Dans cet article, nous présentons les défis liés au développement d'une version mobile d'un système de traduction automatique neuronale. L'objectif est de maximiser la qualité des traductions tout en réduisant la taille du modèle. Nous expliquons l'ensemble du processus d'implémentation du moteur de traduction en utilisant comme exemple la paire de langues anglais-espagnol. Nous décrivons les défis rencontrés ainsi que les solutions mises en œuvre.
Les principales méthodes utilisées dans ce travail incluent:
- La sélection de données à l'aide de la méthode Infrequent n-gram Recovery ;
- L'ajout d'un mot spécial à la fin de chaque phrase ;
- La génération d'échantillons supplémentaires sans ponctuation finale.
Les deux dernières méthodes ont été développées pour créer un modèle de traduction générant des phrases sans point final ni autres marques de ponctuation. La méthode Infrequent n-gram Recovery a également été utilisée pour la première fois afin de créer un nouveau corpus, et non seulement pour augmenter un ensemble de données dans un domaine spécifique.
Enfin, nous avons abouti à un modèle de petite taille offrant une qualité suffisante pour une utilisation quotidienne.
L’approche Lingvanex
Lingvanex est une marque de produits linguistiques développée par Nordicwise LLC, spécialisée dans les applications de traduction et de dictionnaire hors ligne pour les plateformes mobiles et de bureau. En collaboration avec Sciling, une entreprise spécialisée dans les solutions de machine learning de bout en bout, un modèle compact de traduction anglais-espagnol a été développé pour une utilisation mobile. L'objectif principal était de fournir des traductions précises dans des situations quotidiennes, en particulier pour les voyageurs qui n'ont pas toujours accès à Internet en raison des coûts de roaming, de l'absence de cartes SIM locales ou d'une mauvaise connectivité dans certaines zones. Pour atteindre cet objectif, le projet s'est concentré sur la réduction de la taille du modèle grâce à des techniques de sélection de données, avec un objectif final de 150 Mo ou moins.
Des expériences ont été menées pour identifier les facteurs clés affectant la taille du modèle, notamment la taille du vocabulaire, les embeddings de mots et l'architecture du réseau neuronal. Divers problèmes de traduction sont apparus au cours du processus d'implémentation, ce qui a conduit au développement de solutions appropriées. La qualité du modèle final a été évaluée par rapport aux principaux traducteurs mobiles de Google et Microsoft, démontrant son efficacité pour une utilisation pratique dans des situations de voyage.
Description des données
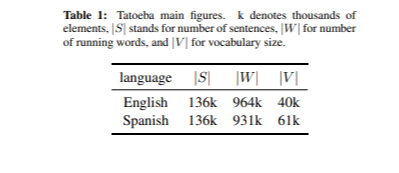
Les données utilisées pour entraîner le modèle de traduction ont été obtenues à partir du corpus OPUS. Au total, 76 millions de phrases parallèles ont été utilisées. Nous avons également utilisé le corpus Tatoeba pour la sélection des données, tel que décrit dans la section sur le filtrage des données. Tatoeba est une base de données collaborative gratuite en ligne, composée de phrases exemples destinées aux apprenants de langues. xL'ensemble de développement a été créé à partir du corpus Tatoeba en sélectionnant aléatoirement 2 000 paires de phrases. Les principales métriques du corpus Tatoeba sont présentées dans le Tableau 1. Pour l'ensemble de test, nous avons constitué un petit corpus composé de phrases anglaises utiles trouvées sur différents sites web. Nous avons également inclus quelques phrases unigrames et bigrammes. Au total, nous avons sélectionné 86 phrases.
Dépendance de la taille du modèle
Lorsqu'il s'agit de résoudre le problème de la réduction de la taille du modèle, le principal défi consiste à identifier les hyperparamètres ayant le plus grand impact sur la taille. Avant de mettre en œuvre le système de traduction automatique neuronale (TAN), des expériences ont été menées pour comparer la taille du modèle avec la taille globale du vocabulaire et la taille des embeddings de mots (Image 1). Différents modèles ont été entraînés en faisant varier ces hyperparamètres.
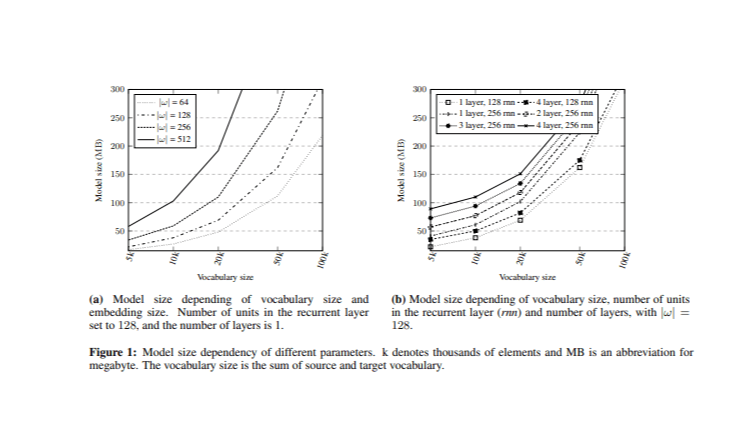
Dans l'expérience initiale, la couche récurrente comportait 128 unités, avec une couche à la fois du côté du codeur et du côté du décodeur. Les tailles de vocabulaire combinées (V) (source et cible) ont été réduites à différents niveaux |V| = {5k, 10k, 20k, 50k et 100k} sur la base des mots les plus fréquents dans le corpus Opus avec une distribution égale entre les vocabulaires source et cible, la taille des vocabulaires source et cible étant fixée à |V|/2. En outre, différentes tailles d'intégration |ω| = {64, 128, 256, 512} ont été analysées.
L'effet des différentes unités cachées et du nombre de couches a ensuite été examiné alors que la taille d'intégration était fixée à |ω| = 128. Les résultats ont montré que le nombre de couches avait un impact minime sur la taille du modèle, en particulier par rapport au nombre d'unités cachées et à la taille de l'intégration. Cette analyse fournit une base pour choisir des valeurs d'hyperparamètres appropriées tout en maintenant la taille du modèle dans l'objectif de 150 Mo.
Filtrage des données
Le filtrage des données a consisté en deux étapes principales. Tout d'abord, les phrases de plus de 20 mots ont été supprimées, car les traducteurs mobiles sont conçus pour traduire des phrases courtes. Ensuite, la sélection des données a été effectuée à l'aide de la récupération des n-grammes peu fréquents. Cette technique vise à sélectionner, parmi les données bilingues disponibles, les phrases qui maximisent la couverture des n-grammes au sein d'un ensemble de données plus restreint et spécifique à un domaine.
L'approche consiste à trier l'ensemble des données en fonction du score d'infréquence de chaque phrase afin de donner la priorité aux phrases les plus informatives. Soit χ l'ensemble des n-grammes dans les phrases à traduire, et w l'un de ces n-grammes. C( w ) indique le nombre de w dans l'ensemble d'apprentissage de la langue source, tandis que t est un seuil pour déterminer quand un n-gramme est considéré comme peu commun. N( w ) désigne le nombre de w dans la phrase source f. Le score d'infréquence de f est (1):
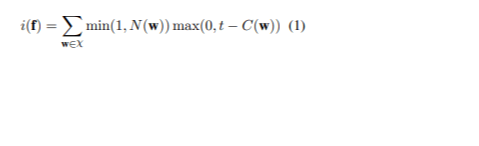
Pour les 60 millions de phrases du corpus Opus, jusqu'à 5 n-grammes ont été extraits du corpus Tatoeba, en visant un maximum de 30 occurrences pour chaque n-gramme. Pour gérer le temps d'exécution, le corpus a été divisé en six partitions, la sélection étant effectuée individuellement avant de fusionner les résultats. Un dernier processus de sélection a été effectué pour s'assurer qu'aucun n-gramme ne dépassait le seuil d'occurrence. Au final, ce processus a permis d'obtenir un ensemble de 740 000 phrases avec un vocabulaire de 19 400 mots dans la langue source et de 22 900 mots dans la langue cible, soit un vocabulaire combiné de 42 400 mots. L'échantillon était basé sur le corpus tokenisé et stringifié.
Configuration expérimentale
Le système a été entraîné en utilisant le cadre d’apprentissage profond OpenNMT, qui se concentre sur le développement de modèles séquence-à-séquence pour diverses tâches, y compris la traduction automatique et le résumé. La méthode de codage par paires de caractères ( Byte Pair Encoding, BPE) a été appliquée à un ensemble de données d’entraînement sélectionné, puis utilisée pour les ensembles de données d’entraînement, de développement et de test. Un réseau neuronal récurrent à mémoire à long terme ( Long Short-Term Memory, LSTM) a été utilisé, incluant une couche d’attention globale pour améliorer la traduction en se concentrant sur des parties spécifiques de la phrase source. L’entrée alimentée ( input feed ) a également été utilisée pour fournir des vecteurs d’attention aux étapes temporelles suivantes, bien que cet effet n’ait été notable qu’avec quatre couches ou plus.
L’entraînement a été effectué sur 50 époques en utilisant l’optimiseur Adam avec un taux d’apprentissage de 0,0002. Le meilleur modèle a été sélectionné en fonction du score BLEU le plus élevé sur l’ensemble de développement et a été utilisé pour traduire l’ensemble de test. En raison de la petite taille de l’ensemble de test, une évaluation humaine a été réalisée pour évaluer la qualité des traductions.
Résultats et analyse
Différents types de réseaux neuronaux ont été entraînés en se basant sur les idées présentées dans la section Dépendance de la taille du modèle. Pour chaque expérience, les hyperparamètres ont été ajustés tout en maintenant la taille totale du vocabulaire fixée à 42,4k mots. Le Tableau 2 montre les valeurs des hyperparamètres pour chaque expérience, ainsi que les scores BLEU et les tailles des modèles.
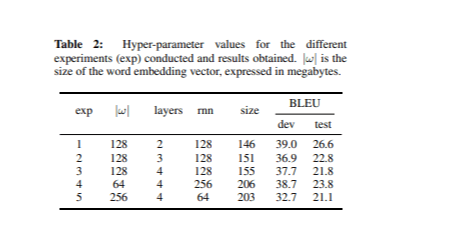
Le meilleur modèle, mesuré par le score BLEU sur l’ensemble de développement, comprenait 2 couches et 128 unités dans la couche récurrente, avec une taille d’embedding de 128. Notamment, ce modèle était également le plus petit parmi ceux listés dans le Tableau 2.
Problèmes identifiés et leurs solutions
L’analyse des traductions issues de l’ensemble de test a révélé trois problèmes clés, pour lesquels des solutions spécifiques ont été proposées:
1. Problème de répétition de mots
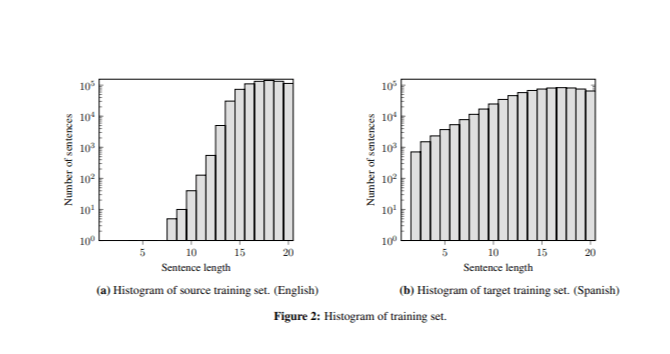
Le meilleur modèle produisait des traductions correctes pour les phrases de plus de sept mots, mais générait souvent des mots répétés dans des phrases très courtes (par exemple: « perro perro perro » ). Ce problème était dû à la différence de longueur des phrases entre les données d’entraînement et l’ensemble de test, car l’ensemble d’entraînement contenait peu de phrases courtes (Image 2).
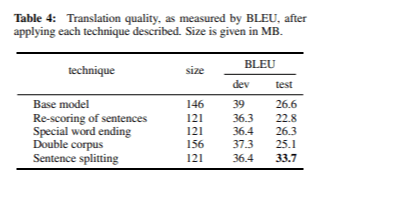
Pour atténuer ce problème, nous avons ajusté la fonction de score de la méthode Infrequent n-gram Recovery en ajoutant une étape de normalisation (2).
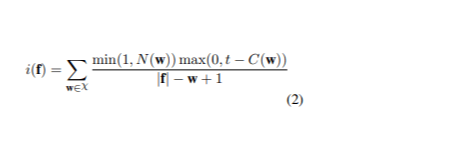
Après l'application du score d'infréquence pour la sélection des données, nous avons sélectionné un ensemble de 667 000 phrases. Le Tableau 3 présente la longueur moyenne des phrases dans les langues source et cible, avant et après l'application de la normalisation de la longueur des phrases.
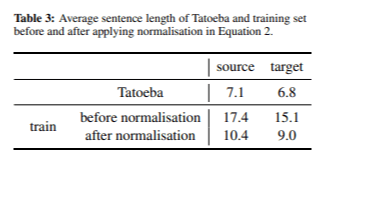
Le processus de normalisation nous a permis d’obtenir des phrases nettement plus courtes dans les langues source et cible. Le modèle a atteint un score BLEU de 36,3 lors du développement et de 22,8 lors des tests, avec une taille totale de modèle de 121 Mo. Bien que ces scores soient légèrement inférieurs à ceux des expériences précédentes, nous estimons que le score BLEU ne reflète pas toujours précisément la qualité de la traduction. Une analyse manuelle a confirmé que le problème des mots répétés a été efficacement résolu.
2. Attente de ponctuation
Le modèle produisait des traductions incorrectes pour des phrases très courtes (par exemple, en traduisant « dog » par « amor » ), sauf si une marque de ponctuation était ajoutée (par exemple, « dog » ). Ce problème était dû à l'attente du modèle de voir une ponctuation à la fin des phrases, 94 % des phrases d’entraînement se terminant par une marque de ponctuation. Deux solutions ont été proposées pour résoudre ce problème:
- Fin de mot spéciale: nous avons ajouté un jeton spécial @@ à la fin de chaque phrase. Cette approche entraîne le modèle à reconnaître que chaque phrase se termine par @@, alors que l'avant-dernier mot peut être ou non un signe de ponctuation. Cette technique a été mise en œuvre en tant qu'étape de pré-traitement et de post-traitement, d'où son nom de « terminaison spéciale des mots ». Le modèle utilisant cette technique a obtenu un score BLEU de 36,4 en développement et de 26,3 en test après 21 époques, avec une taille de 121 Mo.
- Double corpus: nous avons élargi le corpus de formation en combinant toutes les phrases existantes qui se terminent par des signes de ponctuation, en supprimant ces caractères. Cela a permis au modèle d'apprendre que les phrases peuvent se terminer avec ou sans signe de ponctuation. Dans ce cas, la taille du modèle est passée à 156 Mo, ce qui a permis d'obtenir un score BLEU de 37,3 en développement et de 25,1 en test.
Les deux méthodes ont efficacement résolu le problème d’attente de ponctuation. Toutefois, en raison de la taille plus importante et du score BLEU inférieur en test pour la stratégie du corpus double, nous avons décidé d’utiliser la technique du mot de fin spécial.
3. Segments manquants
Il a été observé que lors de la traduction de segments contenant plusieurs phrases courtes, seul le premier était traduit (par exemple, « Thank you. That was really helpful. » devenait « Gracias. » ).
Pour résoudre ce problème, une étape de prétraitement a été introduite pour séparer les segments en fonction des marques de ponctuation. Cette modification a augmenté le nombre de segments de 86 à 118 dans l’ensemble de test. Après ce changement, les traductions se sont considérablement améliorées, atteignant un score BLEU de 36,4 en développement et de 33,7 en test, le meilleur résultat enregistré à ce jour.
Évaluation finale
Le Tableau 4 résume les scores BLEU obtenus après l’application de chacune des solutions décrites dans la section Problèmes identifiés et leurs solutions. Après avoir appliqué le score d’infréquence normalisé, le mot de fin spécial et le prétraitement des phrases construites, nous avons amélioré la qualité des traductions sur l’ensemble de test d’environ 7 points BLEU.
Lors de l’évaluation finale de notre système de traduction, nous avons comparé sa qualité à celle des traducteurs mobiles de Google et de Microsoft. Le Tableau 5 présente les scores BLEU et les tailles des modèles pour chaque traducteur sur l’ensemble de test.
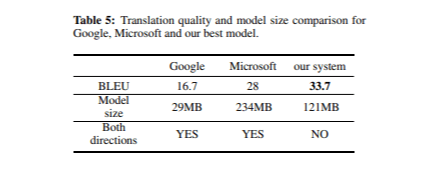
Dans l'ensemble, les trois systèmes ont produit des traductions de haute qualité, bien que certaines différences mineures aient été observées. Notre modèle a particulièrement bien performé en ce qui concerne les marques de ponctuation et les majuscules, tandis que Google Translate plaçait souvent incorrectement les marques de ponctuation et utilisait rarement les majuscules. Cela peut expliquer pourquoi Google Translate a obtenu un score BLEU inférieur à celui des deux autres systèmes, malgré une taille de modèle plus petite. De plus, les modèles de Google et de Microsoft sont bidirectionnels, ce qui signifie que la taille de notre modèle doit être doublée (2 × 121 Mo) pour une comparaison équitable.
Conclusion
Cet article décrit le développement d’un modèle compact de traduction automatique neuronale mobile pour l’anglais-espagnol. Nous avons utilisé une méthode de sélection des données pour améliorer l’adéquation des données d’entraînement et avons effectué des ajustements pour améliorer la qualité des traductions. Des solutions ont été proposées pour résoudre les problèmes de mots répétés et de traductions manquantes dans les segments.
Notre modèle a surpassé les traducteurs mobiles de Google et de Microsoft en termes de scores BLEU, notamment dans la gestion de la ponctuation et des majuscules. Avec une taille de 121 Mo, notre modèle est plus petit que ce qui avait été initialement estimé, tout en offrant une bonne qualité de traduction pour des contextes liés aux voyages. Les traductions sont fluides et compréhensibles, adaptées à une utilisation hors ligne. Les efforts actuels se concentrent sur l’amélioration continue de la qualité et la réduction de la taille du modèle, en explorant notamment des méthodes telles que la réduction des poids.