In machine translation quality evaluation, it is important not only to compare the results of different translation systems, but also to check whether the differences found are statistically significant. This allows us to assess whether the results obtained are valid and can be generalised to other data.
In this article, we review two of the most common metrics for assessing translation quality, BLEU and COMET, and analyse how to test the statistical significance of differences between two translation systems using these metrics.

Statistical Significance of BLEU and COMET
The BLEU (Bilingual Evaluation Understudy) metric evaluates translation quality by comparing the n-grams in a translated text with the n-grams in a reference (human) translation. According to the study “Yes, We Need Statistical Significance Testing”, in order to claim a statistically significant improvement in the BLEU metric over previous work, the difference must be greater than 1.0 BLEU score. If we consider a “highly significant” improvement as “p-value < 0.001”, the improvement must be 2.0 BLEU points or greater.
Another widely used metric, COMET (Crosslingual Optimised Metric for Evaluation of Translation), uses a machine learning model to evaluate the quality of translation compared to a reference translation. The study showed that a difference of 1 to 4 points can be statistically insignificant, i.e. within the margin of error. Even a difference of 4.0 COMET scores can be insignificant.
These results have important practical implications for developers of machine translation systems. Simply comparing numerical metrics can lead to misleading conclusions about improvements in translation quality. Instead, statistical tests should be performed to determine whether the observed differences are truly meaningful.
Selecting a Metric for Comparing Translation Systems
In the article “To Ship or Not to Ship: An Extensive Evaluation of Automatic Metrics for Machine Translation”, researchers from Microsoft investigated which metric for evaluating machine translation quality correlates best with the evaluation of professional translators. To do so, they conducted the following experiment.
Professional translators proficient in the target language first translated the text manually without post-editing, and then an independent translator confirmed the quality of these translations. The translators saw the context from other sentences, but translated the sentences separately.
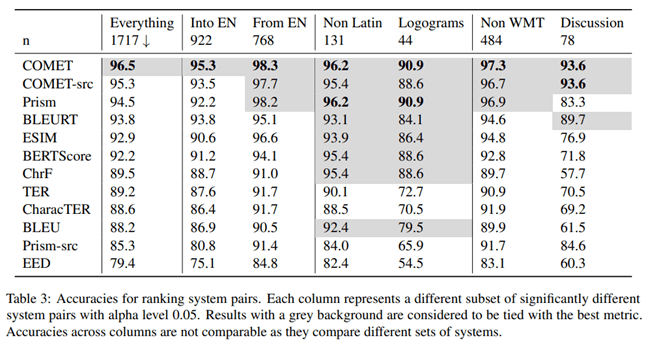
According to the results of this study, the COMET metric, which evaluates translation based on a reference variant, showed the highest correlation and accuracy when compared to evaluations by professional translators.
The authors of the article also studied which metric gives the highest accuracy when comparing the quality of different machine translation systems. According to their findings, COMET is the most accurate metric for comparing translation systems with each other.
To test the statistical significance of differences between the results, the authors used the approach described in the article “Statistical Significance Tests for Machine Translation Evaluation”.
It is clear that the COMET metric is the most reliable tool for evaluating the quality of machine translation, both when comparing it to human translation and when comparing different translation systems to each other. The conclusion is important for developers of machine translation systems who need to objectively evaluate and compare the performance of their models.
Statistical Significance Testing
It is important to make sure that the observed differences between translation systems are statistically significant, i.e., with a high probability that they are not the result of random factors. For this purpose, Philipp Koehn suggests using the bootstrap method in his article “Statistical Significance Tests for Machine Translation Evaluation”.
The bootstrap resampling method is a statistical procedure based on sampling with replacement to determine the precision (bias) of sample estimates of variance, mean, standard deviation, confidence intervals and other structural characteristics of a sample. Schematically, the bootstrap method can be represented as follows:

An algorithm for testing statistical significance:
1. A bootstrap sample of the same size is randomly generated from the original sample, where some observations may be captured several times and others may not be captured at all.
2. For each bootstrap sample, the mean value of a metric (e.g., BLEU or COMET) is calculated.
3. The procedure of bootstrap sampling and calculation of averages is repeated many times (tens, hundreds or thousands).
4. From the obtained set of averages, the overall average is calculated, which is considered to be the average of the entire sample.
5. The difference between the mean values for the compared systems is calculated.
6. A confidence interval is constructed for the difference between the averages.
7. The statistical criteria are used to assess whether the confidence interval for the difference of averages is statistically significant.
Practical Application
The approach described above is implemented for the COMET metric in the Unbabel/COMET library, which, in addition to calculating the COMET metric, also provides the ability to test the statistical significance of the results obtained. This approach is an important step towards a more reliable and valid evaluation of machine translation systems. Simply comparing metrics can often be misleading, especially when the differences are small.
The application of statistical analysis methods such as bootstrap is an important step in objectively evaluating and comparing the performance of machine translation systems. This allows developers to make more informed decisions when selecting optimal approaches and models, and provides a more reliable presentation of results to users.
Conclusion
Thus, when comparing machine translation systems, it is important to use statistical methods to separate meaningful improvements from random factors. This will give a more objective assessment of the progress of machine translation technology.