La reconnaissance vocale a parcouru un long chemin — passant de la dictée approximative des messageries vocales à des sous-titres en temps réel sur les flux en direct. En 2025, elle est intégrée partout : assistants intelligents, centres d’appels, applications de traduction, voire transcriptions juridiques. Mais à mesure que les promesses d’« une précision humaine » se font plus fortes, les doutes aussi grandissent.
Dans les cas d’usage professionnels réels, les erreurs restent fréquentes et problématiques. Demandez à toute entreprise qui gère des appels de support, des voicebots ou des transcriptions de réunions à grande échelle — la technologie échoue souvent quand cela compte vraiment.
Pourquoi ? Parce que la plupart des modèles de reconnaissance vocale automatique (ASR) sont entraînés et testés dans des conditions idéales, sans bruit, ni multilinguisme, ni chevauchements vocaux — alors que le monde réel est tout le contraire.
Cet article explore pourquoi les benchmarks traditionnels sont souvent trompeurs, comment les entreprises devraient évaluer les solutions ASR, et pourquoi Lingvanex est à la pointe de la nouvelle génération de systèmes de reconnaissance vocale adaptatifs, prêts pour l’entreprise. Nous avons mené une série de tests — sur accents, environnements et langues — pour comparer les API de reconnaissance vocale les plus populaires du marché. Les résultats ? Surprenants, révélateurs, et pratiques pour toute équipe développant des produits vocaux.

Pourquoi une évaluation précise de la reconnaissance vocale est cruciale pour les entreprises
La reconnaissance vocale n’est plus un gadget futuriste. C’est une technologie centrale intégrée aux applications bancaires, outils de visioconférence, logiciels juridiques et systèmes de support d’entreprise. En 2025, les entreprises ne se contentent plus d’utiliser la reconnaissance vocale — elles en dépendent.
Une ASR de mauvaise qualité n’est pas juste un désagrément — c’est un risque financier. Voici pourquoi : quand la qualité de transcription baisse, tout le reste suit:
- Impact sur le service client: des mots mal reconnus dans les appels de support entraînent des demandes non résolues et une baisse de la satisfaction client (CSAT).
- Non-conformité réglementaire: des transcriptions inexactes dans des secteurs régulés (finance, santé) peuvent provoquer des manquements aux règles.
- Perte de données: des informations manquées lors de réunions ou d’entretiens affectent le développement produit et la stratégie.
Pour être clair:
- Si votre ASR interprète « un chiffre d’affaires » par « un chef d’affaires », ce n’est pas une simple erreur — c’est un client perdu.
- Si votre service conformité se base sur des transcriptions qui omettent la moitié des termes financiers, vous êtes hors réglementation.
- Si votre voicebot comprend mal la moitié du espagnol qu’il entend, votre score NPS chute.
Les erreurs de reconnaissance ne sont pas qu’un sujet théorique. Elles coûtent cher.
Et les environnements modernes sont complexes. Les utilisateurs parlent vite, avec des accents, hésitent, marmonnent, changent de langue en pleine phrase. Parfois il y a du bruit de fond, des conversations croisées, ou un micro de mauvaise qualité. Un moteur utile doit tout gérer — de façon constante et sans intervention manuelle.
C’est pourquoi la qualité est essentielle. Parce qu’un moteur vocal ne se contente pas de reconnaître des mots — il décode des intentions, des instructions, des règles, des émotions. Si les mots sont faux, le sens s’effondre. Et quand on crée des produits qui reposent sur la confiance, il n’y a pas de place pour les approximations.
Méthodologie d’évaluation des performances des systèmes de reconnaissance vocale
Pour avoir une image réaliste des performances des meilleurs services ASR actuels, nous avons conçu un protocole de test qui reflète les scénarios d’usage réels — pas des conditions parfaites de laboratoire. Notre objectif était simple : évaluer la capacité de chaque système à gérer la complexité de la parole quotidienne dans différents domaines, appareils et langues.
Voici comment nous avons procédé.
Échantillons audio
Nous avons sélectionné un ensemble diversifié d’enregistrements reflétant les types d’entrées que les entreprises rencontrent le plus souvent, incluant:
- Enregistrements studio propres — pour une précision de base.
- Extraits d’appels téléphoniques — avec audio à bande étroite et faible débit.
- Dialogues de réunions — avec chevauchement des intervenants et rythme variable.
- Enregistrements de rue et café — avec bruit ambiant et bavardages.
Langues testées
Pour refléter l’applicabilité mondiale, nous avons inclus des échantillons dans ces langues : anglais, chinois simplifié, arabe, portugais, espagnol, français, allemand, italien, russe, ukrainien, kazakh, polonais.
Mesures d’évaluation
Nous avons utilisé deux indicateurs principaux:
- 1. Taux d’erreur sur les mots (WER), qui mesure le pourcentage de mots mal reconnus. Plus ce taux est bas, plus la reconnaissance est précise. Le WER est une norme industrielle bien établie, permettant de comparer globalement les performances.
- 2. Taux d’erreur sur les caractères (CER), qui mesure les erreurs au niveau des caractères, offrant une précision plus fine. Ce taux est crucial lorsque chaque lettre compte, comme pour les termes techniques ou les noms propres. Un CER faible montre que le système capture avec exactitude le contenu oral.
Vous pouvez découvrir plus en détail les limites des méthodologies modernes pour comparer les systèmes ASR et comment Lingvanex les surmonte dans l’article.
Résultats parlants : tests Lingvanex
Pour évaluer les performances en conditions réalistes, nous avons comparé Lingvanex avec d’autres services ASR populaires comme Deepgram (Nova-2), AssemblyAI, Gladia et Speechmatics. Nous avons choisi des API représentant la diversité des solutions prêtes à la production, avec différentes architectures, modèles de déploiement et axes stratégiques.
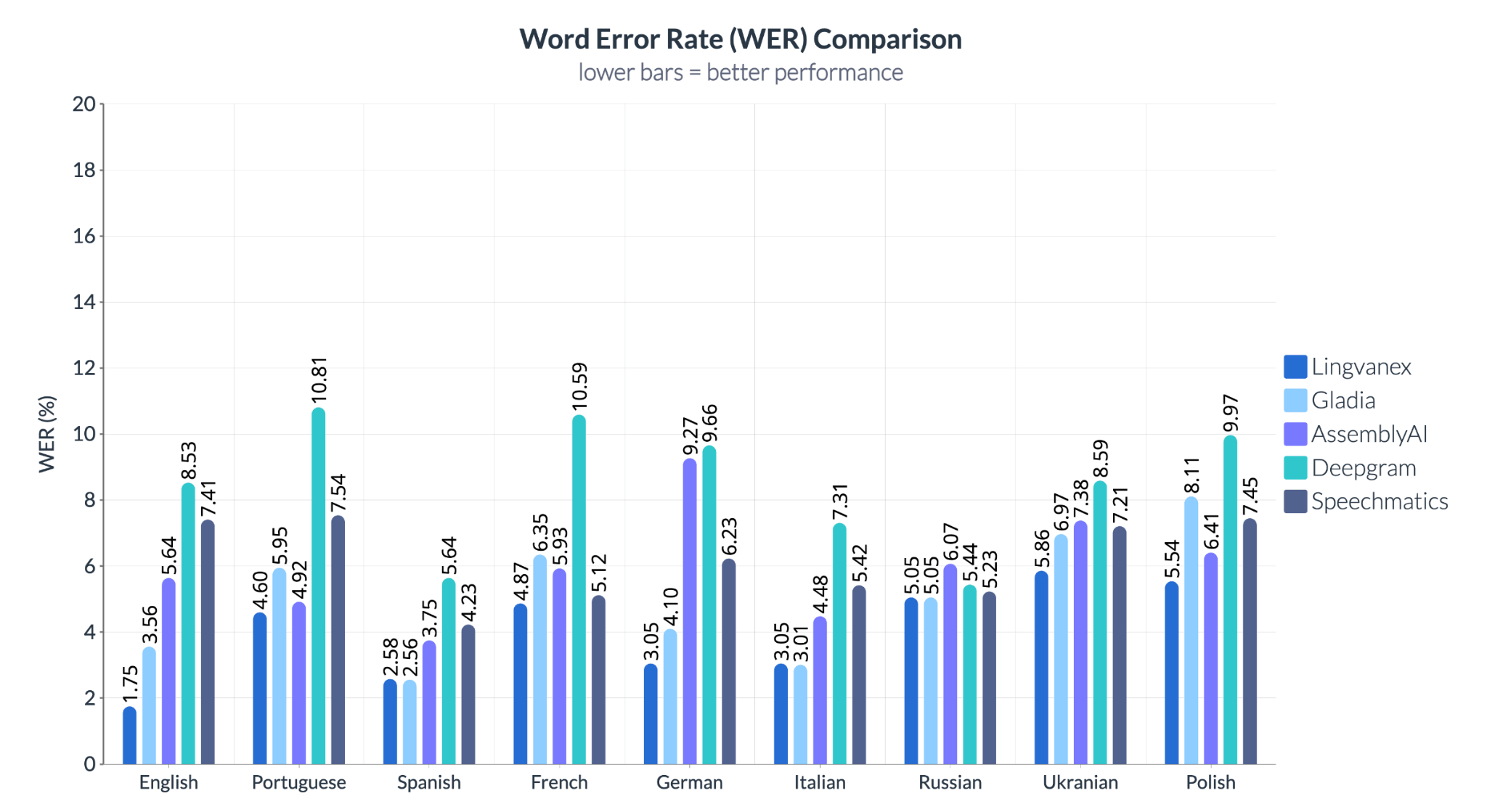
Les résultats montrent des variations significatives selon la langue et le fournisseur. Dans tous les cas, Lingvanex affiche les taux d’erreur les plus bas, surpassant ses concurrents en anglais, allemand et espagnol — trois langues très utilisées en entreprise. Deepgram a peiné avec le portugais et le français, tandis que Speechmatics montre des résultats irréguliers sur les langues slaves comme l’ukrainien et le polonais.
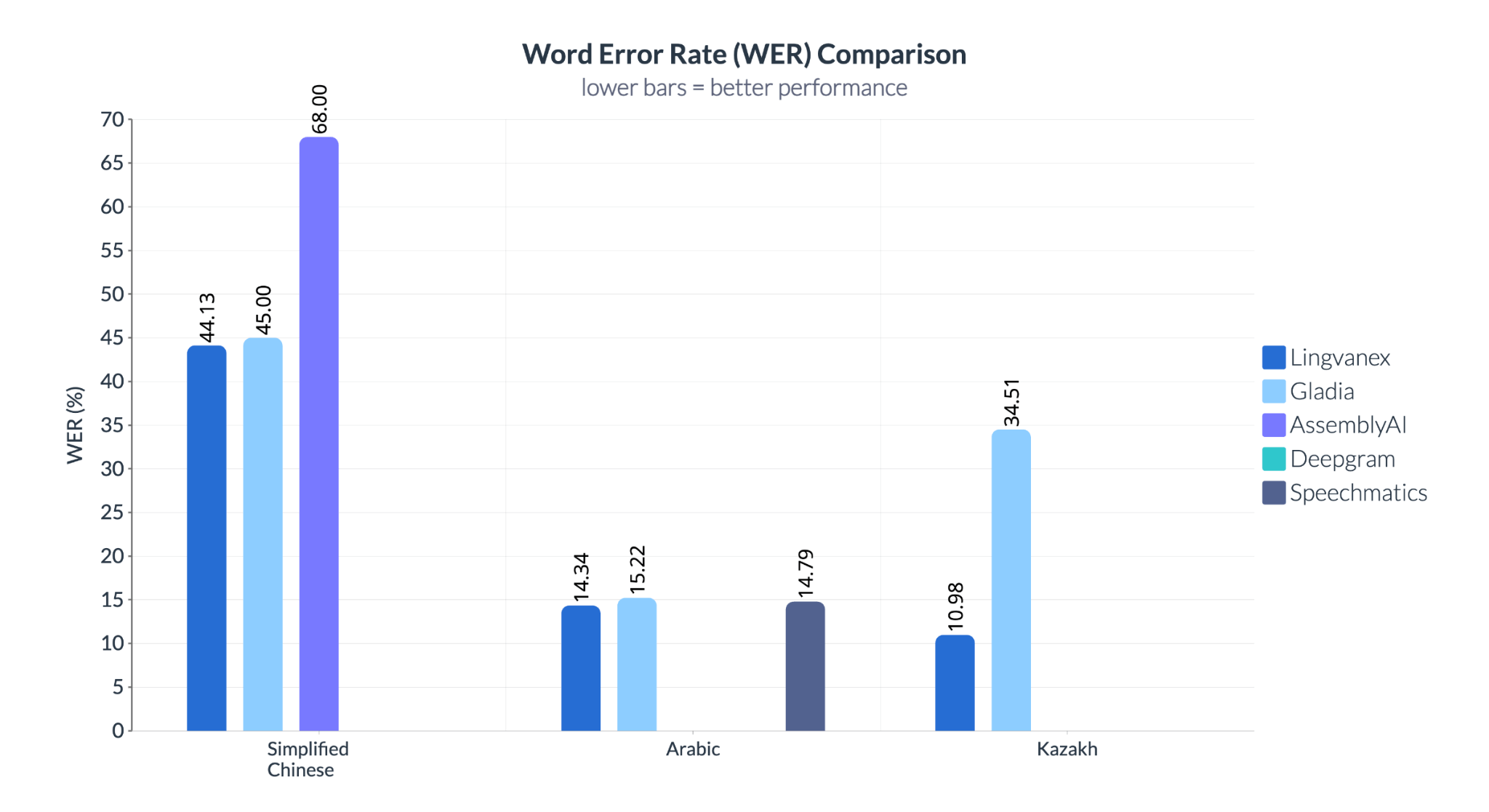
L’écart se creuse encore plus pour le kazakh, où Lingvanex obtient 10,98 % de WER contre 34,51 % pour Gladia, soulignant l’adaptabilité multilingue de Lingvanex. Pour le chinois simplifié, Speechmatics affiche un très mauvais 68 % de WER, contre 44,13 % pour Lingvanex.
La reconnaissance vocale prête pour l’entreprise, ce n’est pas qu’une question d’anglais. Pour les applications globales, les systèmes doivent exceller sur une grande diversité de langues, d’accents et de niveaux de bruit. Pour tout produit ciblant des marchés variés, la couverture linguistique n’est pas optionnelle — c’est une mission critique. Si votre système ne gère pas bien l’arabe ou s’écroule face au chinois, vos ambitions mondiales butent. Lingvanex ne se distingue pas seulement en théorie — mais là où ça compte vraiment : dans la performance terrain..
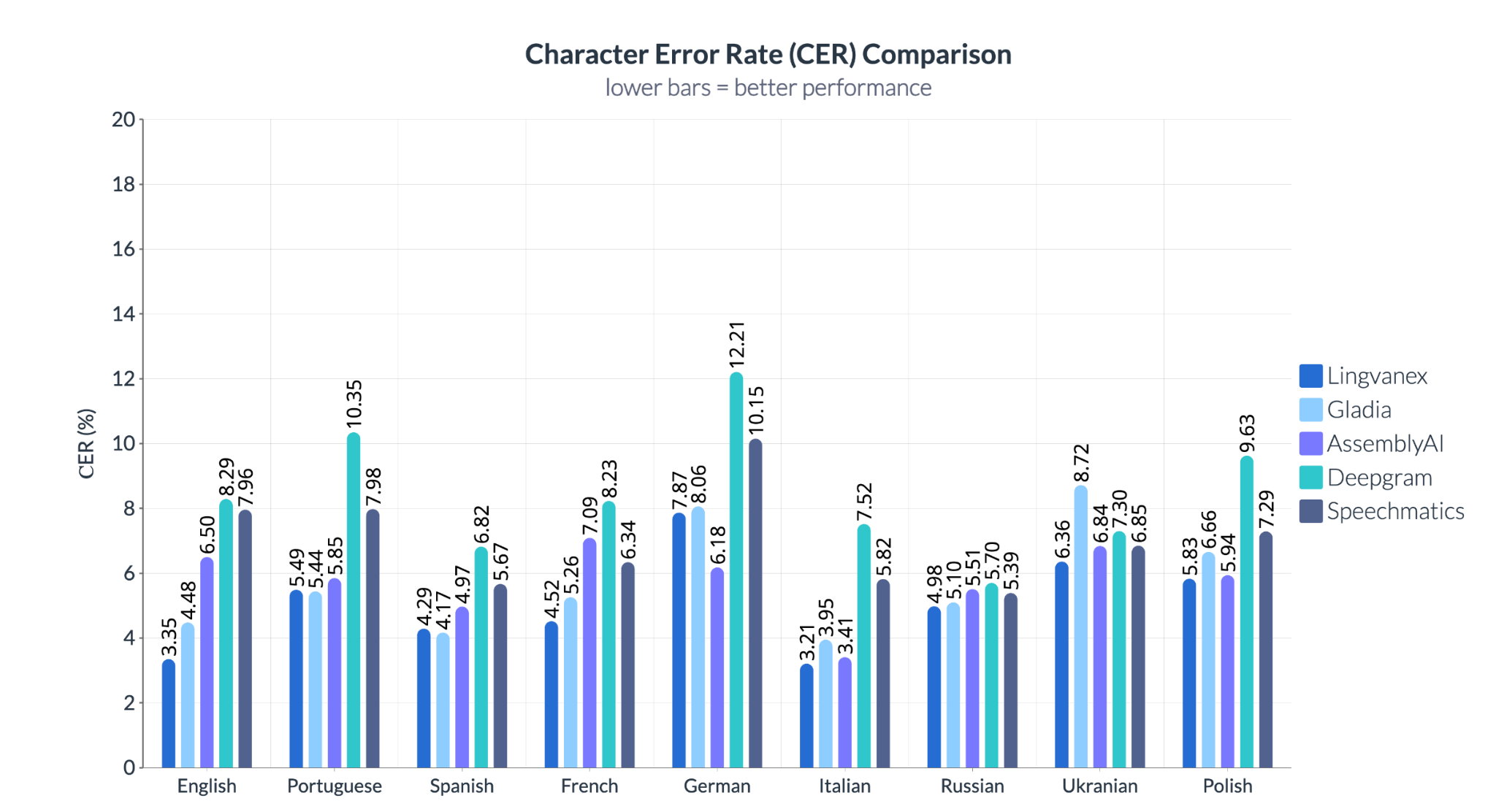
Lingvanex offre aussi une précision exceptionnelle au niveau des caractères, notamment dans des langues où la moindre erreur peut coûter cher, comme l’allemand (6,18 %) ou l’anglais (3,35 %). Deepgram montre la plus grande variabilité, dépassant 12 % de CER en allemand, ce qui le rend peu fiable dans les contextes techniques ou juridiques. Speechmatics traîne derrière en anglais et en polonais, et Gladia affiche des résultats erratiques, particulièrement faibles en kazakh et langues slaves.
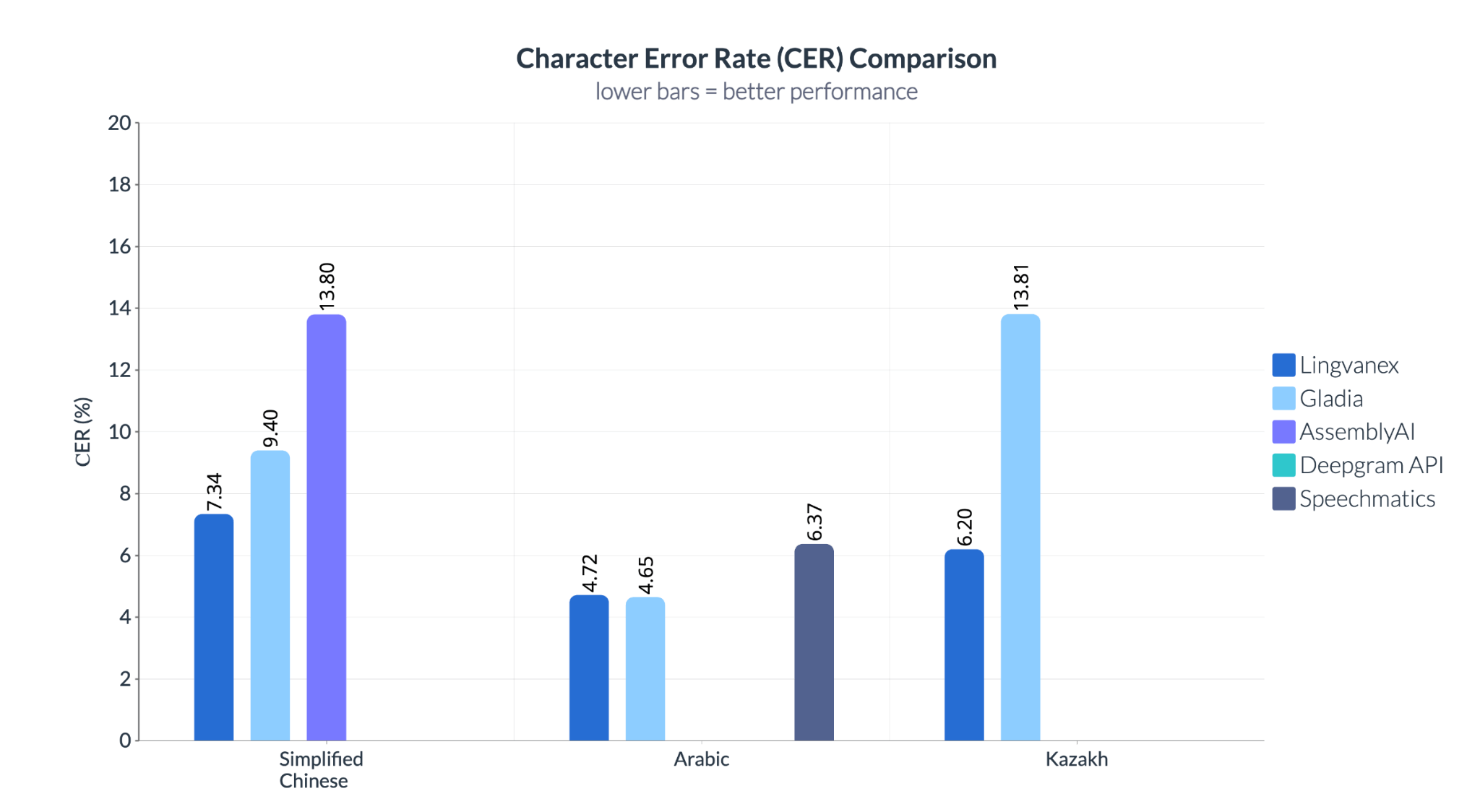
Lingvanex domine encore avec les taux de CER les plus bas sur ces trois langues. En chinois, AssemblyAI présente un taux d’erreur de 13,8 % — presque le double de Lingvanex (7,34 %). En kazakh, le 13,81 % de Gladia révèle un vrai manque de support, tandis que Lingvanex reste précis même avec peu de ressources. Contrairement au WER, qui se concentre sur les mots, le CER révèle les faiblesses fines de transcription — essentielles quand il s’agit de noms, commandes ou termes de conformité.
Sur WER et CER, Lingvanex affiche:
- Les taux d’erreur les plus bas.
- Une performance stable sur de nombreuses langues, de l’anglais et l’espagnol au kazakh et chinois.
- Une précision fiable dans des scénarios complexes — bruit, langues rares, discours chevauchés.
Lingvanex est le seul système de cette comparaison réellement conçu pour la production — pas juste pour des démos ou un usage anglophone. Sa constance sur les langues, métriques et conditions sonores prouve qu’il est précis, robuste et prêt à monter en charge — à l’échelle mondiale.
Lingvanex : des solutions adaptatives pour votre entreprise
Lingvanex : des solutions adaptatives pour votre entreprise
Contrairement aux API cloud classiques qui traitent la reconnaissance vocale comme un service isolé, Lingvanex propose une solution complète : reconnaissance vocale, traduction, routage linguistique — tout personnalisable et déployable selon vos besoins.
Les points forts uniques de Lingvanex:
- Flexibilité et personnalisation exceptionnelles adaptation aux besoins spécifiques, entraînement sur jargon métier, conformité aux protocoles de sécurité stricts.
- Traitement ultra-rapide des données: une minute d’audio traitée en seulement 3,44 secondes, bien plus rapide que la plupart des alternatives, pour un gain d’efficacité majeur.
- Gain de productivité: automatisation des tâches de transcription, libérant du temps pour des activités à plus forte valeur.
- Interaction client améliorée: compréhension précise des accents, dialectes, et conversations avec plusieurs interlocuteurs en bruit de fond, pour une expérience client fluide et satisfaisante.
- Réduction significative des coûts: rapidité et précision réduisent les dépenses liées à la sous-traitance et au traitement manuel.
- Intégration facile: API et SDK robustes s’adaptent facilement à votre infrastructure existante, sans coûts de développement excessifs.
- Compatibilité étendue: prise en charge de nombreux formats audio (WAV, MP3, OGG, FLV), pour s’adapter à vos sources de données.
- Sécurité de niveau entreprise: pour les organisations traitant des informations sensibles, Lingvanex propose des options de déploiement sécurisées sur site, garantissant le strict respect des normes de protection des données et des réglementations en matière de conformité
Conclusion : Lingvanex, votre partenaire pour une infrastructure vocale mondiale
Avec la voix qui devient une interface essentielle pour les entreprises globales, il est clair que:
- Les anciens modèles ASR ne gèrent pas la complexité métier
- L’évaluation doit dépasser le simple taux d’erreur sur les mots
- Adaptabilité, sécurité et personnalisation sont indispensables
Lingvanex allie précision, performance et flexibilité pour répondre aux besoins des entreprises dans tous les secteurs — avec un support multilingue et en conditions réelles inégalé.
Que vous développiez un voicebot multilingue, transcriviez des preuves juridiques ou analysiez des appels support, Lingvanex vous offre les outils pour une reconnaissance vocale précise, sécurisée et scalable.