
Σε αυτό το άρθρο εξετάζουμε τον μηχανισμό συμπερασμού σε ένα εκπαιδευμένο μοντέλο χρησιμοποιώντας ως παράδειγμα τη συμβολοσειρά “he knows this”. Θα περιγράψουμε την αρχιτεκτονική του μοντέλου, η οποία αναπαράγει με ακρίβεια τη διαδικασία μάθησης, και θα αναλύσουμε τα διάφορα συστατικά που εμπλέκονται στη μετατροπή των εισερχόμενων tokens σε χρήσιμες προβλέψεις. Θα εξεταστούν βασικές παράμετροι όπως το μέγεθος λεξιλογίου, ο αριθμός μονάδων, τα επίπεδα και οι κεφαλές προσοχής για να δώσουμε πλήρες πλαίσιο λειτουργίας.

Επισκόπηση Αρχιτεκτονικής Μοντέλου
Ας εξετάσουμε τον μηχανισμό συμπερασμού του εκπαιδευμένου μοντέλου με παράδειγμα τη συμβολοσειρά ▁he ▁knows ▁it. Η αρχιτεκτονική του μοντέλου, για λόγους κατανόησης, θα είναι περίπου ίδια με εκείνη που χρησιμοποιήθηκε κατά τη φάση εκπαίδευσης:
- λεξιλόγιο: 26
- μονάδες: 6
- επίπεδα: 1
- κεφαλές προσοχής: 2
- εσωτερική διάσταση FFN: 12
- μέγιστη σχετική θέση: 8
Αναπαράσταση Tokens και Επεξεργασία στον Encoder
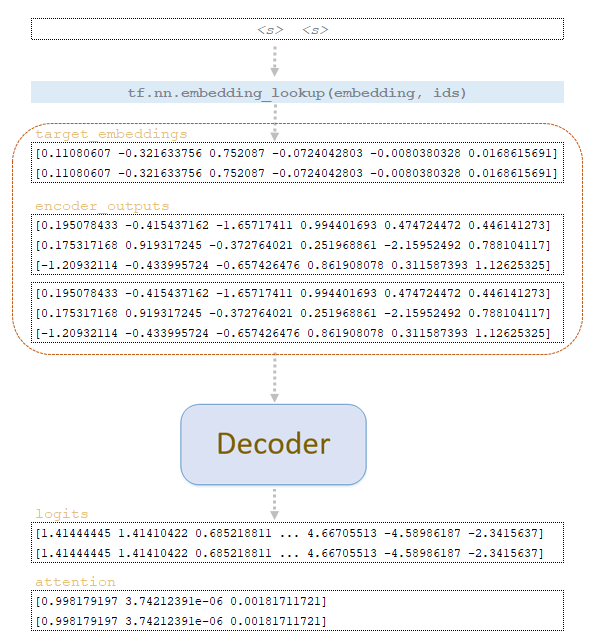
Για κάθε token, η διανυσματική αναπαράσταση εξάγεται από τον πίνακα ενσωμάτωσης (embedding) της εκπαιδευμένης πηγής και παρέχεται ως είσοδος στον encoder. Στον encoder εφαρμόζονται ακριβώς οι ίδιες μετασχηματίσεις όπως και κατά την εκπαίδευση του μοντέλου, με μόνη διαφορά ότι δεν εφαρμόζεται dropout. Μετά τη μετατροπή λαμβάνεται ο πίνακας encoder_outputs. (Εικόνα 1 – ο πίνακας encoder_outputs)

Παράμετροι και Αρχικοποίηση Συμπερασμού
Στη συνέχεια, εξετάζουμε το παράδειγμα συμπερασμού με τις ακόλουθες παραμέτρους. Στην περίπτωσή μας χρησιμοποιήθηκαν:
- beam_size = 2
- length_penalty = 0.2
- coverage_penalty = 0.2
- sampling_topk = 5
- sampling_temperature = 0.5
Η εφαρμογή της συνάρτησης tfa.seq2seq.tile_batch (encoder_outputs, beam_size) επιτρέπει τον πολλαπλασιασμό του πίνακα encoder εξόδου με βάση το beam_size. Η έξοδος είναι πίνακας τιμών επί beam_size, στη δική μας περίπτωση δύο. (Εικόνα 2 – Encoder outputs * beam size)

Το επόμενο βήμα είναι η αρχικοποίηση των μεταβλητών:
1) μέγεθος παρτίδας για μετάφραση, στο παράδειγμά μας batch_size = 1;
2) πίνακας start_ids, που περιέχει δείκτες tokens για την έναρξη ακολουθίας <s>, προσαρμοσμένος στο beam_size → start_ids = tfa.seq2seq.tile_batch(start_ids, beam_size) = [1 1];
3) πίνακας finished, γεμάτος με μηδενικά, τύπου boolean και διαστάσεων batch_size * beam_size → tf.zeros([batch_size * beam_size], dtype=tf.bool) = [0 0];
4) πίνακας initial_log_probs → tf.tile([0.0] + [-float("inf")] * (beam_size - 1), [batch_size]) = [0 -inf];
5) λεξικό με επιπλέον μεταβλητές extra_vars, που περιλαμβάνει τις εξής μεταβλητές:
- parent_ids: tf.TensorArray(tf.int32, size=0, dynamic_size=True) → []
- sequence_lengths: tf.zeros([batch_size * beam_size], dtype=tf.int32) → [0 0]
- accumulated_attention: tf.zeros([batch_size * beam_size, attention_size]), όπου το attention_size είναι η διάσταση του πίνακα encoder_outputs (tf.shape(encoder_outputs)[1] = 3) → [[0 0 0], [0 0 0]]
Κατόπιν εκτελείται βρόχος επανάληψης μέχρι να φτάσουμε το μέγιστο μήκος αποκωδικοποίησης (maximum_decoding_length = 250) ή να παραχθεί το τελικό token τέλους ακολουθίας.
Βήμα 0 (Step 0)
Χρησιμοποιώντας τον πίνακα start_ids, εξάγονται οι διανυσματικές αναπαραστάσεις των tokens από τον πίνακα target embeddings και, μαζί με τον πίνακα encoder_outputs (πολλαπλασιασμένο επί beam_size), εισάγονται στον αποκωδικοποιητή (decoder). Στον αποκωδικοποιητή εφαρμόζονται οι ίδιες μετασχηματίσεις όπως και κατά την εκπαίδευση, εκτός από το γεγονός ότι δεν δημιουργείται το future_mask και δεν εφαρμόζεται dropout. (Εικόνα 3 – διαδικασία αποκωδικοποιητή)
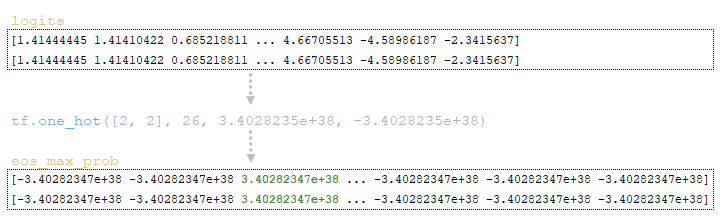
Οι μεταβλητές batch_size = 1 και vocab_size = 26 καθορίζονται από τη διάσταση του πίνακα logits που επιστρέφεται από τον αποκωδικοποιητή. Στη συνέχεια, με χρήση της συνάρτησης tf.one_hot(tf.fill([batch_size], end_id), vocab_size, on_value=logits.dtype.max, off_value=logits.dtype.min) δημιουργείται ο πίνακας eos_max_prob, όπου:
- tf.fill([batch_size], end_id); end_id είναι ο δείκτης του token τέλους ακολουθίας </s> → [2 2];
- logits.dtype.max: μέγιστη τιμή για tf.float32 = 3.4028235e+38
- logits.dtype.min: ελάχιστη τιμή για tf.float32 = -3.4028235e+38
Άρα η έξοδος είναι πίνακας eos_max_prob διαστάσεων 2 x 26, όπου το index 2 περιέχει τη μέγιστη τιμή και όλα τα υπόλοιπα την ελάχιστη. (Εικόνα 4 – eos_max_prob matrix)
Χρησιμοποιώντας τη συνάρτηση tf.where (tf.broadcast_to (tf.expand_dims (finished, -1), tf.shape(logits)), x=eos_max_prob, y=logits), όπου ο πίνακας finished μετατρέπεται σε μορφή: tf.expand_dims([0, 0], -1) → [[0], [0]], παίρνουμε έναν πίνακα τιμών με διαστάσεις [2, 26]. Η διεύρυνση διαστάσεων δίνει: tf.broadcast_to([[0], [0]], [2, 26]) → [[0, 0, ..., 0], [0, 0, ..., 0]].
Εφόσον ο πίνακας finished περιέχει μόνο μηδενικά, ο τελικός πίνακας γεμίζει με τιμές από τον logits πίνακα.
Ο πίνακας log_probs υπολογίζεται από τον logits χρησιμοποιώντας τη συνάρτηση tf.nn.log_softmax(logits). (Εικόνα 5 – Πίνακας log_probs)

Εάν ισχύει ότι coverage_penalty != 0, τότε εκτελούνται επιπλέον τα εξής βήματα:
- Ο πίνακας finished αναστρέφεται με χρήση tf.math.logical_not([0, 0]) ώστε να προκύψει ο πίνακας not_finished → [1, 1]
- Το αποτέλεσμα μετατρέπεται σε float32 και επεκτείνεται: tf.expand_dims(tf.cast(not_finished, attention.dtype), 1) → [[1], [1]]
- Ο παραπάνω πίνακας πολλαπλασιάζεται με τον πίνακα attention (Εικόνα 6 – πίνακας attention)
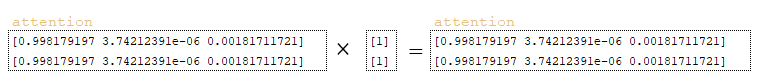
- Παράγεται η μεταβλητή accumulated_attention. (Εικόνα 7 – accumulated_attention)
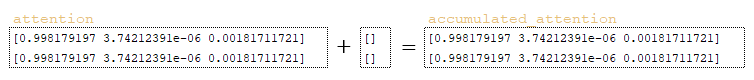
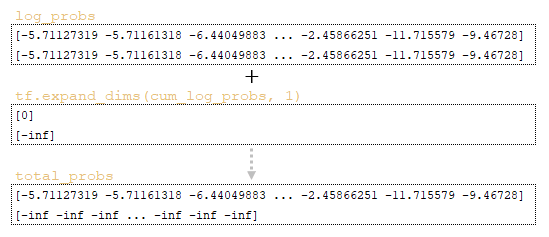
Έπειτα, υπολογίζεται ο πίνακας total_probs με άθροιση των log_probs και του cum_log_probs: log_probs + tf.expand_dims(cum_log_probs, 1). (Εικόνα 8 – πίνακας total_probs)
Με βάση τους πίνακες total_probs, sequence_lengths, finished και accumulated_attention υπολογίζονται οι scores. Τα βήματα είναι:
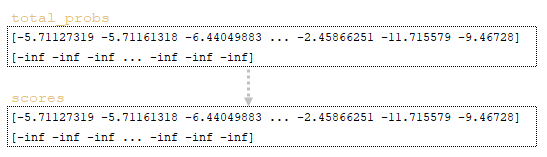
1) Ο αρχικός πίνακας scores = total_probs αντιγράφεται από τον total_probs (Εικόνα 9 – total_probs και scores)
2) Αν length_penalty != 0, εφαρμόζονται τα εξής:
- Δημιουργείται ο πίνακας expand_sequence_lengths μέσω tf.expand_dims(sequence_lengths, 1) → [[0], [0]]
- Προστίθεται 1 και μετατρέπεται στον τύπο του log_probs: tf.cast(expand_sequence_lengths + 1, log_probs.dtype) → [[1], [1]]
- Υπολογίζεται ο πίνακας sized_expand_sequence_lengths: (5.0 + expand_sequence_lengths) / 6.0 → [[1], [1]]
- Ο πίνακας sized_expand_sequence_lengths υψώνεται στη δύναμη length_penalty: tf.pow([[1], [1]], 0.2) → [[1], [1]]
- Το scores προσαρμόζεται διαιρώντας διαδοχικά με το αποτέλεσμα: scores /= penalized_sequence_lengths (Εικόνα 10 – scores)

3) Αν coverage_penalty != 0, τότε εφαρμόζονται τα παρακάτω:
- Ο πίνακας equal δημιουργείται από τον accumulated_attention μέσω tf.equal(accumulated_attention, 0.0), σε συνδυασμό με tf.expand_dims(sequence_lengths, 1) – ελέγχεται αν τα στοιχεία είναι μηδέν. (Εικόνα 11 – equal matrix)

- Ο πίνακας ones_like δημιουργείται μέσω της συνάρτησης tf.ones_like(accumulated_attention). (Εικόνα 12 – ones_like)

- Με τη χρήση tf.where(equal, x=ones_like, y=accumulated_attention), ο πίνακας accumulated_attention επανυπολογίζεται. Αφού όλα τα στοιχεία του equal είναι 0, οι τιμές λαμβάνονται από y. (Εικόνα 13 – accumulated_attention)

- Ο πίνακας coverage_penalty δημιουργείται: tf.reduce_sum(tf.math.log(tf.minimum(accumulated_attention, 1.0)), axis=1). (Εικόνα 14 – coverage_penalty)

- Ο πίνακας coverage_penalty προσαρμόζεται: πολλαπλασιάζεται με τον finished → coverage_penalty *= finished. (Εικόνα 15 – coverage_penalty)

- Ο τελικός πίνακας scores ενημερώνεται: scores += self.coverage_penalty * tf.expand_dims(coverage_penalty, 1). (Εικόνα 16 – scores)
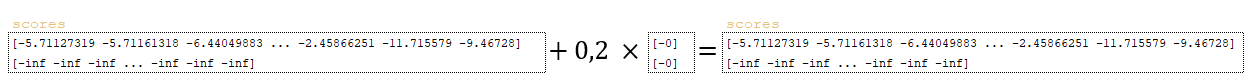
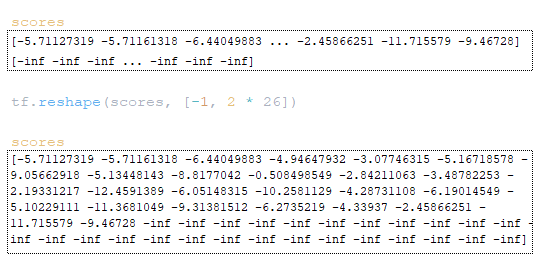
Στη συνέχεια γίνεται αναδιάταξη των πινάκων scores και total_probs: scores = tf.reshape(scores, [-1, beam_size * vocab_size]) (Εικόνα 17)
Ο πίνακας total_probs μετασχηματίζεται με τον ίδιο τρόπο: tf.reshape(scores, [-1, beam_size * vocab_size]) (Εικόνα 18)
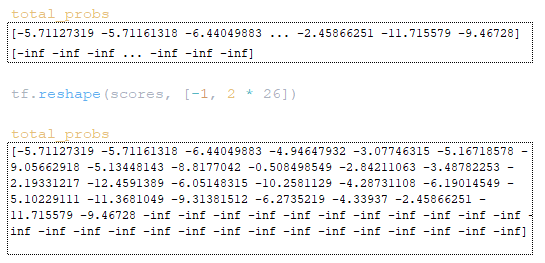
Το επόμενο βήμα είναι ο υπολογισμός των στοχευμένων tokens sample_ids και των βαθμολογιών τους sample_scores:
- Με τη χρήση της tf.nn.top_k επιλέγονται τα μεγαλύτερα στοιχεία και οι δείκτες τους: top_scores, top_ids = tf.nn.top_k(scores, k=sampling_topk). (Εικόνα 19 – top_scores και top_ids)
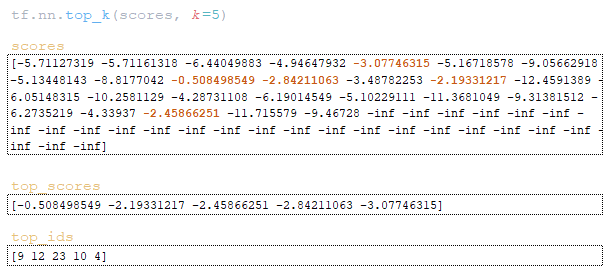
- Ο πίνακας top_scores διαιρείται με την τιμή sampling_temperature. (Εικόνα 20 – sampling_temperature)
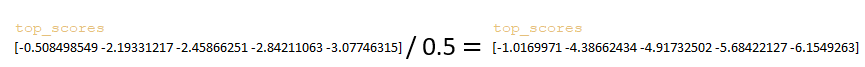
- Από τον πίνακα top_scores εφαρμόζεται tf.random.categorical για δειγματοληψία κατά beam_size. (Εικόνα 21 – sample_ids)
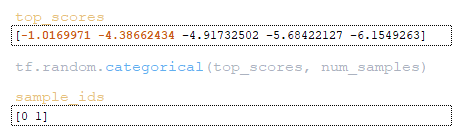
- Με χρήση tf.gather εξάγονται τα token indices από τον πίνακα top_ids. (Εικόνα 22 – token indices)
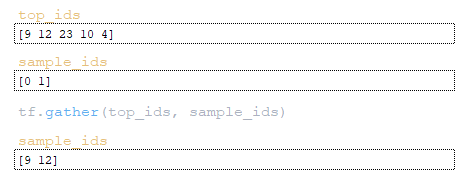
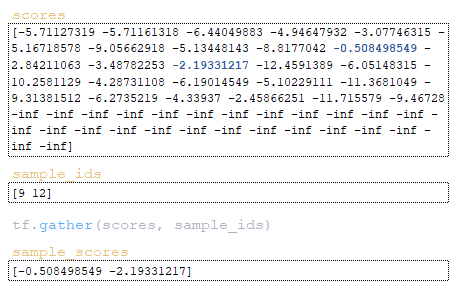
- Με τον ίδιο τρόπο, εξάγονται οι sample_scores από τον πίνακα scores. (Εικόνα 23 – sample_scores)
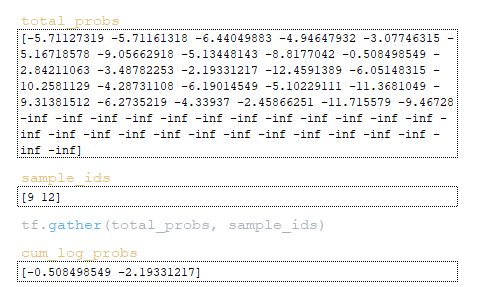
Έπειτα παράγεται ο πίνακας cum_log_probs από τις τιμές sample_ids που λαμβάνονται από το total_probs. (Εικόνα 24 – cum_log_probs). Ο πίνακας word_ids προκύπτει από το υπόλοιπο διαίρεσης sample_ids % vocab_size = [9 12] % 26 → [9 12]
Ο πίνακας beam_ids προκύπτει με ακέραια διαίρεση sample_ids // vocab_size = [9 12] // 26 → [0 0].
Με χρήση των word_ids, beam_ids και beam_size, υπολογίζεται ο πίνακας beam_indices: (tf.range(tf.shape(word_ids)[0]) // beam_size) * beam_size + beam_ids = ([0 1] // 2) * 2 + [0 0] = [0 0]
Έπειτα, γίνεται αναπροσαρμογή των πινάκων sequence_lengths, finished και αποθήκευση στο λεξικό extra_vars:
- sequence_lengths αναπροσαρμόζεται: tf.where(finished, x=sequence_lengths, y=sequence_lengths + 1) (Εικόνα 25 – sequence_lengths)

- finished επαναπροσδιορίζεται: tf.gather(finished, beam_indices) → [0 0]
- sequence_lengths επαναπροσδιορίζεται: tf.gather(sequence_lengths, beam_indices) → [1 1]
Ενημέρωση του λεξικού extra_vars:
- Αποθήκευση sequence_lengths με κλειδί "sequence_lengths"
- Εγγραφή beam_ids στην μεταβλητή parent_ids: parent_ids.write(step, beam_ids)
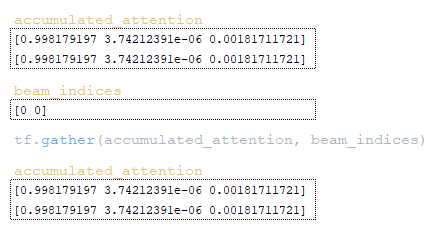
- Αποθήκευση accumulated_attention: tf.gather(accumulated_attention, beam_indices) (Εικόνα 26 – accumulated_attention)
- Τα παραγόμενα word_ids συγκρίνονται με το token τέλους </s> και ο πίνακας finished ανανεώνεται: finished = tf.logical_or(finished, tf.equal(word_ids, end_id))
Με αυτό ολοκληρώνεται το Βήμα 0. Οι πίνακες word_ids, cum_log_probs, finished και το λεξικό extra_vars περνούν στην αρχή του επόμενου κύκλου βρόχου, επαναλαμβάνοντας τη διαδικασία. (Εικόνα 27 – word_ids, cum_log_probs, finished και extra_vars)

Συμπεράσματα
Σε αυτό το άρθρο εξετάσαμε σε βάθος τον μηχανισμό συμπερασμού ενός εκπαιδευμένου μοντέλου με χρήση της συμβολοσειράς "he knows it" ως παράδειγμα. Ξεκινήσαμε περιγράφοντας την αρχιτεκτονική του μοντέλου και τις βασικές παραμέτρους που την καθορίζουν, όπως μέγεθος λεξιλογίου, αριθμό μονάδων και επιπέδων.
Αναλύσαμε τη διαδικασία αναπαράστασης των tokens και τη λειτουργία του encoder, τονίζοντας ότι δεν εφαρμόζεται dropout κατά τη φάση συμπερασμού, διατηρώντας έτσι πλήρη συμφωνία με την εκπαίδευση. Συζητήσαμε την αρχικοποίηση των παραμέτρων και τη δομή επανάληψης που διέπει την αποκωδικοποίηση, δίνοντας έμφαση στους πίνακες log_probs, total_probs και την εφαρμογή ποινών (penalties).
Στο δεύτερο μέρος του άρθρου θα καλύψουμε τα βήματα 1, 2 και 3, όπου θα αποκαλυφθούν περαιτέρω λεπτομέρειες του μηχανισμού συμπερασμού.


