
При оценке качества машинного перевода важно не только сравнить результаты различных систем перевода, но и проверить, являются ли обнаруженные различия статистически значимыми. Это позволяет оценить, насколько полученные результаты достоверны и могут ли они быть применимы к другим наборам данных.
В данной статье рассматриваются две наиболее распространенные метрики для оценки качества перевода — BLEU и COMET. Также проводится анализ того, как проверить статистическую значимость различий между двумя системами перевода, используя эти метрики.

Статистическое значение BLEU и COMET
BLEU (Bilingual Evaluation Understudy) – это метрика, которая измеряет качество перевода, сравнивая n-граммы переведенного текста с n-граммами эталонного (человеческого) перевода. Согласно исследованию «Yes, We Need Statistical Significance Testing», чтобы утверждать, что улучшение BLEU-метрики по сравнению с предыдущими результатами является статистически значимым, разница должна превышать 1.0 балл BLEU. Если же рассматривать «высокозначимое» улучшение (p-value < 0.001), то разница должна составлять 2.0 балла BLEU или более.
Еще одна широко применяемая метрика, COMET (Crosslingual Optimised Metric for Evaluation of Translation), использует методы машинного обучения для оценки качества перевода относительно эталонного. По данным исследований, различие в пределах 1–4 баллов может оказаться статистически незначимым, что объясняется погрешностью измерений. Даже разница в 4.0 балла может быть недостаточной для статистической значимости.
Эти результаты имеют важное практическое значение для разработчиков систем машинного перевода. Простое сравнение числовых значений метрик может привести к ошибочным выводам об улучшении качества перевода. Вместо этого необходимо проводить статистические тесты, чтобы определить, являются ли наблюдаемые различия действительно значимыми.
Выбор показателя для сравнения систем перевода
В статье «To Ship or Not to Ship: An Extensive Evaluation of Automatic Metrics for Machine Translation» исследователи из Microsoft изучили, какая метрика оценки качества машинного перевода лучше всего коррелирует с оценками профессиональных переводчиков. Для этого они провели следующий эксперимент.
Сначала профессиональные переводчики, свободно владеющие целевым языком, выполнили ручной перевод текста без постредактирования. Затем независимый переводчик подтвердил качество этих переводов. Переводчики видели контекст из других предложений, но переводили каждое предложение отдельно.
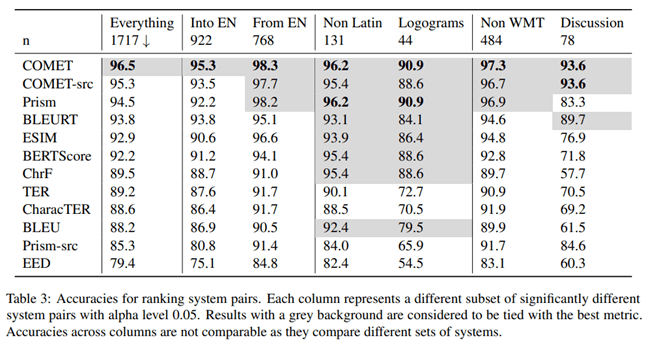
Согласно результатам исследования, метрика COMET, которая оценивает перевод на основе эталонного варианта, показала наивысшую корреляцию и точность по сравнению с оценками профессиональных переводчиков.
Авторы статьи также исследовали, какая метрика обеспечивает наибольшую точность при сравнении качества различных систем машинного перевода. По их выводам, COMET является наиболее точной метрикой для сравнения таких систем между собой.
Для проверки статистической значимости различий между результатами авторы использовали подход, описанный в статье “Statistical Significance Tests for Machine Translation Evaluation”.
Очевидно, что метрика COMET является наиболее надежным инструментом для оценки качества машинного перевода как при сравнении с человеческим переводом, так и при сравнении различных систем перевода между собой. Этот вывод имеет большое значение для разработчиков систем машинного перевода, которым необходимо объективно оценивать и сравнивать эффективность своих моделей.
Проверка статистической значимости
Важно убедиться, что наблюдаемые различия между системами перевода являются статистически значимыми, то есть с высокой вероятностью не являются результатом случайных факторов. Для этой цели Филипп Коэн предлагает использовать метод бутстрапа, описанный в его статье «Statistical Significance Tests for Machine Translation Evaluation»..
Метод бутстрапа (Bootstrap Resampling) – это статистическая процедура, основанная на выборке с возвращением, применяемая для определения точности (смещения) оценок дисперсии, среднего значения, стандартного отклонения, доверительных интервалов и других характеристик выборки. Схематично метод бутстрапа можно описать следующим образом:

Алгоритм проверки статистической значимости:
1. Из исходной выборки случайным образом создается бутстрап-выборка того же размера, при этом некоторые наблюдения могут попасть в выборку несколько раз, а другие не попасть вовсе.
2. Для каждой бутстрап-выборки вычисляется среднее значение метрики (например, BLEU или COMET).
3. Процедура генерации бутстрап-выборок и вычисления средних значений повторяется многократно (десятки, сотни или тысячи раз).
4. По полученному набору средних вычисляют общее среднее значение, которое принято считать средним значением всей выборки.
5. Вычисляется разница между средними значениями для сравниваемых систем.
6. Для разницы между средними значениями строится доверительный интервал.
7. С помощью статистических критериев оценивается, является ли доверительный интервал для разницы средних значений статистически значимым.
Практическое применение
Описанный выше подход реализован для метрики COMET в библиотеке Unbabel/COMET, которая, помимо вычисления метрики COMET, предоставляет возможность проверки статистической значимости полученных результатов. Этот метод является важным шагом к более надежной и объективной оценке систем машинного перевода. Простое сравнение метрик часто может вводить в заблуждение, особенно когда различия незначительны.
Применение методов статистического анализа, таких как бутстрап, играет ключевую роль в объективной оценке и сравнении эффективности систем машинного перевода. Это позволяет разработчикам принимать более обоснованные решения при выборе оптимальных подходов и моделей, а также обеспечивает более достоверное представление результатов пользователям.
Заключение
Таким образом, при сравнении систем машинного перевода важно использовать статистические методы, чтобы отличить значимые улучшения от случайных факторов. Это позволит дать более объективную оценку прогресса технологий машинного перевода.



