
Η διαδικασία αρχικοποίησης είναι το κρίσιμο πρώτο βήμα για την εκπαίδευση ενός μοντέλου, θέτοντας τα θεμέλια για τα επόμενα στάδια εκπαίδευσης. Αυτή η περίπλοκη διαδικασία περιλαμβάνει πολλά βασικά βήματα, το καθένα από τα οποία εκτελείται διαδοχικά ώστε το μοντέλο να διαμορφωθεί σωστά και να λειτουργεί κανονικά.
Μέσα από αυτήν τη δομημένη αρχικοποίηση, το μοντέλο όχι μόνο προετοιμάζεται για εκπαίδευση, αλλά και βελτιστοποιείται για απόδοση, θέτοντας τη βάση για αποδοτική μάθηση και ακριβείς προβλέψεις. Το παρόν άρθρο περιγράφει αναλυτικά τα βήματα της φάσης αρχικοποίησης και παρέχει πληροφορίες για τους υποκείμενους μηχανισμούς και ρυθμίσεις που συμβάλλουν στην επιτυχημένη εκπαίδευση μοντέλου.
Διαδικασία Αρχικοποίησης
Η εκπαίδευση μοντέλου ξεκινά με την αρχικοποίηση της διαδικασίας. Τα παρακάτω βήματα εκτελούνται διαδοχικά κατά την έναρξη της εκπαίδευσης:
- το αρχείο ρυθμίσεων διαβάζεται και οριστικοποιείται (ενώνεται το auto_config και το user config);
├── config = self._finalize_config() αρχείο runner.py
├── def _finalize_config() αρχείο runner.py
├── def auto_config() αρχείο transformer.py
- ορίζεται ο τύπος υπολογισμού του tensorflow;
Κατά την εκπαίδευση με μεικτή ακρίβεια (FP16), περνάμε την εντολή set_global_policy(“mixed_float16”) στο tensorflow.
├── mixed_precision = self._mixed_precision και misc.enable_mixed_precision() αρχείο runner.py
├── def enable_mixed_precision() αρχείο misc.py
- αρχικοποιείται το μοντέλο Transformer (ή άλλου τύπου, όπως έχει οριστεί από τον χρήστη);
Το μοντέλο αρχικοποιείται μόνο αφού έχει οριστεί ο τύπος υπολογισμού, επειδή ο τύπος αυτός είναι σταθερός στα ιδιωτικά attributes του μοντέλου.
Αν αρχικοποιήσεις το μοντέλο πριν από την αρχικοποίηση του τύπου υπολογισμού, οι τιμές στα attributes του μοντέλου δεν θα αλλάξουν και θα παραμείνουν ως προεπιλογή float32:
_dtype_policy: <Policy “float32”>
_compute_dtype_object: <dtype: 'float32'>
├── model = self._init_model (config) αρχείο runner.py"
├── def _init_model() runner.py
- ο βελτιστοποιητής του μοντέλου ορίζεται και αρχικοποιείται;
Από το autoconfig του μοντέλου Transformer λαμβάνεται το όνομα του βελτιστοποιητή, που από προεπιλογή είναι το LazyAdam. Αυτός ο βελτιστοποιητής υλοποιείται στη βιβλιοθήκη TensorFlow Addons.
Η συνάρτηση εξασθένησης NoamDecay αρχικοποιείται με τις παρακάτω παραμέτρους:
━ 1) scale - καθορίζεται από την παράμετρο Learning rate του αρχείου ρυθμίσεων εκπαίδευσης (στο παράδειγμά μας είναι 2);
━ 2) model_dim - τιμή από την παράμετρο num_units (Rnn size) του αρχείου ρυθμίσεων (στο παράδειγμά μας είναι 4);
━ 3) warmup_steps - τιμή από την παράμετρο Warmup steps του αρχείου ρυθμίσεων (στο παράδειγμά μας είναι 8000).
Η κλάση περιτυλίγματος ScheduleWrapper αρχικοποιείται για επέκταση της συμπεριφοράς του προγραμματιστή learning rate με τις παρακάτω παραμέτρους:
━ 1) schedule - η προηγουμένως αρχικοποιημένη συνάρτηση NoamDecay;
━ 2) step_start - τιμή από την παράμετρο start_decay_steps (προεπιλογή: 0);
━ 3) step_duration - τιμή από την παράμετρο decay_step_duration (προεπιλογή: 1);
━ 4) minimum_learning_rate - τιμή από την παράμετρο Minimum learning rate (στο παράδειγμά μας: 0.0001).
Η κλάση βελτιστοποιητή LazyAdam αρχικοποιείται με τις παρακάτω παραμέτρους:
━ 1) learning_rate - χρησιμοποιεί την προηγουμένως αρχικοποιημένη ScheduleWrapper;
━ 2) kwargs - λεξικό συντελεστών beta από την παράμετρο optimizer_params (στο παράδειγμά μας {'beta_1': 0.9, 'beta_2': 0.998});
━ 3) όταν γίνεται εκπαίδευση με μεικτή ακρίβεια (FP16), η LazyAdam κληρονομεί από την tf.keras.mixed_precision.LossScaleOptimizer και αρχικοποιεί:
- initial_scale = 32 768 - η τιμή που διορθώνει την έξοδο της loss συνάρτησης;
- dynamic_growth_steps = 2 000 - πόσο συχνά ενημερώνεται η τιμή διόρθωσης.
├── optimizer = model.get_optimizer() αρχείο runner.py
├── def get_optimizer() αρχείο model.py
├── def make_learning_rate_schedule() αρχείο schedules/lr_schedules.py
├── def init() class NoamDecay (tf.keras.optimizers.schedules.LearningRateSchedule) αρχείο schedules/lr_schedules.py
├── def init() class ScheduleWrapper schedules/lr_schedules.py
├── def make_optimizer() αρχείο optimizers/utils.py
- ορίζεται η batch_size_multiple;
Αν είναι ενεργοποιημένες οι λειτουργίες Mixed precision ή Jit compile, τότε batch_size_multiple είναι 8, διαφορετικά 1.
├── batch_size_multiple = (...) αρχείο runner.py
- δημιουργείται συνάρτηση για δημιουργία και μετατροπή dataset;
├── dataset_fn = (...) αρχείο runner.py
- αν οριστεί η τιμή effective_batch_size, υπολογίζεται η τιμή στην οποία θα ενημερώνεται το gradient;
├── accum_steps = _count_batch_accum() αρχείο runner.py
├── def _count_batch_accum() αρχείο runner.py
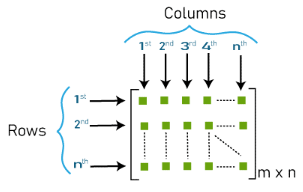
- αρχικοποιούνται τα embeddings για source και target;
Η διάσταση των embeddings καθορίζεται από το μέγεθος του λεξικού και την παράμετρο num_units (Rnn size), όπου m αριθμός tokens, n τιμή num_units. (Εικόνα 1 - matrix_m_n)
Τα embeddings αρχικοποιούνται μέσω αντικειμένου tf.keras.Layer, με τη χρήση της add_weight function, η οποία καλείται από τη def build() της κλάσης WordEmbedder.
├── source_inputter = inputters.WordEmbedder(embedding_size=num_units)
├── def build()
├── target_inputter = inputters.WordEmbedder(embedding_size=num_units)
├── def build()
Για παράδειγμα, για λεξικό με 700 tokens και num_units (Rnn size) ίσο με 8, δημιουργείται πίνακας 700 γραμμών και 8 αριθμών ανά γραμμή. Τα embeddings μοιάζουν ως εξής:
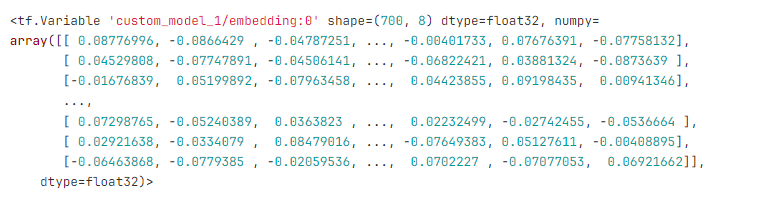
Οι τιμές που εμφανίζονται στον πίνακα των embeddings δημιουργούνται σύμφωνα με έναν συγκεκριμένο μηχανισμό. Για παράδειγμα, για πίνακα διαστάσεων 700x8:

Θα έχουμε έναν πίνακα 700 x 8, όπου οι τιμές θα κυμαίνονται από -0.0920 έως 0.0920, και λαμβάνονται τυχαία από ομοιόμορφη κατανομή. Ο παραπάνω μηχανισμός ονομάζεται Xavier Initialization. Υλοποίηση σε tensorflow:
├── class GlorotNormal().init()
├── class VarianceScaling().call()
- γίνεται αρχικοποίηση των βαρών (layers) του μοντέλου;
├── encoder = SelfAttentionEncoder() module transformer.py
├── self.layer_norm = common.LayerNorm() module self_attention_encoder.py
├── LayerNorm() module common.py
├── SelfAttentionEncoderLayer() module self_attention_encoder.py
├── self.self_attention = MultiHeadAttention() module layers/transformer.py
├── def build() module layers/transformer.py
├── TransformerLayerWrapper(self.self_attention) module layers/transformer.py
├── self.ffn = FeedForwardNetwork() module layers/transformer.py
├── TransformerLayerWrapper(self.ffn) module layers/transformer.py
├── decoder = SelfAttentionDecoder() module transformer.py
├── self.layer_norm = common.LayerNorm() module self_attention_decoder.py
├── LayerNorm() module common.py
├── SelfAttentionDecoderLayer() module self_attention_decoder.py
├── self.self_attention = MultiHeadAttention() module layers/transformer.py
├── def build() module layers/transformer.py
├── TransformerLayerWrapper(self.self_attention) module layers/transformer.py
├── attention = MultiHeadAttention() module layers/transformer.py
├── TransformerLayerWrapper(attention) module layers/transformer.py
├── self.ffn = FeedForwardNetwork() module layers/transformer.py
├── TransformerLayerWrapper(self.ffn) module layers/transformer.py
Πώς φαίνεται αρχικά το μοντέλο, τα βάρη και οι τιμές τους παρουσιάζονται στο παράδειγμα με μικρές διαστάσεις δικτύου:
- vocab: 26
- num_units: 4
- num_layers: 1
- num_heads: 2
- ffn_inner_dim: 1
- maximum_relative_position: 8
Το μοντέλο μπορεί να απεικονιστεί σχηματικά ως εξής. (Εικόνα 2 - μοντέλο)
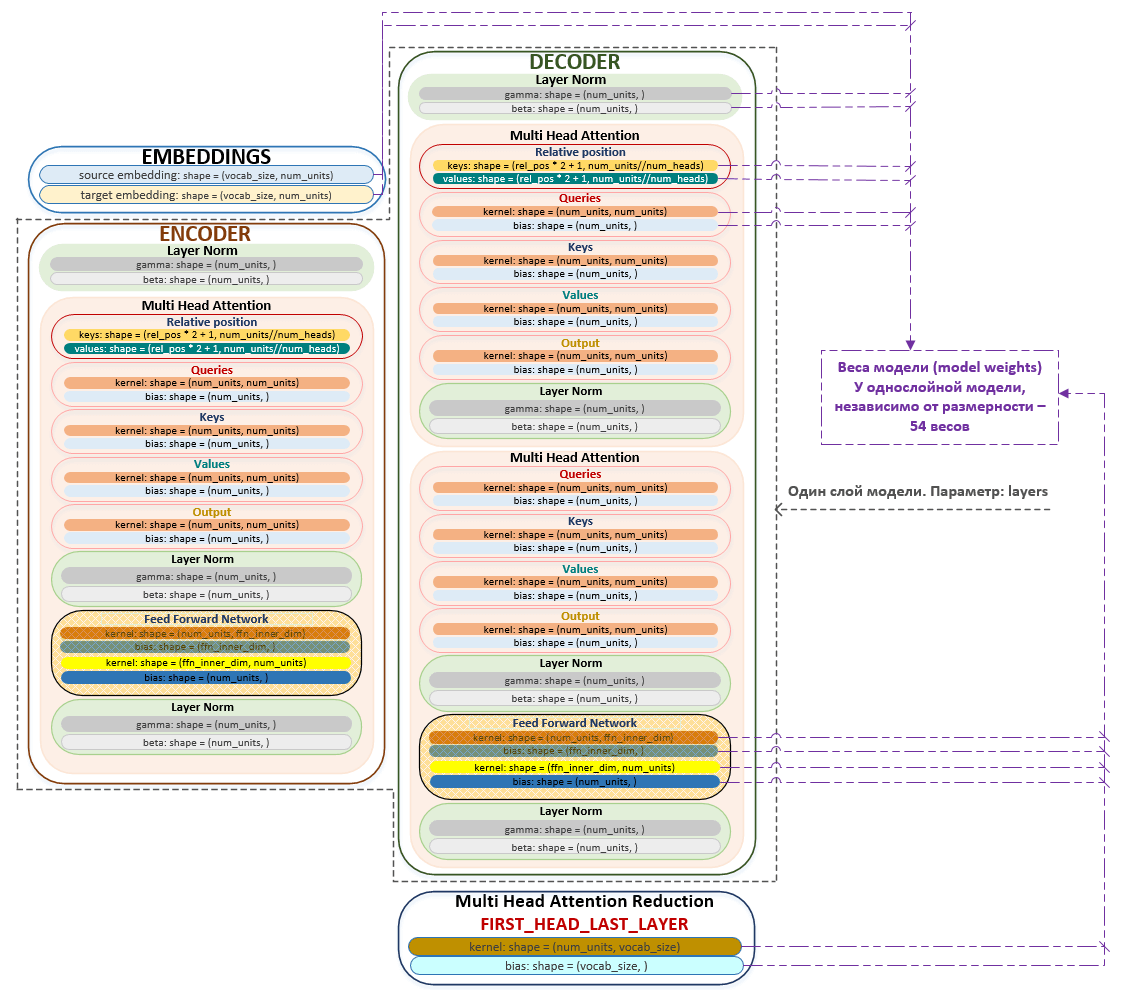
Τα βασικά (πυρηνικά) βάρη του μοντέλου αρχικοποιούνται χρησιμοποιώντας τον μηχανισμό “Xavier Initialization” που περιγράφηκε παραπάνω. Τα queries, keys, values και τα output layers αρχικοποιούνται μέσω του tf.keras.layers.Dense με την προσθήκη του διανύσματος μετατόπισης 'use_bias': True. Τα βάρη του FeedForwardNetwork επίσης αρχικοποιούνται μέσω του tf.keras.layers.Dense με ενεργοποίηση της γραμμικής στρώσης tf.nn.relu. Η στρώση κανονικοποίησης αρχικοποιείται μέσω του tf.keras.layers.LayerNormalization, όπου η διάσταση beta εκπροσωπείται από μηδενικά και η gamma από μονάδες.
Η κανονικοποίηση στρώσεων (Layer normalization, LN) είναι μια τεχνική βαθιάς μάθησης που χρησιμοποιείται για τη σταθεροποίηση της διαδικασίας εκμάθησης και τη βελτίωση της απόδοσης των νευρωνικών δικτύων. Λύνει το πρόβλημα της εσωτερικής μετατόπισης συμφωνίας (ICS), όπου η κατανομή των ενεργοποιήσεων μέσα σε μια στρώση αλλάζει κατά τη διάρκεια της εκμάθησης, καθιστώντας δύσκολη την αποτελεσματική εκπαίδευση του δικτύου. Έγγραφο στο οποίο παρουσιάστηκε η τεχνική Layer Normalization.
Κατά την αρχικοποίηση του μοντέλου πρέπει να πληρείται η εξής συνθήκη: num_units % num_heads, δηλαδή η διαστατικότητα των embeddings (και συνεπώς των queries, keys και values) πρέπει να είναι πολλαπλάσιο του αριθμού των κεφαλών στο MultiHeadAttention.
Στην πράξη, οι πίνακες queries, keys και values διαιρούνται με τον αριθμό που καθορίζεται στην παράμετρο num_heads και σχηματίζονται μικρότεροι πίνακες, των οποίων ο αριθμός είναι ίσος με num_units // num_heads. Ο αλγόριθμος υλοποιείται στη συνάρτηση split_heads του module transformer.py. (Εικόνα 3 - Multi Head Attention)
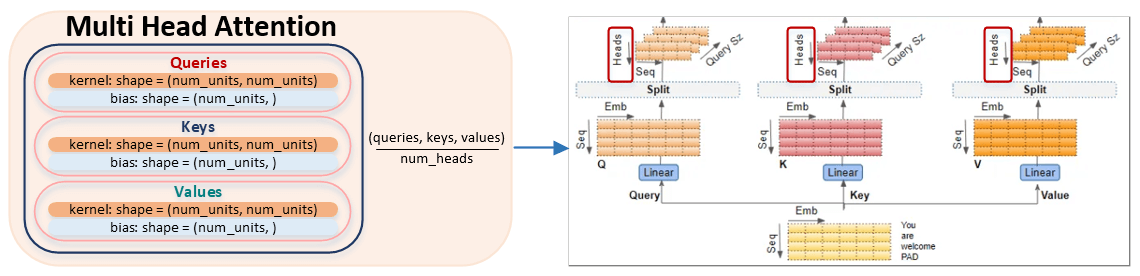
Ας εξετάσουμε τον αλγόριθμο διαχωρισμού των πινάκων queries, keys και values κατά αριθμό κεφαλών. Για ευκολία αντίληψης, θα πάρουμε διαστατικότητα num_units ίση με 4 και αριθμό κεφαλών num_heads ίσο με 2.
Για παράδειγμα, έχουμε ένα batch tokens:

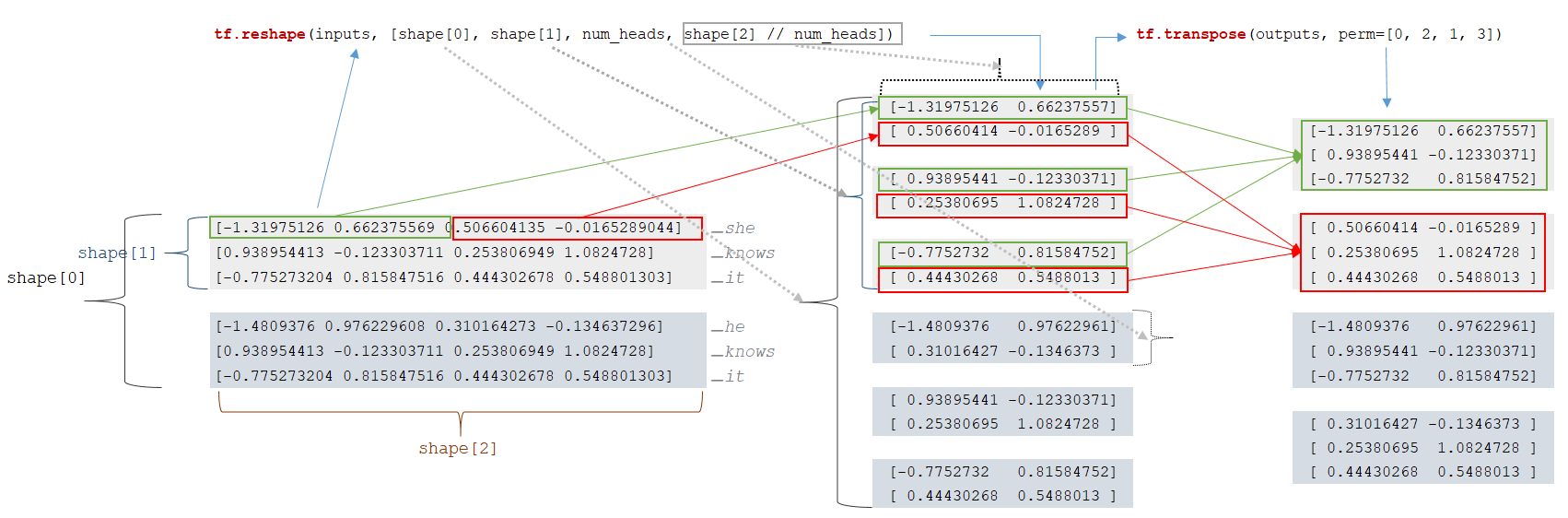
Για κάθε token, εξάγεται μια διανυσματική αναπαράσταση από τον πίνακα embeddings (ο μηχανισμός περιγράφεται παρακάτω) και σχηματίζεται ένας πίνακας διανυσμάτων. Η διαστατικότητα του batch υπολογίζεται ως: input_shapes = [2, 3, 4]. Υπάρχουν 2 ακολουθίες στο batch, κάθε ακολουθία έχει 3 tokens, κάθε token αναπαρίσταται από διάνυσμα διαστάσεων 4. Το επόμενο βήμα είναι να αλλάξει η διαστατικότητα του πίνακα inputs:
- outputs = tf.reshape(inputs, [shape[0], shape[1], num_heads, shape[2] // num_heads]) → tf.reshape(inputs, [2, 3, 2, 4 // 2])
- outputs = tf.transpose(outputs, perm=[0, 2, 1, 3])
Μετά την αλλαγή διαστατικότητας, προκύπτουν πίνακες μικρότερης διαστατικότητας. (Εικόνα 4 - Reshape matrix)
Αυτό είναι το τέλος της διαδικασίας αρχικοποίησης του μοντέλου και ξεκινά η ίδια η διαδικασία εκπαίδευσης.
Συμπέρασμα
Η διαδικασία αρχικοποίησης μοντέλου αποτελεί κρίσιμη προϋπόθεση για αποτελεσματική μάθηση, διασφαλίζοντας ότι όλες οι ρυθμίσεις, οι βελτιστοποιητές και τα embeddings έχουν διαμορφωθεί σωστά. Ορίζοντας συστηματικά τον τύπο υπολογισμού, προετοιμάζοντας το dataset και αρχικοποιώντας τα βάρη του μοντέλου με τεχνικές όπως η Xavier initialization και η layer normalization, το πλαίσιο μπορεί να βελτιστοποιηθεί. Αυτή η λεπτομερής προσέγγιση όχι μόνο βελτιώνει την υπολογιστική αποδοτικότητα, αλλά σταθεροποιεί και τη διαδικασία μάθησης, ανοίγοντας τον δρόμο για επιτυχημένη εκπαίδευση μοντέλου και ακριβείς προβλέψεις. Η κατανόηση αυτών των θεμελιωδών βημάτων είναι απαραίτητη για όποιον θέλει να αξιοποιήσει αποτελεσματικά μοντέλα βαθιάς μάθησης.


