
Σε αυτό το άρθρο, θα βυθίσουμε στους μηχανισμούς αρχιτεκτονικής και λειτουργίας του αποκωδικοποιητή σε μοντέλα μετασχηματιστών, τα οποία είναι αναπόσπαστα σε εργασίες όπως η γλωσσική μετάφραση και η παραγωγή κειμένου. Θα περιγράψουμε τη διαδοχική επεξεργασία των πινάκων εισόδου, ξεκινώντας από τις ενσωματωμένες ενσωμάτωση που κλιμακώνονται από τον αριθμό των μονάδων, μέσω της εφαρμογής της εγκατάλειψης για την τακτοποίηση και της δημιουργίας μελλοντικών και μνήμης μνήμης. Αυτά τα βήματα εξασφαλίζουν ότι ο αποκωδικοποιητής μπορεί να διαχειριστεί αποτελεσματικά το πλαίσιο και τις εξαρτήσεις εντός των ακολουθιών.
Θα εξετάσουμε επίσης τη σειρά μετασχηματισμών που εμφανίζονται σε κάθε στρώμα του αποκωδικοποιητή, συμπεριλαμβανομένων των διαδικασιών αυτο-επιτυχίας και διασταυρούμενης προσοχής. Αυτό περιλαμβάνει τον υπολογισμό των ερωτημάτων, των κλειδιών και των τιμών, καθώς και την εφαρμογή της ομαλοποίησης και της εγκατάλειψης σε διάφορα στάδια. Τέλος, θα συζητήσουμε πώς οι εξόδους από τον αποκωδικοποιητή μετατρέπονται σε logits, έτοιμα για τη δημιουργία προβλέψεων και επισημαίνουν την ακολουθία κλήσεων των λειτουργιών και των τάξεων που ενορχηστρώσουν αυτές τις πολύπλοκες λειτουργίες. Μέσα από αυτή την εξερεύνηση, στοχεύουμε να παρέχουμε μια ολοκληρωμένη κατανόηση του ρόλου του αποκωδικοποιητή στις αρχιτεκτονικές μετασχηματιστή.
Αποκρυπτογράφος
Σε διάνυσμα Decoder Prective of Tokens Στόχος γλώσσα:
Ο παράγοντας (στο παράδειγμα μας NUM_UNITS = 4) → (Εικόνα 1 - num_units) 
Dropout εφαρμόζεται ( παράσταση από το αρχείο διαμόρφωσης). (Εικόνα 2 - εγκατάλειψη)
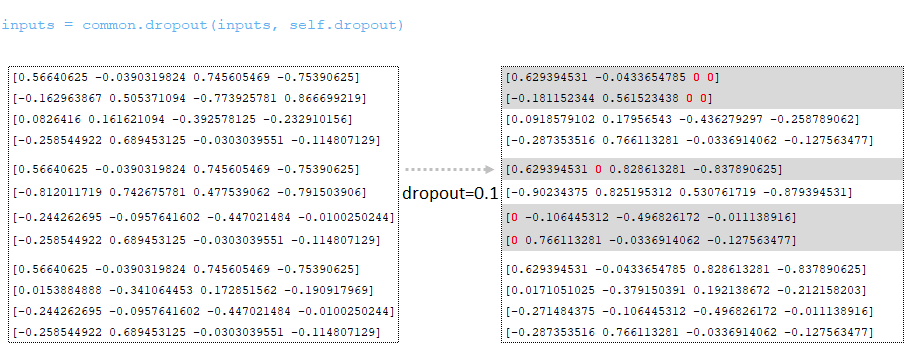
Σχετικά με τη διαστασιότητα των παρτίδων Matrix href = 'https://github.com/opennmt/opennmt-tf/blob/6f3b952ebbb973dec31250a806bf0f56ff730d0b5/opennmt/layers/transformer.py#l21'> future_mask Το Tensor είναι χτισμένο με το future_mask. Κατά την κατάρτιση του αποκωδικοποιητή, τα μελλοντικά σημάδια της ακολουθίας θα είναι κρυμμένες, ο αποκωδικοποιητής έχει πρόσβαση μόνο στο τρέχον διακριτικό και τα προηγούμενα μάρκες. (Εικόνα 3 - Future_mask) 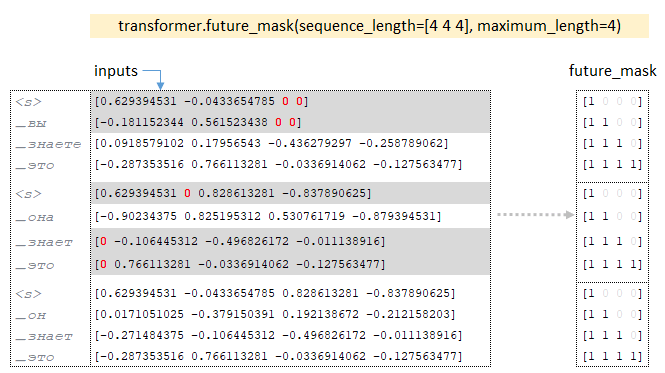
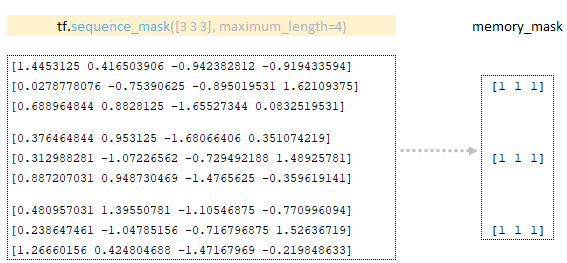
memory_mask tensor σχηματίζεται χρησιμοποιώντας τη μήτρα που λαμβάνεται στον κωδικοποιητή χρησιμοποιώντας τη λειτουργία tf.equence_mask. (Εικόνα 4 - Memory_mask)
Στον βρόχο, για κάθε στρώμα , ίσο με τον αριθμό των παραμέτρων, το encoder , το encoder encoder . Επιστρέφεται από Layer - Οι εισόδους μεταφέρονται στο επόμενο Layer . Για παράδειγμα, εάν έχουμε 6 στρώματα, το αποτέλεσμα από το πρώτο στρώμα θα είναι το αποτέλεσμα εισόδου για το δεύτερο στρώμα, κλπ. Από κάθε στρώμα, το στρώμα που σχηματίζεται στο cross_attention (Εικόνα 5 - Matrix προσοχής)

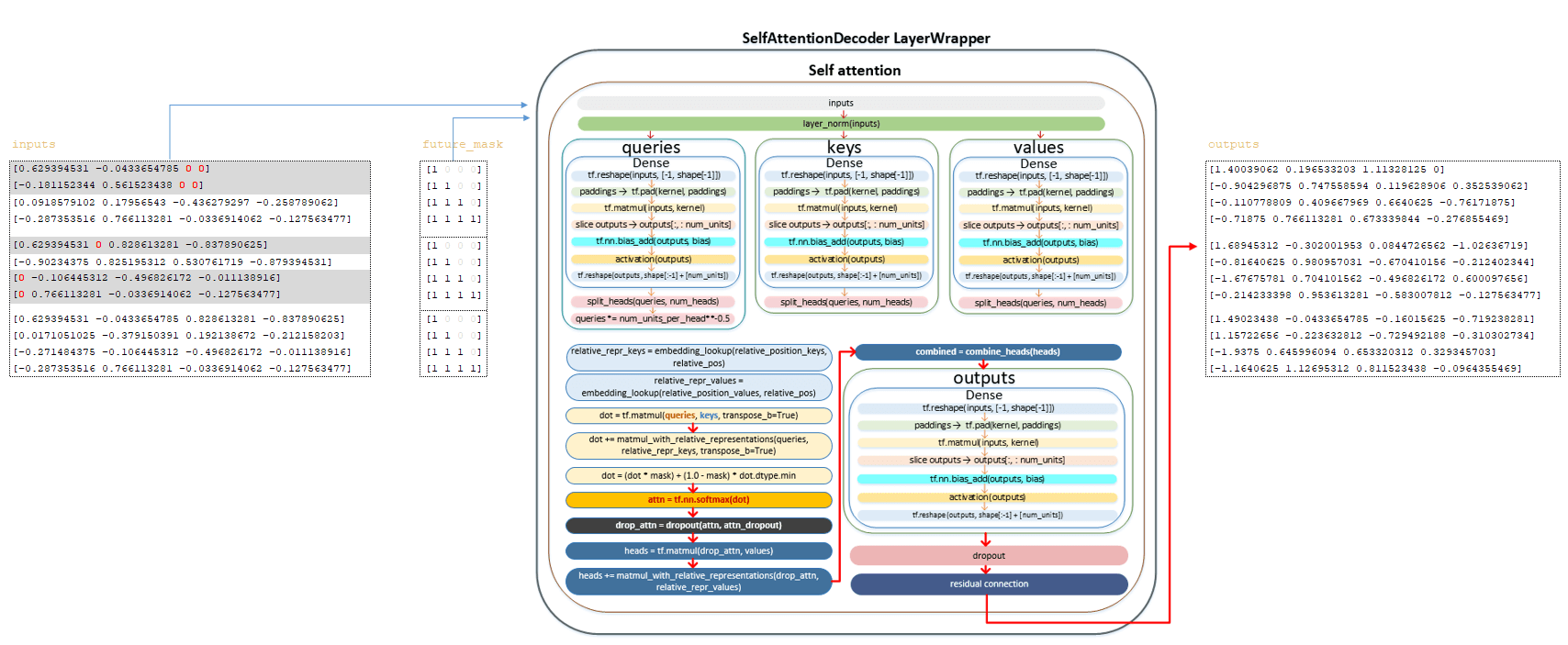
Σε κάθε στρώμα, πραγματοποιούνται οι μετασχηματισμοί που περιγράφονται παρακάτω. εισόδους matrix και matrix μετασχηματίζονται με τη χρήση του στρώματος . Ο πλήρης μηχανισμός των μετασχηματισμών μήτρας περιγράφεται στην ενότητα κωδικοποιητή. Εδώ απαριθμούμε τα κύρια βήματα:
━ 1) Η μήτρα εισόδου περνάει μέσω του στρώματος κανονικοποίησης.
━ 2) Η μήτρα των ερωτημάτων υπολογίζεται και διαιρείται με τον αριθμό των κεφαλών.
━ 3) Τα ερωτήματα που διαιρούνται από τον αριθμό των κεφαλών διαιρείται με την τετραγωνική ρίζα του num_units_per_head ;
━ 4) Τα πλήκτρα Matrix υπολογίζονται και διαιρούνται από τον αριθμό των κεφαλών.
━ 5) Οι τιμές Matrix υπολογίζονται και διαιρούνται από τον αριθμό των κεφαλών.
━ 6) relative_repr_keys και relative_repr_values Οι μήτρες υπολογίζονται.
━ 7) Το κλιμακωτό προϊόν των queries και αποκτάται .
━ 8) Τα ερωτήματα πολλαπλασιάζονται με το matrix relative_repr_key ;
━ 9) matrix matmul_with_relative_representations προστίθεται στο κλιμακωτό προϊόν των πινάκων.
━ 10) μετασχηματισμός με matrix future_mask ;
━ 11) Η λειτουργία ενεργοποίησης SoftMax εφαρμόζεται.
━ 12) dropout εφαρμόζεται (παράμετρος προσοχή_dropout από το αρχείο διαμόρφωσης).
━ 13) πολλαπλασιασμός με τις τιμές για να σχηματίσουν τις κεφαλές ;
━ 14) πολλαπλασιασμός με το matrix relative_repr_values ;
━ 15) προσθήκη των κεφαλών με το matrix matmul_with_relative_representations ;
━ 16) Συνδυάζοντας κεφαλές (Matrix κεφαλές ) σε μια κοινή μήτρα.
━ 17) Γραμμικός μετασχηματισμός.
━ 18) Dropout Εφαρμοσμένη ( Παράμετρος από το αρχείο διαμόρφωσης).
━ 19) Εφαρμοσμένη υπολειμματική σύνδεση .
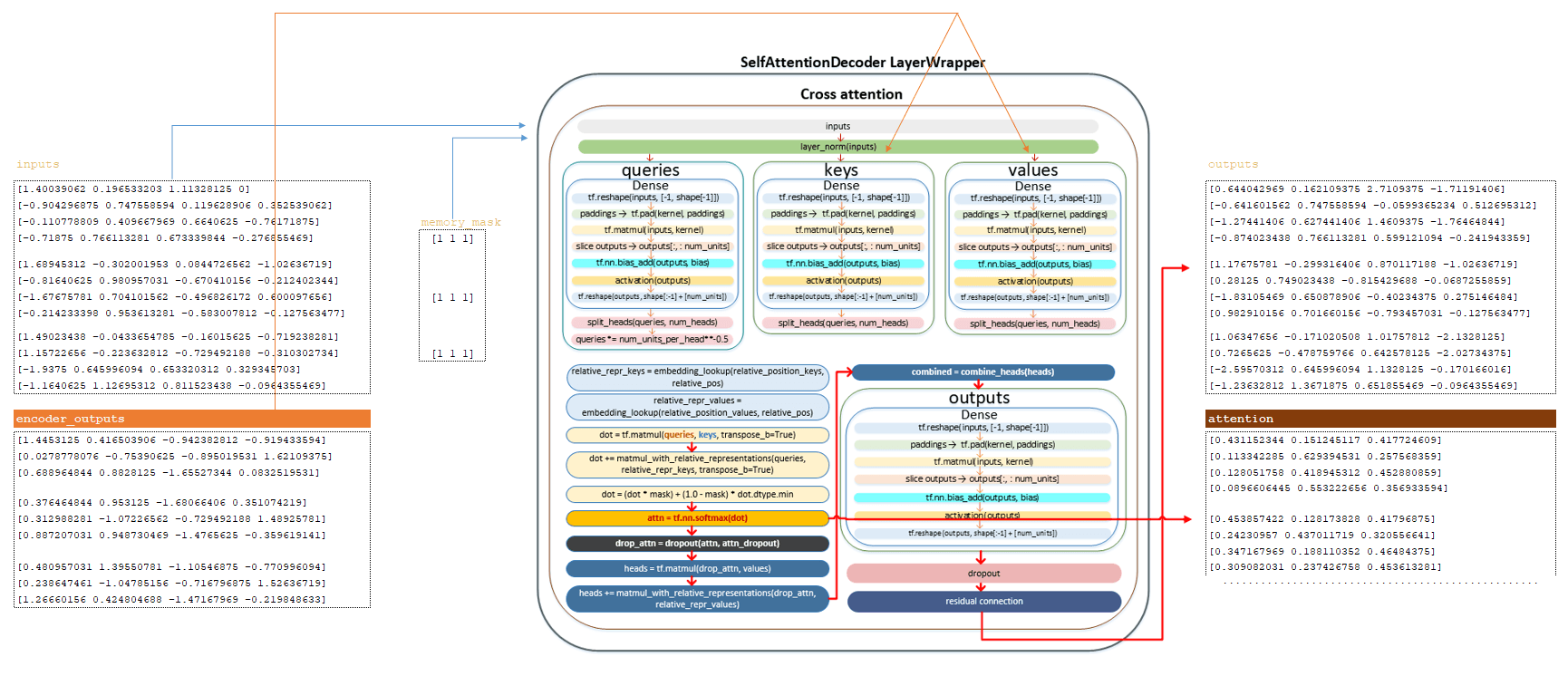
Μετά τους παραπάνω μετασχηματισμούς, λαμβάνουμε το Matrix . (Εικόνα 6 - Έξοδος Matrix)
Η μήτρα μετά το στρώμα self προσοχή , το matrix memory_mask και η μήτρα που λαμβάνεται σε encoder_outputs τροφοδοτούνται στην είσοδο του στρώματος cross .
Ο πλήρης μηχανισμός των μετασχηματισμών μήτρας περιγράφεται στην ενότητα κωδικοποιητή. Εδώ θα απαριθμήσουμε τα κύρια βήματα:
━ 1) Οι εισόδους περνούν μέσω του στρώματος κανονικοποίησης.
━ 2) Η μήτρα των ερωτημάτων υπολογίζεται και διαιρείται με τον αριθμό των κεφαλών.
━ 3) Τα ερωτήματα που διαιρούνται από τον αριθμό των κεφαλών διαιρείται με την τετραγωνική ρίζα του num_units_per_head ;
━ 4) Το πλήκτρο υπολογίζεται από το κωδικοποιητή Matrix και διαιρείται με τον αριθμό των κεφαλών.
━ 5) Οι τιμές υπολογίζονται χρησιμοποιώντας το matrix κωδικοποιητή και διαιρούνται με τον αριθμό των κεφαλών.
━ 6) Η μήτρα relative_repr_keys και relative_repr_values υπολογίζεται.
━ 7) Το κλιμακωτό προϊόν των queries και αποκτάται .
━ 8) Η μήτρα των ερωτημάτων πολλαπλασιάζεται με τη μήτρα relative_repr_key ;
━ 9) matrix matmul_with_relative_representations προστίθεται στο κλιμακωτό προϊόν των πινάκων.
━ 10) μετασχηματισμός με matrix memory_mask ;
━ 11) Η συνάρτηση ενεργοποίησης SoftMax εφαρμόζεται, λαμβάνουμε το matrix που επιστρέφεται από αυτό το στρώμα .
━ 12) dropout εφαρμόζεται (παράμετρος προσοχή_dropout από το αρχείο διαμόρφωσης).
━ 13) πολλαπλασιασμός με τις τιμές για να σχηματίσουν τις κεφαλές matrix;
━ 14) πολλαπλασιασμός με το matrix relative_repr_values ;
━ 15) προσθήκη των κεφαλών με το matrix matmul_with_relative_representations ;
━ 16) Συνδυάζοντας κεφαλές (Matrix κεφαλές ) σε μια κοινή μήτρα.
━ 17) Γραμμικός μετασχηματισμός.
━ 18) dropou t Εφαρμοσμένη ( Παράμετρος από το αρχείο διαμόρφωσης).
━ 19) Εφαρμοσμένη υπολειμματική σύνδεση .
Μετά τους παραπάνω μετασχηματισμούς, λαμβάνουμε το Matrix και το Matrix . (Εικόνα 7 - Έξοδοι και μήτρα προσοχής)
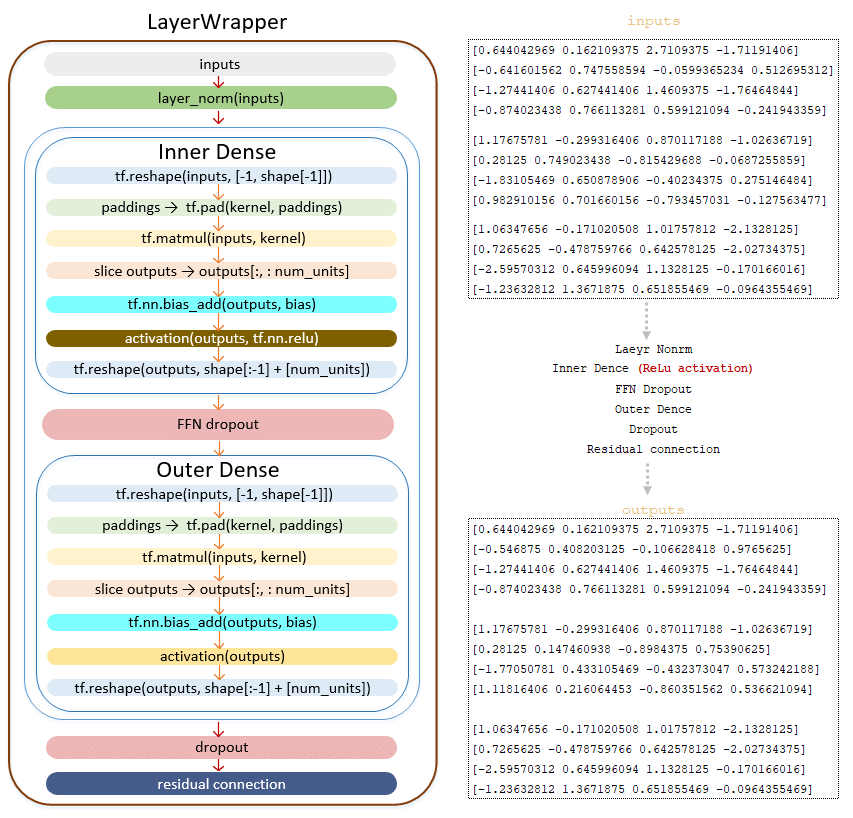
Το Matrix Έξοδοι μεταβιβάζεται στο δίκτυο Feed Feed :
━ 1) εφαρμόζεται το στρώμα κανονικοποίησης layernorm ().
━ 2) Κατηγορία γραμμικού μετασχηματισμού (). Ο γραμμικός μετασχηματισμός με τη συνάρτηση ενεργοποίησης Relu tf.nn.relu ;
━ 3) Dropout εφαρμόζεται (παράμετρος ffn_dropout από το αρχείο διαμόρφωσης).
━ 4) Γραμμικός μετασχηματισμός της κλάσης πυκνό ().
━ 5) dropout εφαρμόζεται ( παράσταση από το αρχείο διαμόρφωσης).
━ 6) Εφαρμοσμένος υπολειμματικός μηχανισμός σύνδεσης.
(Εικόνα 8 - outputs_matrix)
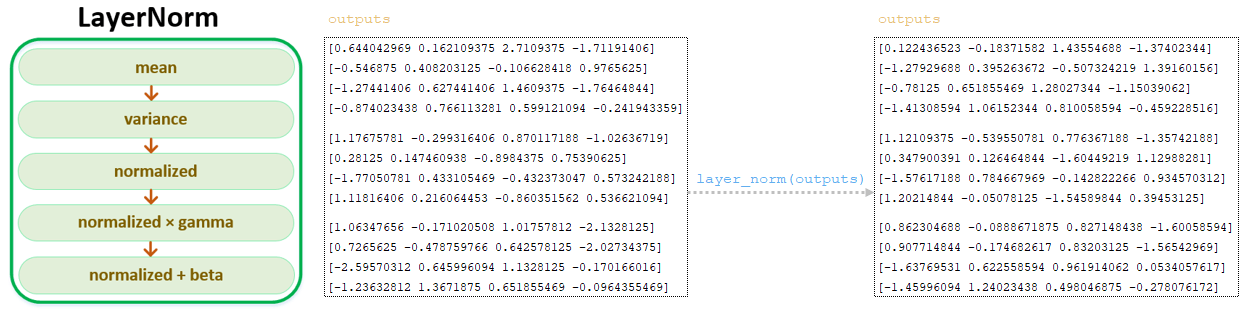
Αφού μετασχηματίζεται η μήτρα με τη χρήση του δικτύου Feed Fread Forward, η προκύπτουσα outputs περάσει το στρώμα κανονικοποίησης layernorm (). (Εικόνα 9 - layernorm)
Η σειρά των πινάκων από κάθε στρώμα μετασχηματίζεται χρησιμοποιώντας την καθορισμένη στρατηγική επεξεργασίας. Η προεπιλεγμένη στρατηγική είναι first_head_last_layer , δηλαδή ο πίνακας που θα ληφθεί στο τελευταίο στρώμα θα ληφθεί και το πρώτο κεφάλι θα ληφθεί από αυτή τη μήτρα. (Εικόνα 10 - Μεγαλοποίηση πολλαπλών προδιαγραφών)

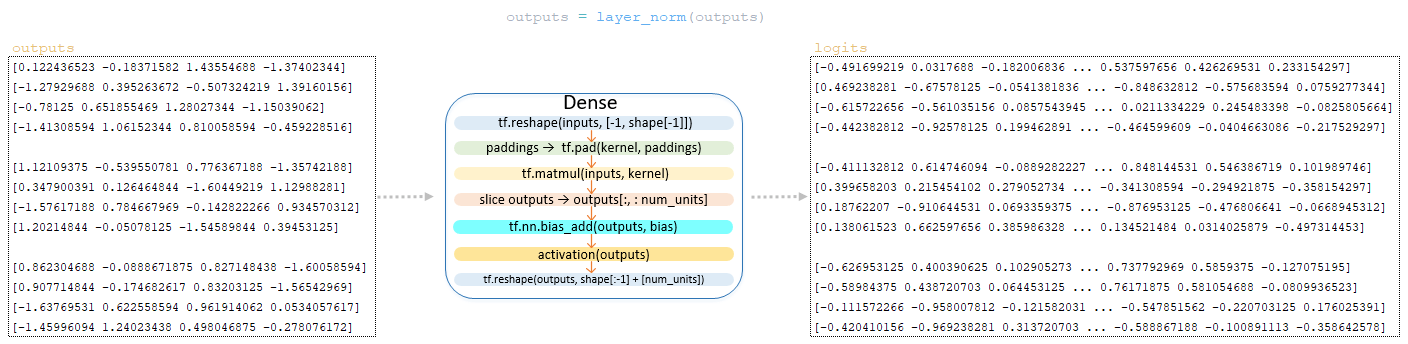
Το outputs matrix μετά το στρώμα κανονικοποίησης μετασχηματίζεται από το γραμμικό στρώμα εξόδου του αποκωδικοποιητή, του οποίου η διάσταση είναι vocab_size x num_units (στο παράδειγμα μας 26 x 4) Αυτός ο μετασχηματισμός στον αποκωδικοποιητή είναι η τελική λειτουργία. (Εικόνα 11 - Matrix Logits)
Έτσι, μετά από μετασχηματισμούς στον αποκωδικοποιητή του Target tokens γλωσσών στην έξοδο του αποκωδικοποιητή, έχουμε δύο μήτρες - το πλέγμα των logits και της μήτρας των τιμών προσοχής από το τελευταίο στρώμα Cross Petice . Σχηματικά, ο πλήρης κύκλος των μετασχηματισμών στον αποκωδικοποιητή μπορεί να εκπροσωπηθεί ως εξής. (Εικόνα 12 - Πλήρης κύκλος μετατροπών στον αποκωδικοποιητή)
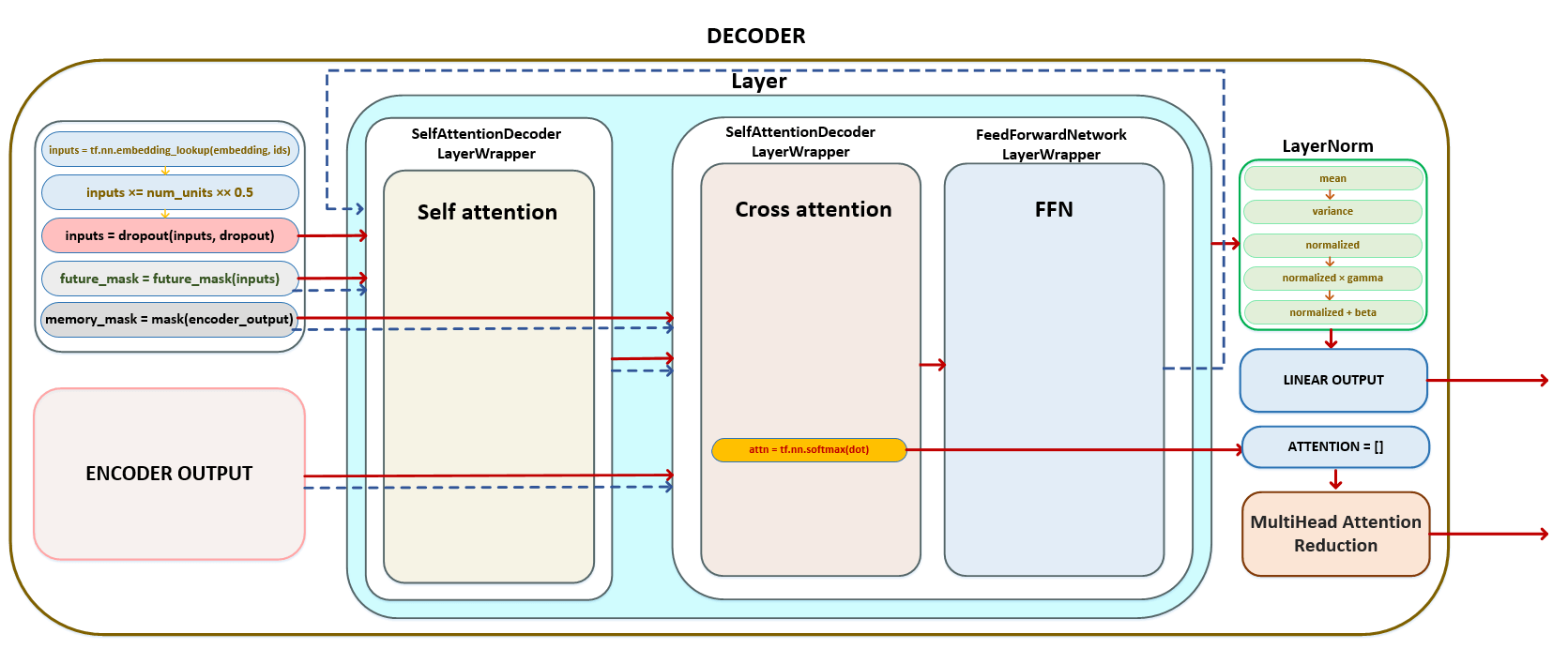
αποκωδικοποιητής. Απλοποιημένη ακολουθία κλήσεων:
├ .. def call () | Μοντέλο κλάσης (tf.keras.layers.layer) module model.py
├ .. def call () | Κατηγορία SequenceTosequence (Model.SequenceGenerator) Μονάδα sequence_to_sease.py
├ .. def _decode_target () | Κατηγορία SequenceTosequence (Model.SequenceGenerator) Μονάδα sequence_to_sease.py
├ .. def call () | κλάση WordEmbedder (TextInputter) Μονάδα text_inputter.py
├ .. def call () | αποκωδικοποιητής κλάσης (tf.keras.layers.layer) module decoder.py
├ .. deftrade () | class selfAttentionDecoder (decoder.decoder) module self_attention_decoder.py
├ .. module self_attention_decoder.py ├ .. def call () | Class SelfAttentionDecoderlayer (tf.keras.layers.layer) Μονάδα Layers/Transformer.py ├ .. def call () | Κατηγορία Multiheadattention (tf.keras.layers.layer) Μονάδα Layers/Transformer.py ├ .. def call () | Κατηγορία Multiheadattention (tf.keras.layers.layer) Μονάδα Layers/Transformer.py ├ .. def call () | Κατηγορία feedforwardnetwork (tf.keras.layers.layer) Μονάδα layers/transformer.py ├ .. def redaive () | Κατηγορία MultiHeadattentionReduction Μονάδα Layers/Transformer.py