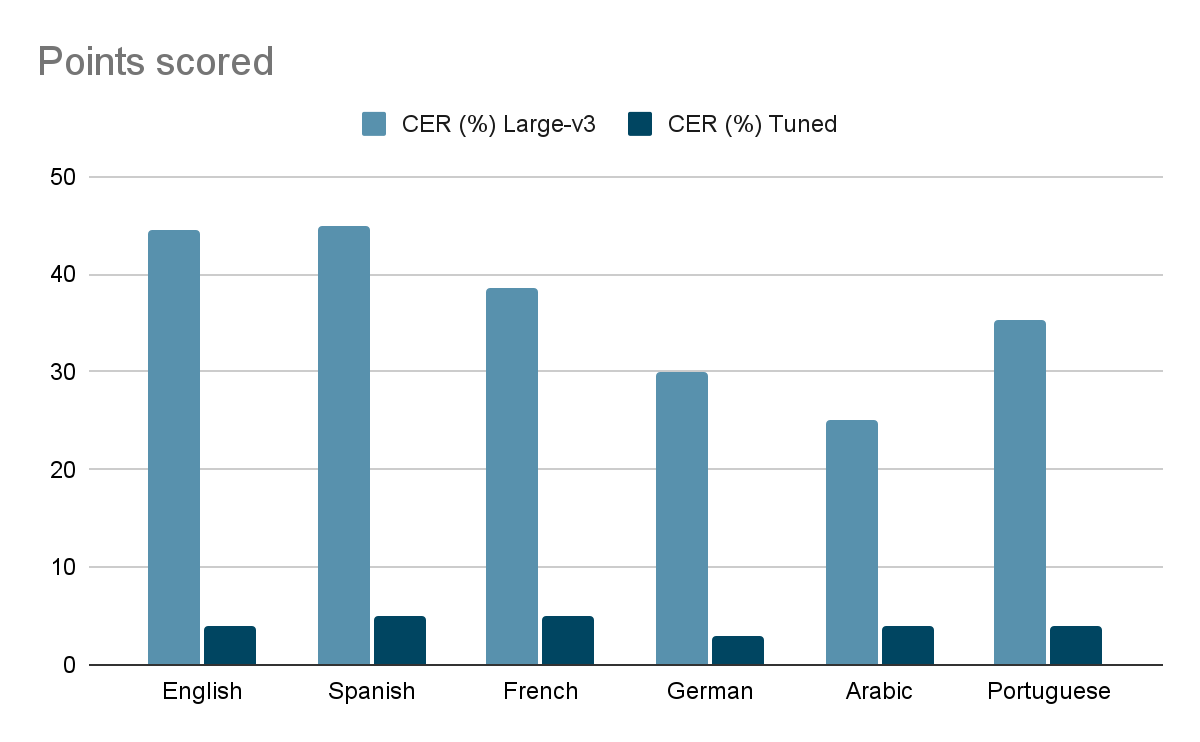
нижние столбцы = лучшая производительность
Тестирование от Lingvanex
Когда речь идет о распознавании речи, точность и адаптивность имеют ключевое значение. Представленная диаграмма демонстрирует высокую производительность наших моделей, сравнимую с ведущими конкурентами на рынке, такими как Google, Microsoft, Amazon и Yandex. Тестирование проводилось на реальных данных для нескольких языков: английский, испанский, французский, немецкий, арабский и португальский.
Сравнение результатов частоты ошибок в словах(WER)
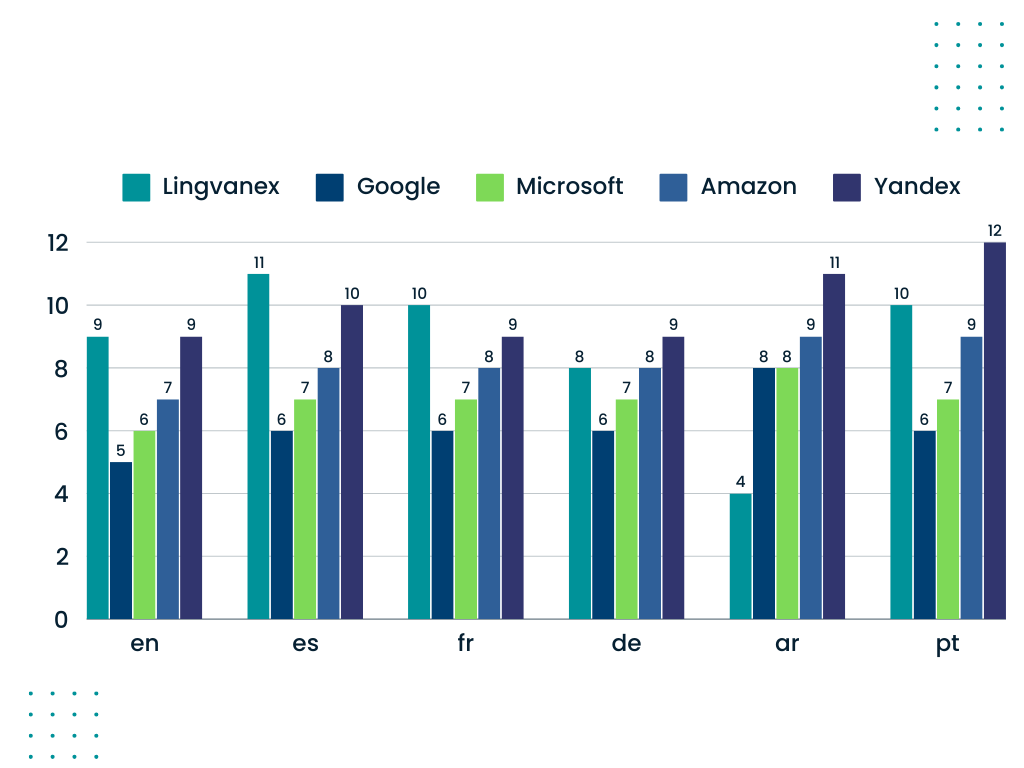
Сравнение результатов частоты ошибок в символах (СER)

Диаграмма показывает результаты тестирования с использованием готового решения Lingvanex. Уже на этом этапе система демонстрирует высокий уровень точности перевода и обработки текста, что делает ее эффективной для решения широкого круга задач.
В отличие от универсальных решений, наши модели разрабатываются с учетом возможности настройки. Мы настраиваем систему распознавания речи под уникальные требования клиентов, обеспечивая результаты, соответствующие контексту специализированных областей, таких как здравоохранение, финансы и образование. Наши решения более экономичны при сохранении высококлассной производительности, что делает наше предложение доступным без потери ценности. Благодаря этой настройке система Lingvanex может дополнительно повышать продуктивность, адаптируясь к стилистическим, терминологическим и лексическим предпочтениям клиента. Такой персонализированный подход позволяет повысить точность распознавания речи и улучшить восприятие финального текста, делая Lingvanex незаменимым инструментом для компаний, работающих в специализированных областях.
Примеры использования
Локальное распознавание речи Lingvanex предлагает универсальное решение для различных отраслей. Технология улучшает продуктивность и доступность, предоставляя надежные услуги транскрипции, адаптированные к уникальным потребностям различных секторов. Вот несколько примеров того, как Lingvanex может повысить эффективность операций, упростить взаимодействие и способствовать инновациям:
- Поддержка клиентов. Компании могут использовать Lingvanex для транскрибирования звонков и чатов службы поддержки, что позволит лучше анализировать отзывы клиентов и улучшать обслуживание. Способность системы распознавать различные акценты и диалекты обеспечивает эффективное общение.
- Создание контента для маркетинга. Маркетологи могут записывать сессии мозгового штурма и транскрибировать их с помощью Lingvanex, генерируя новые идеи для контента. Это может привести к более креативным кампаниям, основанным на спонтанных обсуждениях.
- Образование и электронное обучение. Образовательные учреждения могут использовать Lingvanex для транскрибирования лекций и семинаров, делая контент более доступным для студентов. Технология также может помочь в добавлении субтитров к онлайн-курсам, улучшая обучение.
- Определяйте и классифицируйте эмоции и мнения в отзывах клиентов. Lingvanex может транскрибировать отзывы клиентов из звонков или опросов, позволяя компаниям анализировать тенденции настроений с течением времени. Эта информация может помочь в разработке продуктов и улучшении обслуживания клиентов.
- Доступность для сотрудников с нарушениями слуха. Компании могут использовать Lingvanex для предоставления транскрипций встреч и презентаций в реальном времени, обеспечивая возможность полноценного участия сотрудников с нарушениями слуха в рабочих обсуждениях.
- Многоязычное общение в глобальных командах. В международных компаниях Lingvanex может транскрибировать и переводить разговоры в реальном времени, помогая командам работать более эффективно, несмотря на языковые барьеры.
- Мониторинг социальных сетей. Компании могут анализировать разговоры клиентов на платформах социальных сетей, транскрибируя аудио или видео контент. Это позволяет лучше понять общественное мнение и тенденции, связанные с их брендом.
Почему стоит выбрать Lingvanex?
С семилетним опытом работы, Lingvanex ставит в приоритет качество и инновации. Вот несколько ключевых особенностей нашей компании:
- Постоянная техническая поддержка. Наша команда специалистов всегда готова помочь вам с любыми проблемами или вопросами. Это гарантирует эффективную обработку ваших запросов на перевод, экономя ваше время и усилия.
- Непрерывное обучение моделей. Lingvanex стремится к постоянному совершенствованию. Мы регулярно обновляем и улучшаем наши модели перевода с использованием новейших технологий. Этот процесс постоянного развития дает более точные переводы.
- Опытные профессионалы. Наши лингвисты не только многозначны, но и обладают специализированными культурными знаниями. Это знание позволяет нам учитывать технические термины, нюансы и культурный контекст в наших переводах.
- Система обратной связи. Мы активно собираем отзывы от наших пользователей, что играет ключевую роль в улучшении наших услуг. Это позволяет нам вносить изменения в процессе обучения моделей, чтобы они соответствовали их потребностям и предпочтениям.
- Передовая технология распознавания речи. Использование передовых алгоритмов распознавания речи и обширной базы данных позволяет нам обеспечивать точность распознавания, учитывая не только лингвистику, но и контекст.
Заключение
Технология распознавания речи Lingvanex предлагает компаниям мощное решение для безопасной и эффективной обработки речи. Поддерживая 91 язык и предоставляя настраиваемые параметры, она повышает продуктивность, улучшает взаимодействие с клиентами и обеспечивает конфиденциальность данных. Возможность бесшовной интеграции в существующие системы и быстрая транскрипция делают ее идеальным выбором для различных отраслей. При выборе системы распознавания речи компании должны учитывать множество факторов: от точности и устойчивости к шуму до поддержки нескольких языков и гибкости интеграции. Если вы хотите улучшить ключевые процессы на основе голосовых данных и получить реальные результаты, а не теоретические обещания, Lingvanex станет вашим надежным партнером.


