
Σήμερα, οι εταιρείες στρέφονται όλο και περισσότερο σε τεχνολογίες αναγνώρισης ομιλίας για να βελτιώσουν την εξυπηρέτηση των πελατών, να αυτοματοποιήσουν τις ροές εργασίας και να αναλύουν τα δεδομένα. Με πολλές λύσεις που διατίθενται στην αγορά, η επιλογή του σωστού συστήματος γίνεται μια πραγματική πρόκληση. Οι επιχειρήσεις αναζητούν ισορροπία μεταξύ ακρίβειας, ταχύτητας, ενσωμάτωσης με υπάρχουσες διαδικασίες και ασφάλειας δεδομένων.
Ωστόσο, η σύγκριση των συστημάτων αναγνώρισης ομιλίας δεν αφορά μόνο την ανάλυση των μετρήσεων ακρίβειας. Είναι σημαντικό να εξεταστούν οι λεπτομέρειες κάθε συστήματος στο πλαίσιο της πραγματικής χρήσης. Μπορεί να προκύψουν προβλήματα λόγω των διαφορών στις μεθοδολογίες των δοκιμών και στις αποκλίσεις μεταξύ των αποτελεσμάτων των δοκιμών και των πραγματικών συνθηκών λειτουργίας. Σε αυτό το άρθρο, θα βουτήξουμε για το πώς το lingvanex Αντιμετωπίζει αυτές τις προκλήσεις, προσφέροντας μια αξιόπιστη και αποτελεσματική λύση για τις επιχειρήσεις.

Ζητήματα με σύγχρονες μεθοδολογίες στη σύγκριση των συστημάτων αναγνώρισης ομιλίας
Η επιλογή ενός συστήματος αναγνώρισης ομιλίας δεν είναι εύκολη, σε μεγάλο βαθμό οφείλεται σε ελαττώματα με τους τρόπους που δοκιμάζονται αυτά τα συστήματα. Οι σύγχρονες προσεγγίσεις για τη σύγκριση των συστημάτων αναγνώρισης ομιλίας αντιμετωπίζουν διάφορα προβλήματα που μπορούν να παραμορφώσουν τα αποτελέσματα και να περιπλέξουν τις αντικειμενικές αξιολογήσεις. Εδώ είναι τα κύρια ζητήματα που προκύπτουν κατά τη διάρκεια αυτών των συγκρίσεων:
1. Περιορισμένα σύνολα δεδομένων δοκιμών
Τα συστήματα αναγνώρισης ομιλίας συχνά δοκιμάζονται σε προετοιμασμένα και περιορισμένα σύνολα δεδομένων. Αυτά τα σύνολα ενδέχεται να μην αντικατοπτρίζουν πραγματικές συνθήκες χρήσης, όπως διάφορες πινελιές, διαλέκτους, θόρυβος και μη τυποποιημένες κατασκευές ομιλίας. Αυτό μπορεί να οδηγήσει σε φουσκωμένα αποτελέσματα δοκιμών που δεν αντιπροσωπεύουν την πραγματική απόδοση του συστήματος σε πραγματικές συνθήκες.
2. Υπερέξτε στο ποσοστό σφάλματος λέξεων (WER)
Στις περισσότερες περιπτώσεις, τα συστήματα αξιολογούνται με βάση το ποσοστό σφάλματος λέξεων (WER), το οποίο μετρά το ποσοστό των εσφαλμένων αναγνωρισμένων λέξεων. Ωστόσο, αυτή η μέτρηση δεν αρκεί πάντα για μια ολοκληρωμένη αξιολόγηση του συστήματος. Για παράδειγμα, τα μικρά λάθη με μεμονωμένες λέξεις μπορεί να μην επηρεάζουν σημαντικά τη συνολική κατανόηση, αλλά ένα σύστημα με χαμηλό WER θα μπορούσε να κάνει σφάλματα σε σημαντικά σημαντικά λόγια, οδηγώντας σε παρεξηγήσεις.
3. Έλλειψη πλαισίου εξέταση
Πολλά συστήματα αναγνώρισης ομιλίας αντιμετωπίζουν την ομιλία ως ένα σύνολο ανεξάρτητων λέξεων, χωρίς να λαμβάνουν υπόψη το πλαίσιο. Ωστόσο, το πλαίσιο μπορεί να επηρεάσει σημαντικά τη σωστή αναγνώριση των λέξεων, ειδικά όταν οι λέξεις ακούγονται παρόμοιες, αλλά έχουν διαφορετικές έννοιες ανάλογα με τις γύρω φράσεις.
4. Ανεπαρκής προσοχή στους τόνους και τις διαλέκτους
Πολλές μεθοδολογίες δοκιμών δεν δίνουν αρκετή προσοχή στην ποικιλομορφία των προβολών και των διαλέκτων. Αυτό οδηγεί σε συστήματα που λειτουργούν καλά με "τυπική" γλώσσα, αλλά δείχνουν χαμηλή ακρίβεια όταν αλληλεπιδρούν με άτομα που μιλούν σε διαλέκτους ή με έντονη προφορά.
5. Υποτιμώντας την εμπειρία των χρηστών
Τα συστήματα συχνά αξιολογούνται μόνο με βάση τεχνικές παραμέτρους, όπως η ακρίβεια και η ταχύτητα αναγνώρισης, αλλά παραβλέπεται η ευκολία χρήσης για τον τελικό χρήστη. Για παράδειγμα, ένα σύστημα μπορεί να είναι ακριβές, αλλά απαιτεί υπερβολική προσπάθεια για εκπαίδευση ή διαμόρφωση.
6. Θόρυβο φόντου και καταγραφές κακής ποιότητας
Τα περιβάλλοντα πραγματικού κόσμου είναι σπάνια ήσυχα. Ο θόρυβος του φόντου, είτε από γραφεία, δημόσιους χώρους ή μηχανήματα, μπορεί να παρεμβαίνει στην ακριβή αναγνώριση. Επιπλέον, δεν είναι όλες οι ηχογραφήσεις και τα συστήματα συχνά αγωνίζονται με ήχο χαμηλής ποιότητας, όπως τηλεφωνήματα ή φωνητικά μηνύματα.
7. Ταχύτητα ομιλίας
Οι άνθρωποι μιλούν με διαφορετικές ταχύτητες και τα συστήματα συχνά δυσκολεύονται να κατανοήσουν τόσο πολύ αργή όσο και πολύ γρήγορη ομιλία. Αυτό μπορεί να οδηγήσει στην απώλεια σημαντικών πληροφοριών ή σφαλμάτων μεταγραφής.
8. Multitasking ομιλίας
Σε πραγματικές συνθήκες, όπως συναντήσεις ή επιχειρηματικές κλήσεις, πολλοί άνθρωποι συχνά μιλούν ταυτόχρονα. Το σύστημα πρέπει να είναι σε θέση να διαφοροποιήσει τις φωνές και να αναγνωρίσει με ακρίβεια την ομιλία κάθε συμμετέχοντος.
Οι μεθοδολογίες δοκιμών για την αξιολόγηση των συστημάτων αναγνώρισης ομιλίας χρειάζονται βελτίωση για να ληφθούν υπόψη οι συνθήκες πραγματικού κόσμου και τα ευρύτερα σενάρια. Σε lingvanex Κατανοούμε αυτούς τους περιορισμούς και αναπτύσσουμε λύσεις που προσαρμόζονται στις πραγματικές συνθήκες εργασίας των επιχειρήσεων. Δεν βασιζόμαστε αποκλειστικά στις εργαστηριακές δοκιμές: το σύστημά μας δοκιμάζεται σε συνθήκες κοντά στην πραγματική χρήση, επιτρέποντάς μας να εντοπίσουμε και να εξαλείψουμε τα πιθανά προβλήματα νωρίς.
Πώς το Lingvanex επιλύει αυτά τα προβλήματα
Για να εξασφαλιστεί η υψηλή ακρίβεια αναγνώρισης ομιλίας σε πραγματικές συνθήκες, η Lingvanex εφαρμόζει αρκετές μοναδικές τεχνικές προσεγγίσεις:
- Προσαρμογή σε τόνους και διαλέκτους
Το Lingvanex χρησιμοποιεί βαθιά νευρωνικά δίκτυα που εκπαιδεύονται σε μεγάλα σύνολα δεδομένων με διάφορες προθέσεις και διαλέκτους. Τα μοντέλα μας εκπαιδεύονται χρησιμοποιώντας τεχνολογίες εκμάθησης μεταφοράς, οι οποίες μας επιτρέπουν να προσαρμόζουμε αποτελεσματικά τα συστήματα σε νέους τόνους, απαιτώντας ελάχιστα πρόσθετα δεδομένα για τελειοποίηση. Προσφέρουμε επίσης τη χρήση εξειδικευμένων μοντέλων τομέα, προσαρμοσμένα σε συγκεκριμένες βιομηχανίες ή περιοχές, γεγονός που ενισχύει την ακρίβεια για το κοινό -στόχο.
Χάρη στην ικανότητα του συστήματος να προσαρμοστεί σε συγκεκριμένες προθέσεις και διαλέκτους, οι εταιρείες μπορούν να συνεργαστούν με σιγουριά με ένα διεθνές κοινό, παρέχοντας υψηλής ποιότητας φωνητικές υπηρεσίες και βελτιώνοντας την αλληλεπίδραση των πελατών, η οποία είναι ιδιαίτερα σημαντική για τις παγκόσμιες επιχειρήσεις.
- Καταστολή του θορύβου
Το Lingvanex ενσωματώνεται με τεχνολογίες καταστολής ενεργού θορύβου για να φιλτράρει τον θόρυβο του φόντου. Αυτό επιτρέπει στο σύστημα να εξαλείψει αποτελεσματικά τον θόρυβο διατηρώντας παράλληλα τη σαφήνεια της ομιλίας. Οι αλγόριθμοι καταστολής θορύβου εφαρμόζονται κατά τη διάρκεια του σταδίου προεπεξεργασίας σήματος ήχου, καθιστώντας το σύστημα ιδιαίτερα χρήσιμο σε τηλεφωνικά κέντρα και γραφεία ανοικτού σχεδιασμού.
Οι εταιρείες που εργάζονται σε θορυβώδη γραφεία, τηλεφωνικά κέντρα ή χώρους παραγωγής μπορούν να παρέχουν στους πελάτες ακριβείς και σαφείς μεταγραφές συνομιλιών, βελτιώνοντας την ποιότητα των υπηρεσιών και αυξάνοντας την ικανοποίηση των πελατών.
- Βελτιστοποίηση για ήχο χαμηλής ποιότητας
Τα συστήματα LingVanex χρησιμοποιούν ειδικούς αλγόριθμους για την επεξεργασία δεδομένων ήχου χαμηλού δείγματος, όπως τηλεφωνικές κλήσεις. Αυτό είναι ιδιαίτερα σημαντικό για τις επιχειρήσεις που λειτουργούν με τηλεφωνικά επικοινωνία και μηνύματα φωνής.
Οι επιχειρήσεις που στηρίζονται σε μεγάλο βαθμό σε τηλεφωνικές γραμμές ή φωνητικά μηνύματα μπορούν να λάβουν ακριβείς μεταγραφές ακόμη και από καταγραφές χαμηλής ποιότητας. Αυτό βελτιώνει την ανάλυση δεδομένων, επιταχύνει την επεξεργασία αιτήματος πελατών και μειώνει τα σφάλματα.
- Προσαρμογή ταχύτητας
Το Lingvanex χρησιμοποιεί νευρωνικά δίκτυα για να επεξεργαστεί την ομιλία σε διάφορες ταχύτητες. Αυτό εξασφαλίζει σταθερή απόδοση του συστήματος ανεξάρτητα από το ποσοστό ομιλίας, το οποίο είναι κρίσιμο για την αυτοματοποίηση των μεταγραφών και την ανάλυση μεγάλων όγκων φωνητικών δεδομένων.
Οι εταιρείες μπορούν να χρησιμοποιήσουν με σιγουριά το σύστημα για αυτόματη μεταγραφή κλήσεων ή συναντήσεων, ανεξάρτητα από το πόσο γρήγορα ή επιβραδύνει τις συνομιλίες των ηχείων. Αυτό μειώνει το χρόνο που δαπανάται για τη χειροκίνητη επεξεργασία δεδομένων και αυξάνει την ακρίβεια της μεταγραφής.
- Διαφοροποίηση ηχείων
Τα συστήματα Lingvanex μπορούν να εντοπίσουν και να αποδώσουν τη φωνή κάθε συμμετέχοντα σε μια συνομιλία. Οι αλγόριθμοι διαμόρφωσης των ηχείων χρησιμοποιούνται για να διαχωριστούν και να εντοπιστούν οι ομιλητές σε πραγματικό χρόνο.
Αυτή η λύση επιτρέπει στις εταιρείες που εργάζονται με εγγραφές πολλαπλών ομιλητών (π.χ. συναντήσεις ή συνέδρια) για να αποκτήσουν ακριβείς μεταγραφές, απλοποιώντας την ανάλυση δεδομένων, βελτιώνοντας την επικοινωνία και εξοικονόμηση χρόνου στη χειροκίνητη μεταγραφή.
Lingvanex εναντίον Whisper: Μια σύγκριση με επικεφαλής προς κεφαλή
Όταν πρόκειται για συστήματα αναγνώρισης ομιλίας, ένα από τα βασικά κριτήρια αξιολόγησης είναι η απόδοση που βασίζεται σε αντικειμενικές μετρήσεις. Για να σας δώσουμε μια σαφέστερη εικόνα, πραγματοποιήσαμε μια συγκριτική δοκιμή του Lingvanex εναντίον ενός άλλου σημαντικού συστήματος, Whisper, χρησιμοποιώντας τόσο τα πρότυπα όσο και τα δεδομένα πραγματικού κόσμου.
Βασικές μετρήσεις που αξιολογήσαμε:
- Ποσοστό σφάλματος λέξεων (WER) - Αυτή η μέτρηση αντικατοπτρίζει το ποσοστό των εσφαλμένων αναγνωρισμένων λέξεων. Όσο χαμηλότερα είναι το WER, τόσο ακριβέστερα το σύστημα χειρίζεται την αναγνώριση ομιλίας.
- Ποσοστό σφάλματος χαρακτήρων (CER) - Αυτή η μέτρηση μετρά τα σφάλματα στο επίπεδο χαρακτήρων και όχι στο επίπεδο λέξεων. Παρέχει μια πιο λεπτομερή άποψη για το πόσο με ακρίβεια το σύστημα μπορεί να επεξεργαστεί κάθε προφορική λέξη. Αυτό είναι ζωτικής σημασίας για σενάρια όπου κάθε γράμμα έχει σημασία, όπως η συνεργασία με πολύπλοκες όρους ή ονόματα. Το χαμηλότερο CER δείχνει ότι το σύστημα εκτελεί αναγνώριση ομιλίας με μεγαλύτερη ακρίβεια.
- Χρόνος επεξεργασίας ήχου - Αυτή η μέτρηση δείχνει πόσο καιρό χρειάζεται το σύστημα για την επεξεργασία ενός λεπτού ήχου. Η ταχύτητα επεξεργασίας είναι ιδιαίτερα σημαντική για τις εταιρείες που ασχολούνται με μεγάλους όγκους δεδομένων ή εφαρμογών σε πραγματικό χρόνο, όπου η γρήγορη ανταπόκριση ενός συστήματος είναι κρίσιμη. Οι κάτω ράβδοι σημαίνει καλύτερη απόδοση του συστήματος.
Η αξιολόγηση αυτών των μετρήσεων βοηθά όχι μόνο στην κατανόηση της ακρίβειας του συστήματος αλλά και του τρόπου με τον οποίο εκτελεί σε πραγματικές συνθήκες, όπου όχι μόνο η ακρίβεια αλλά και η ταχύτητα, η ευελιξία και η προσαρμοστικότητα είναι σημαντικές.
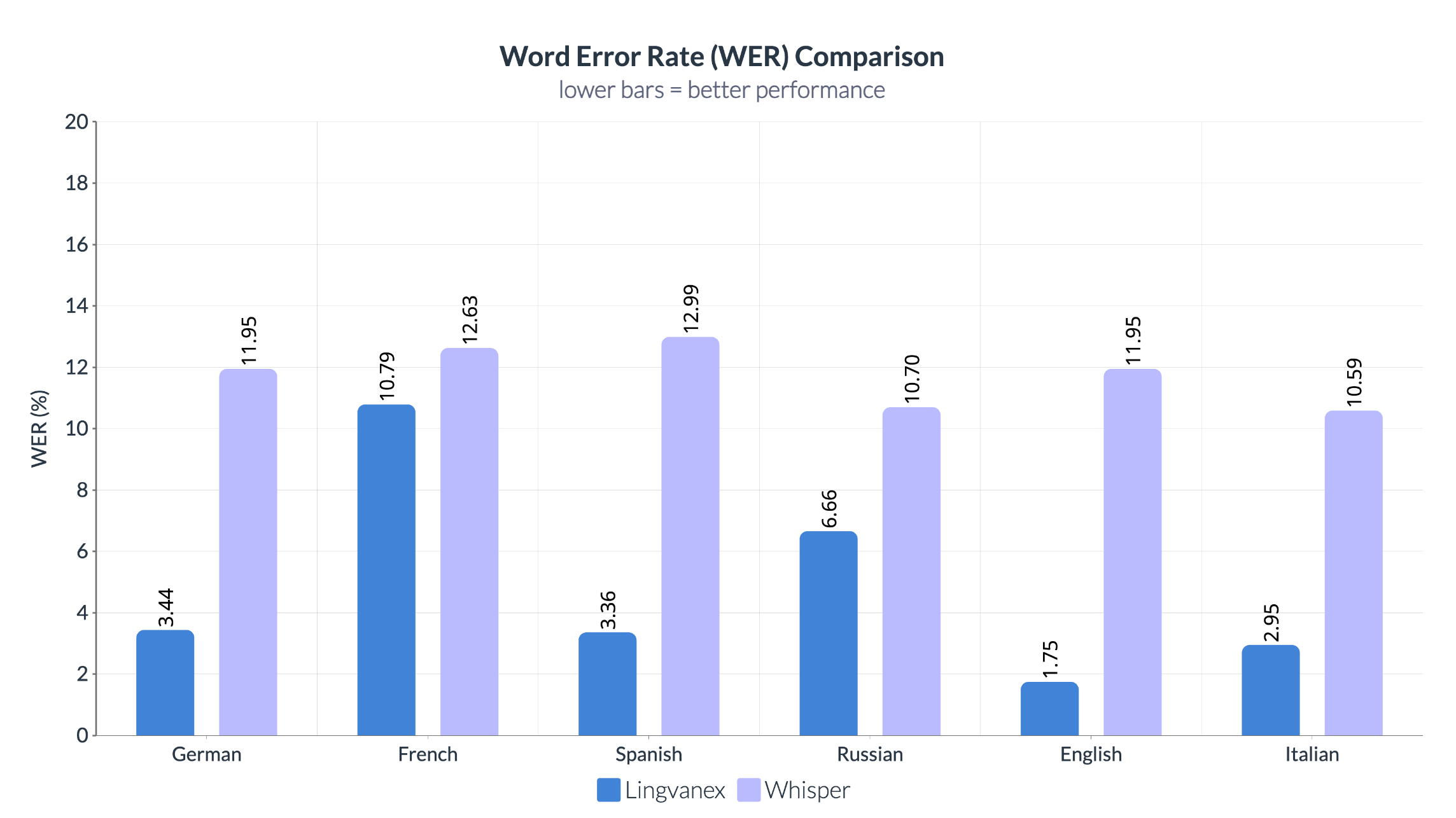
Η σύγκριση του WER μεταξύ Lingvanex και Whisper δείχνει ένα σημαντικό πλεονέκτημα για το σύστημα Lingvanex σε όλες τις γλώσσες. Το Lingvanex καταδεικνύει σταθερά χαμηλά ποσοστά σφάλματος, ιδιαίτερα στα αγγλικά (1,75%) και τα γερμανικά (3,44%), υποδεικνύοντας υψηλή ακρίβεια αναγνώρισης ομιλίας. Αντίθετα, ο Whisper παρουσιάζει σημαντικά υψηλότερες τιμές WER σε όλες τις γλώσσες, υπερβαίνοντας το 10% σε κάθε περίπτωση.
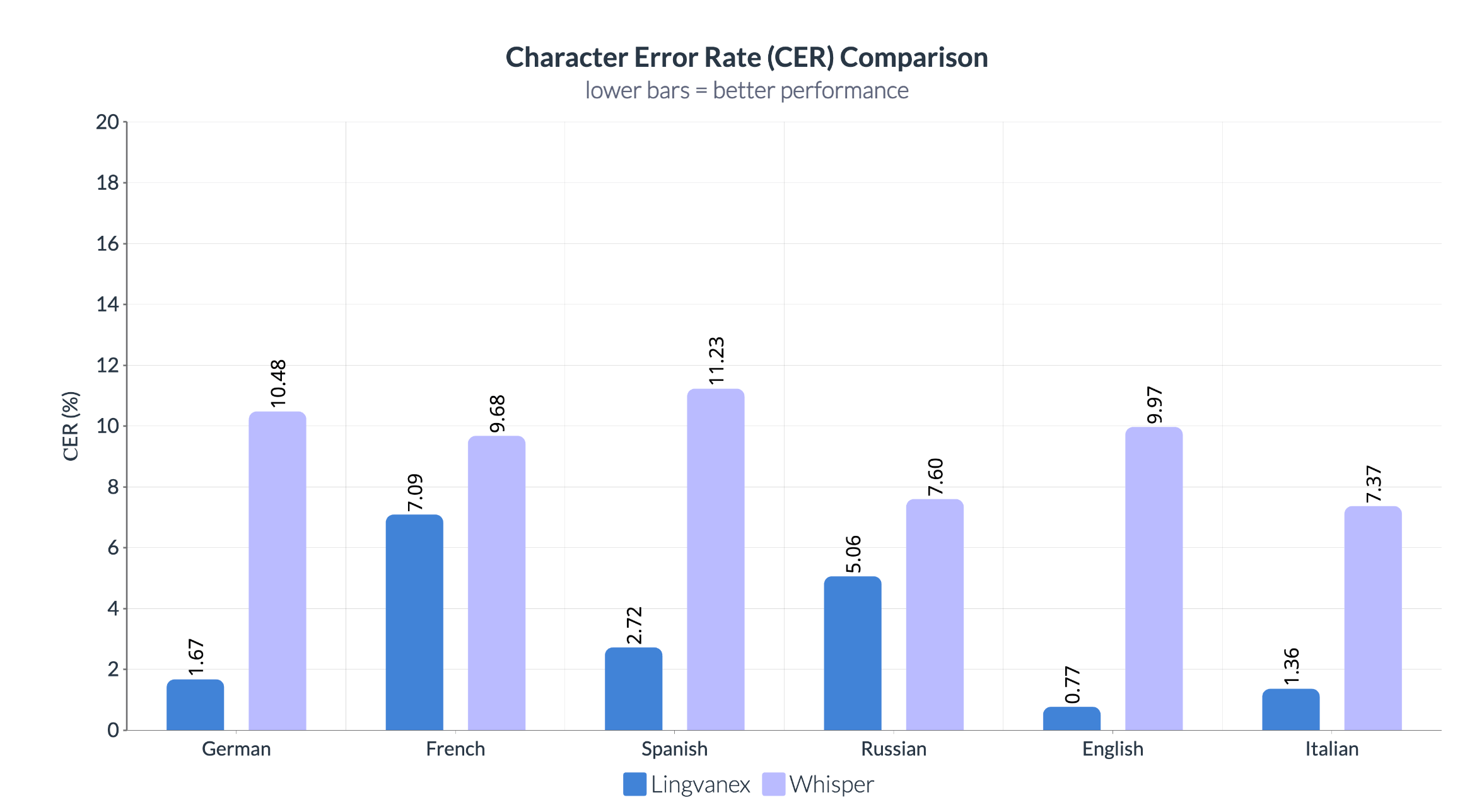
Όσον αφορά το CER, ο Lingvanex υπερβαίνει σημαντικά το ψίθυρο. Το Lingvanex παρουσιάζει ελάχιστα σφάλματα σε επίπεδο χαρακτήρων, ιδιαίτερα στα αγγλικά (0,77%) και τα γερμανικά (1,67%), υπογραμμίζοντας την προσοχή του συστήματος στη λεπτομέρεια και την ακρίβεια. Ο Whisper, από την άλλη πλευρά, παρουσιάζει υψηλές τιμές CER, υποδεικνύοντας λιγότερο ακριβή χειρισμό χαρακτήρων στην ομιλία.
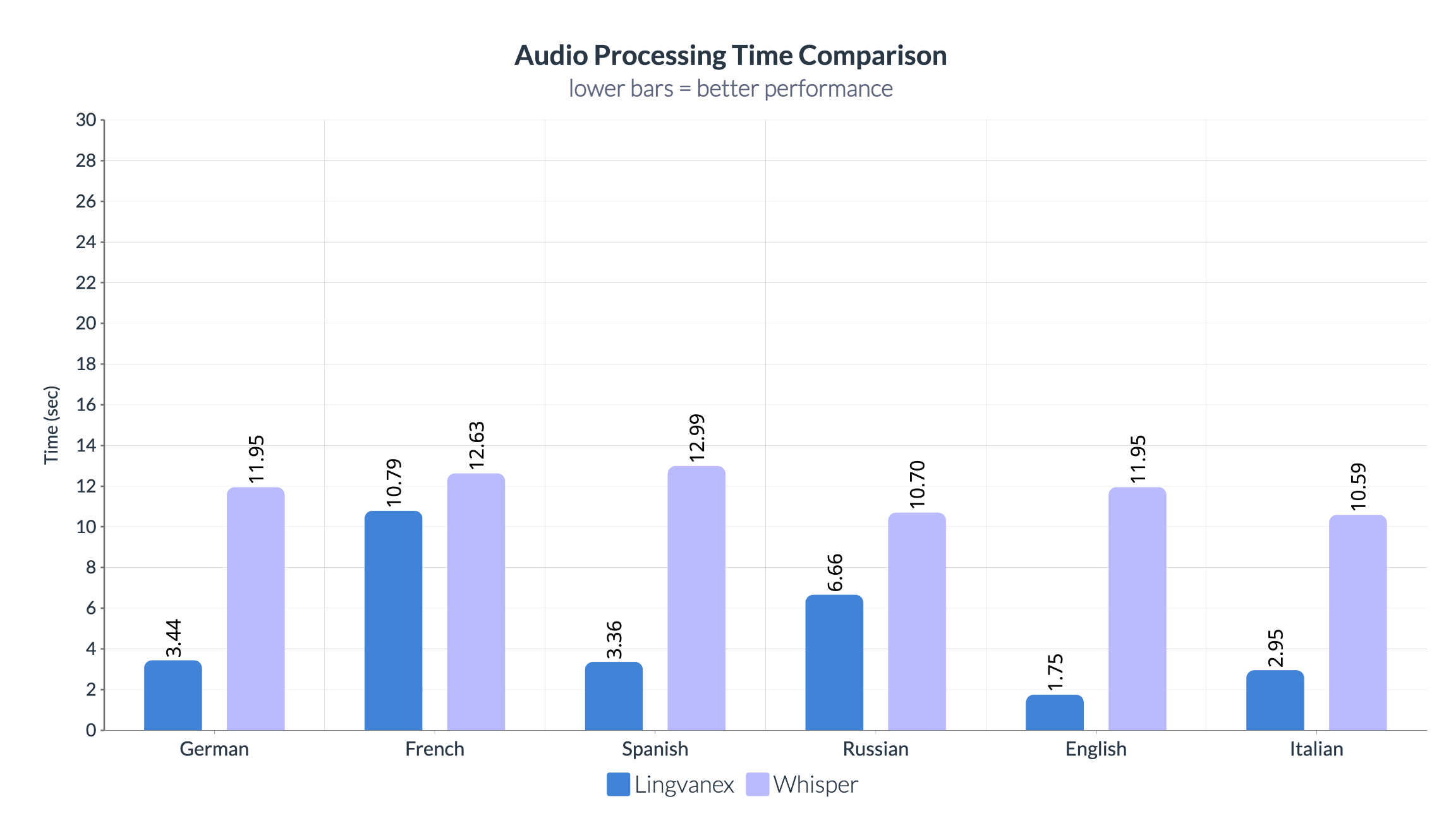
Η σύγκριση του χρόνου επεξεργασίας ήχου μεταξύ Lingvanex και Whisper αποκαλύπτει ένα άλλο σημαντικό πλεονέκτημα Σχετικά με την Lingvanex. Το Lingvanex επεξεργάζεται ένα λεπτό ήχου πολύ πιο γρήγορα από το ψίθυρο. Για παράδειγμα, στην περίπτωση των αγγλικών, το Lingvanex διαρκεί μόνο 3,44 δευτερόλεπτα, ενώ ο Whisper επεξεργάζεται το ίδιο λεπτό ήχου σε 16,33 δευτερόλεπτα.
Με βάση και τις τρεις συγκρίσεις (WER, CER και χρόνο επεξεργασίας), μπορεί να συναχθεί το συμπέρασμα ότι το lingvanex ξεπερνά τον ψιθυριστά σε όλες τις βασικές παραμέτρους . Το Lingvanex προσφέρει πιο ακριβή αναγνώριση ομιλίας τόσο στα επίπεδα λέξεων όσο και στα επίπεδα χαρακτήρων και στις επεξεργασίες ήχου. Αυτά τα πλεονεκτήματα καθιστούν το Lingvanex την προτιμώμενη επιλογή για τις επιχειρήσεις που επιθυμούν να βελτιστοποιήσουν τις φωνητικές τους υπηρεσίες, να ελαχιστοποιήσουν τα σφάλματα και να εξασφαλίσουν υψηλή απόδοση κατά την χειρισμό αρχείων ήχου σε πραγματικό χρόνο.
Lingvanex: Η λύση για τις ανάγκες αναγνώρισης ομιλίας σας
Με βάση τις συγκριτικές δοκιμές και την πραγματική ανατροφοδότηση των πελατών, αρκετά βασικά πλεονεκτήματα του lingvanex λογισμικό αναγνώρισης ομιλίας Μπορεί να επισημανθεί:
- Ευελιξία και προσαρμογή : Προσφέρουμε μοναδικές επιλογές για την προσαρμογή του συστήματος στις συγκεκριμένες ανάγκες των επιχειρήσεων, συμπεριλαμβανομένης της προσαρμογής μοντέλου για απαιτήσεις ορολογίας και ασφάλειας ειδικών για τον τομέα.
- μειωμένος χρόνος επεξεργασίας δεδομένων : Το Lingvanex επιταχύνει σημαντικά την επεξεργασία ήχου. Ένα λεπτό ήχου επεξεργάζεται σε μόλις 3,44 δευτερόλεπτα, το οποίο είναι τάξεις μεγέθους ταχύτερα από τους ανταγωνιστές.
- Η αυξημένη παραγωγικότητα των εργαζομένων : αυτοματοποιώντας τις διαδικασίες αναγνώρισης ομιλίας με το Lingvanex μειώνει το βάρος στο προσωπικό που είχε προηγουμένως χειριστεί χειροκίνητη μεταγραφή.
- Βελτιωμένη εμπειρία πελατών : Lingvanex εξασφαλίζει υψηλής ποιότητας αλληλεπίδραση με τους πελάτες σε όλο τον κόσμο, χάρη στην ακρίβεια του συστήματος στην αναγνώριση των τόνων και των διαλέξεων, καθώς και την ικανότητά του να χειρίζεται τις εγγραφές πολλαπλών οχείς εγγραφές, ακόμη και σε θορυβώδη περιβάλλοντα.
- εξοικονόμηση κόστους στην επεξεργασία δεδομένων : Η υψηλή ακρίβεια και η ταχύτητα του lingvanex μειώνουν το κόστος εξωτερικής ανάθεσης για μεταγραφή και άλλες χειρωνακτικές διαδικασίες που σχετίζονται με την επεξεργασία των φωνητικών δεδομένων.
- Η απρόσκοπτη ενσωμάτωση στις επιχειρηματικές διαδικασίες : Το Lingvanex ενσωματώνεται εύκολα με τα υπάρχοντα συστήματα μέσω API και SDK, επιτρέποντας γρήγορη εφαρμογή χωρίς την ανάγκη πρόσθετης ανάπτυξης ή προσαρμογής.
- Υποστήριξη διαφορετικών μορφών δεδομένων : Το Lingvanex λειτουργεί με ένα ευρύ φάσμα μορφών ήχου, από το Standard WAV και το MP3 έως το πιο εξειδικευμένο OGG και FLV.
- Ασφάλεια δεδομένων: Η Lingvanex προσφέρει λύσεις στο Premise
Σύναψη
Κατά την επιλογή ενός συστήματος αναγνώρισης ομιλίας, οι επιχειρήσεις πρέπει να εξετάσουν πολλούς παράγοντες, από την ακρίβεια και την αντοχή στο θόρυβο για να υποστηρίξουν πολλαπλές γλώσσες και ευελιξία στην ολοκλήρωση. Η Lingvanex ξεχωρίζει ως ηγέτης, προσφέροντας ολοκληρωμένες λύσεις που δεν πληρούν μόνο τα υψηλότερα πρότυπα αλλά είναι επίσης εύκολα προσαρμόσιμες στις μοναδικές ανάγκες κάθε επιχείρησης.
Οι εταιρείες που έχουν ήδη εφαρμόσει το Lingvanex ήταν σε θέση να λύσουν προβλήματα που δεν μπορούσαν να χειριστούν άλλα συστήματα - είτε συνεργάζεται με τόνους, θόρυβο ή σύνθετες ορολογίες. Δεν προσφέρουμε ένα εργαλείο ενός μεγέθους. Δημιουργούμε ένα σύστημα που λαμβάνει υπόψη τις λεπτομέρειες κάθε πελάτη, παρέχοντας αποτελέσματα στα οποία μπορείτε να βασιστείτε.
Το Lingvanex δεν είναι μόνο η τεχνολογία - είναι ένα εργαλείο που βοηθά την επιχείρησή σας να λειτουργεί καλύτερα, ταχύτερα και με μεγαλύτερη ακρίβεια. Εάν στοχεύετε στη βελτίωση των βασικών διαδικασιών που βασίζονται σε δεδομένα φωνής και θέλετε να δείτε πραγματικά αποτελέσματα και όχι θεωρητικές υποσχέσεις, η Lingvanex θα είναι ο αξιόπιστος συνεργάτης σας.
Συχνές ερωτήσεις (FAQ)
Ποια είναι τα παραδείγματα αναγνώρισης ομιλίας;
Η αναγνώριση ομιλίας χρησιμοποιείται ευρέως σε διάφορες βιομηχανίες. Τα κοινά παραδείγματα περιλαμβάνουν εικονικούς βοηθούς όπως το Siri, το Google Assistant και το Amazon Alexa που βοηθούν τους χρήστες με φωνητικές εντολές. Στην εξυπηρέτηση πελατών, τα αυτοματοποιημένα συστήματα τηλεφωνικών κέντρων μεταγράφουν και κατανοούν τις ερωτήσεις πελατών σε άμεσες κλήσεις. Οι υπηρεσίες ομιλίας σε κείμενο χρησιμοποιούνται για τη μεταγραφή συναντήσεων, διαλέξεων ή συνεντεύξεων. Επιπλέον, τα συστήματα που ενεργοποιούνται με φωνή σε αυτοκίνητα, έξυπνες συσκευές και εργαλεία υπαγόρευσης για τη δημιουργία εγγράφων είναι επίσης παραδείγματα τεχνολογίας αναγνώρισης ομιλίας.
Ποιος είναι ο σκοπός της αναγνώρισης ομιλίας;
Ο πρωταρχικός σκοπός της αναγνώρισης του λόγου είναι να δοθεί η δυνατότητα στους υπολογιστές και τις συσκευές να κατανοούν και να επεξεργάζονται την προφορική γλώσσα. Αυτό επιτρέπει στους χρήστες να αλληλεπιδρούν με την τεχνολογία πιο φυσικά, μέσω φωνητικών εντολών, βελτιώνοντας την προσβασιμότητα και την αποτελεσματικότητα. Χρησιμοποιείται για την ενίσχυση της παραγωγικότητας (π.χ. δακτυλογράφηση φωνής), τη βελτίωση της εξυπηρέτησης πελατών (π.χ. αυτοματοποιημένα συστήματα φωνητικής απόκρισης) και επιτρέπει τον έλεγχο χωρίς χέρια σε συσκευές όπως smartphones, έξυπνα ηχεία και συσκευές IoT (Internet of Things).
Ποιες είναι οι τεχνικές που χρησιμοποιούνται στην αναγνώριση ομιλίας;
Η αναγνώριση ομιλίας χρησιμοποιεί διάφορες τεχνικές:
- Ακουστική μοντελοποίηση: Χάρτες Σημειώσεις ομιλίας σε φωνητικές μονάδες, βοηθώντας το σύστημα να διακρίνει μεταξύ διαφορετικών ήχων.
- Μοντελοποίηση γλωσσών: Προβλέπει ακολουθίες λέξεων με βάση τις πιθανότητες, συμβάλλοντας στη δημιουργία σημαντικών φράσεων από την αναγνωρισμένη ομιλία.
- Εξαγωγή χαρακτηριστικών: αναλύει τα σήματα ήχου και τα χαρακτηριστικά εκχυλίσματος όπως το βήμα, η συχνότητα και η ένταση για επεξεργασία.
- Αλγόριθμοι μηχανικής μάθησης: Τα κρυμμένα μοντέλα Markov (HMMS) και τα βαθιά νευρωνικά δίκτυα (DNNs) χρησιμοποιούνται ευρέως για τη βελτίωση της ακρίβειας με τη μάθηση από μεγάλα σύνολα δεδομένων της ομιλούμενης γλώσσας.
Ποια είναι τα βασικά στοιχεία της αναγνώρισης ομιλίας;
Η αναγνώριση ομιλίας αρχίζει με τη λήψη εισόδου ήχου, συχνά μέσω ενός μικροφώνου. Αυτός ο ήχος μετατρέπεται σε ψηφιακό σήμα, το οποίο στη συνέχεια αναλύεται από το σύστημα για την ανίχνευση μοτίβων ομιλίας και την εξαγωγή φωνητικών στοιχείων. Χρησιμοποιώντας τα μοντέλα γλώσσας, το σύστημα προβλέπει τις πιο πιθανές ακολουθίες λέξεων με βάση το πλαίσιο και στη συνέχεια μετατρέπει τους ήχους σε γραπτό κείμενο ή ενέργειες. Η τεχνολογία εξαρτάται σε μεγάλο βαθμό από τα μοντέλα εκπαίδευσης και μηχανικής μάθησης για να βελτιώσει την ακρίβεια και να προσαρμοστεί σε διαφορετικούς τόνους, γλώσσες και στυλ ομιλίας.
↑Περισσότερες διαβάσει αναμονή
×


