
Αυτό το άρθρο είναι μια συνέχεια του πρώτου μέρους "Μηχανισμός παραγωγής συμπερασμάτων σε μια εκπαιδευμένη ακολουθία μοντέλο παραγωγής", το οποίο αφιερώνεται στη διαδικασία παραγωγής συμπερασμάτων σε ένα εκπαιδευμένο μοντέλο παραγωγής ακολουθίας, που απεικονίζει την αρχιτεκτονική και τη λειτουργικότητα του στο παράδειγμα της φράσης "το γνωρίζει". Σε αυτό το μέρος, εξετάζουμε τα υπόλοιπα τρία βήματα του μηχανισμού παραγωγής συμπερασμάτων.
Με τη διάσπαση των εργασιών βήμα προς βήμα που εμπλέκονται στην παραγωγή αλληλουχίας, στοχεύουμε να παρέχουμε μια ολοκληρωμένη κατανόηση του τρόπου με τον οποίο τα μοντέλα αυτά παράγουν συνεκτικές και συμφραζόμενες κατάλληλες εξόδους. Αυτή η μελέτη όχι μόνο θα βοηθήσει στην κατανόηση των υποκείμενων μηχανισμών της παραγωγής αλληλουχίας, αλλά και της θεμελίωσης για μελλοντικές βελτιώσεις στην ανάπτυξη και την εφαρμογή του μοντέλου.

Βήμα1
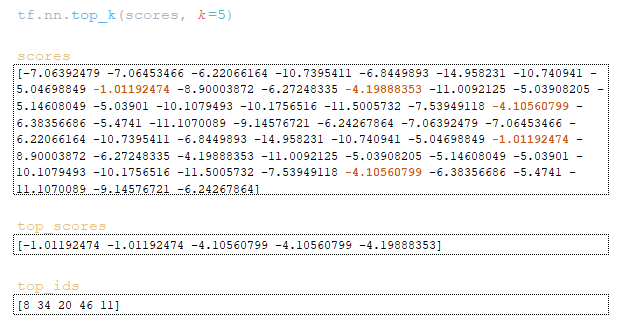
Με word_ids matrix που λαμβάνεται στο βήμα step = 0 Εξαγωγή διανυσματικών αναπαραστάσεων των μαρκών από το target ενσωματώνει το matrix του εκπαιδευμένου μοντέλου και μαζί με το encoder_outputs Διπλασιασμένο από τον αριθμό των beam_s που τροφοδοτείται για να εισαγάγει το decoder. Από τον αποκωδικοποιητή παίρνουμε το Matrix logits και Προσοχή . (Εικόνα 1 - logits και μήτρες προσοχής) 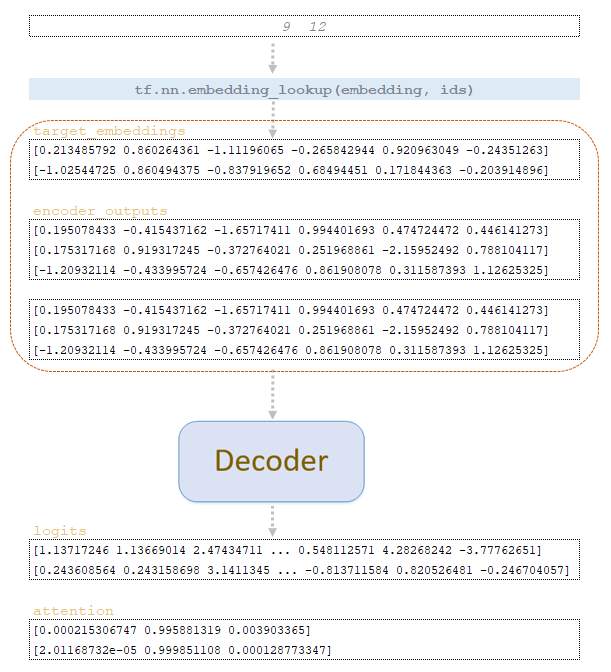
Αφού περάσουμε τις παραπάνω λειτουργίες, παίρνουμε μετά το βήμα 1 οι μήτρες word_ids , cum_log_probs , τελείωσε και το λεξικό extra_vars /.
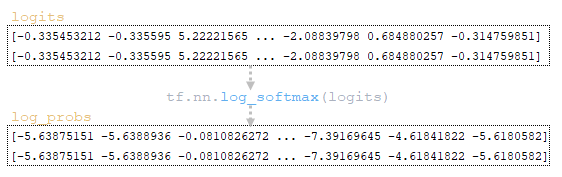
(Εικόνα 2A - Logits και Log_probs) (Εικόνα 2b - Total_Probs) (Εικόνα 2C - Top_scores και Top_ids) (Εικόνα 2D - Matrices Word_ids, Cum_log_probs, Finish και Λεξικό extra_vars)
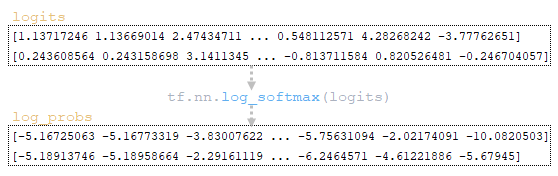

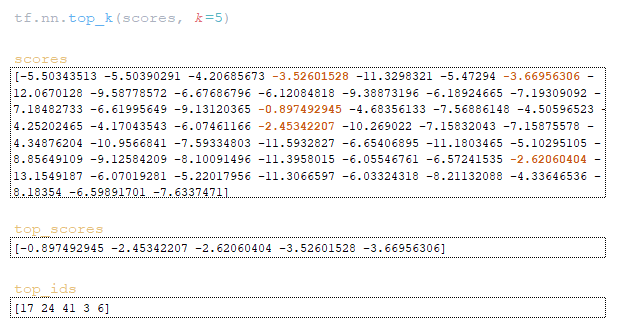

Βήμα2
Σύμφωνα με τη μήτρα word_ids που λαμβάνεται στο βήμα step = 1 , οι παραστάσεις διανυσμάτων των μαρκών εκχυλίζονται από το target ενσωματώσεις matrix του εκπαιδευμένου μοντέλου και μαζί με το encoder_outputs matrix που αντιγράφονται από τον αριθμό του beam_size intrix matrix του εκπαιδευμένου μοντέλου και, μαζί με το encoder_outputs matrix που είναι διπλό με τον αριθμό του by αποκωδικοποιητής. Από τον αποκωδικοποιητή παίρνουμε το Matrix logits και Προσοχή . (Εικόνα 3 - Logits και Matrices Προσοχής, Βήμα 2) 
Εκτελέστε όλες τις παραπάνω λειτουργίες και λάβετε τα matrices word_ids , cum_log_probs , και το λεξικό extra_vars μετά το βήμα 2.
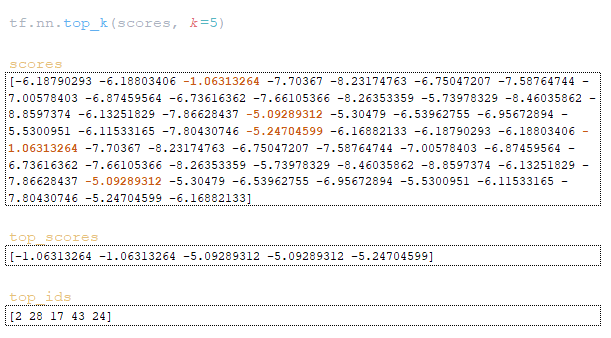
(Εικόνα 4Α - logits και log_probs) (Εικόνα 4b - Total_Probs) (Εικόνα 4c - top_scores και top_ids) (εικόνα 4D - matrices word_ids, cum_log_probs, τελειωμένο και λεξικό extra_vars)
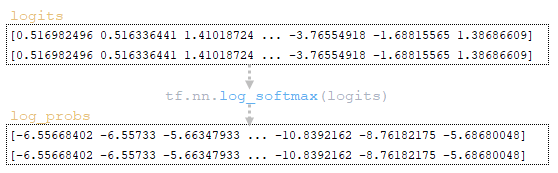


Βήμα3
Χρησιμοποιώντας τη μήτρα που λαμβάνονται στο βήμα βήμα = 2 , εξάγουμε παραστάσεις διανυσμάτων των μαρκών από το target ενσωματώνει το matrix του εκπαιδευμένου μοντέλου και, μαζί με το encoder_outputs matrix που είναι διπλό με τον αριθμό των beam_size ΑποκοιοκλικόL Είσοδος. Από τον αποκωδικοποιητή παίρνουμε το Matrix logits και Προσοχή . (Εικόνα 5 - Logits και Matrices Προσοχής, Βήμα 3) 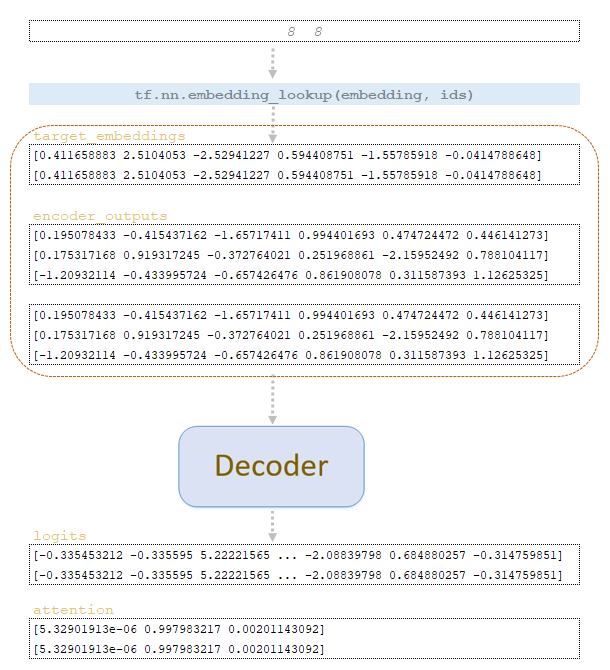
Εκτελέστε τις παραπάνω λειτουργίες και λάβετε τις μήτρες word_ids , cum_log_probs , και το λεξικό extra_vars μετά το βήμα 3.
(Εικόνα 6A - Logits και Log_probs) (Εικόνα 6B - Total_Probs) (Εικόνα 6C - Top_scores και Top_ids) (Εικόνα 6D - Matrices Word_ids, Cum_log_probs, Finish και Λεξικό extra_vars)


Σε αυτό το βήμα, ο βρόχος διακόπτεται επειδή ο αποκωδικοποιητής έχει δημιουργήσει μάρκες τελικής ακολουθίας & lt;/ S & gt; με id = 2.
Οι ληφθείσες αλληλουχίες των μαρκών ταυτότητας αποκωδικοποιούνται και λαμβάνονται υποθέσεις μετάφρασης προτάσεων προέλευσης. Ο αριθμός των υποθέσεων δεν μπορεί να είναι μεγαλύτερος από το Beam_size, δηλαδή αν θέλουμε να λάβουμε 3 εναλλακτικές μεταφράσεις, πρέπει να ορίσουμε το Beam_size = 3.
Στην πραγματικότητα, ως εκ τούτου έχουμε 2 υποθέσεις, η 1η υπόθεση θα περιέχει αλληλουχίες των πιο πιθανών μαρκών που λαμβάνονται και αρκετές κατανομές. (Εικόνα 7 - Target_tokens)

Σύναψη
Σε αυτή την ανάλυση, μελετήσαμε τον μηχανισμό συμπερασμάτων σε ένα εκπαιδευμένο μοντέλο παραγωγής ακολουθίας χρησιμοποιώντας τη φράση "το ξέρει αυτό" ως παράδειγμα. Περιγράψαμε την αρχιτεκτονική του μοντέλου, περιγράφοντας λεπτομερώς τον τρόπο με τον οποίο τα μάρκες εκπροσωπούνται και επεξεργάζονται μέσω του κωδικοποιητή και του αποκωδικοποιητή. Τα βασικά στοιχεία της διαδικασίας συμπερασμάτων, όπως η αρχικοποίηση των παραμέτρων, η εφαρμογή της αναζήτησης ακτίνων, ο υπολογισμός των λογαριθμικών πιθανοτήτων και των βαθμολογιών συζητήθηκαν λεπτομερώς. Υπογραμμίσαμε τις λειτουργίες βήμα προς βήμα που εμπλέκονται σε παραγωγή αλληλουχίας, συμπεριλαμβανομένου του τρόπου μετασχηματισμού και της ενημερωμένης μήτρας σε κάθε επανάληψη.
Τελικά, αυτός ο μηχανισμός επιτρέπει στο μοντέλο να παράγει αλληλουχίες που σχετίζονται με το πλαίσιο, οδηγώντας τελικά στη δημιουργία υποθέσεων για μετάφραση. Η μελέτη αυτής της διαδικασίας όχι μόνο εμβαθύνει την κατανόηση της παραγωγής ακολουθιών, αλλά και μας βοηθά να βελτιώσουμε τη μελλοντική αρχιτεκτονική και τις επιδόσεις του μοντέλου.


