
Σε αυτή την εργασία, παρουσιάζουμε τις προκλήσεις που εμπλέκονται στην ανάπτυξη μιας κινητής έκδοσης ενός συστήματος μεταφράσεων νευρικής μηχανής. Ο στόχος είναι να μεγιστοποιηθεί η ποιότητα της μετάφρασης, ενώ ελαχιστοποιείται το μέγεθος του μοντέλου. Εξηγούμε ολόκληρη τη διαδικασία εφαρμογής της μεταφραστικής μηχανής χρησιμοποιώντας το αγγλικό ζευγάρι γλωσσών ως παράδειγμα. Περιγράφουμε τις προκλήσεις που αντιμετωπίστηκαν και τις λύσεις που εφαρμόζονται.
Οι κύριες μέθοδοι που χρησιμοποιούνται σε αυτό το έργο περιλαμβάνουν:
- Επιλογή δεδομένων χρησιμοποιώντας σπάνια ανάκτηση N-gram.
- Προσθέτοντας μια ειδική λέξη στο τέλος κάθε πρότασης.
- Δημιουργώντας πρόσθετα δείγματα χωρίς τελική στίξη.

Οι δύο τελευταίες μέθοδοι αναπτύχθηκαν για να δημιουργήσουν ένα μοντέλο μετάφρασης που δημιουργεί προτάσεις χωρίς τελική περίοδο ή άλλα σημάδια στίξης. Η σπάνια ανάκτηση N-Gram χρησιμοποιήθηκε επίσης για πρώτη φορά για να δημιουργηθεί ένα νέο σώμα, και όχι μόνο για να αυξήσει ένα σύνολο δεδομένων σε έναν τομέα.
Τέλος, φτάνουμε σε ένα μοντέλο μικρού μεγέθους που παρέχει αρκετά καλή ποιότητα για καθημερινή χρήση.
Η προσέγγιση Lingvanex
Το Lingvanex είναι ένα εμπορικό σήμα γλωσσικών προϊόντων από την Nordicwise LLC, η οποία ειδικεύεται σε εφαρμογές μετάφρασης και λεξικών για κινητά και επιτραπέζιες πλατφόρμες. Σε συνεργασία με το Sciling, μια εταιρεία που ειδικεύεται σε λύσεις μηχανικής μάθησης από άκρο σε άκρο, αναπτύχθηκε ένα μικρό μοντέλο μετάφρασης αγγλόφωνων για κινητά. Ο κύριος στόχος ήταν να παρέχονται ακριβείς μεταφράσεις σε καθημερινά σενάρια, ειδικά για ταξιδιώτες που ενδέχεται να μην έχουν πρόσβαση στο Διαδίκτυο λόγω του κόστους περιαγωγής, της έλλειψης τοπικών καρτών SIM ή της κακής συνδεσιμότητας σε ορισμένες περιοχές. Για να επιτευχθεί αυτό, το έργο επικεντρώθηκε στην ελαχιστοποίηση του μεγέθους του μοντέλου χρησιμοποιώντας τεχνικές επιλογής δεδομένων, στοχεύοντας σε τελικό μέγεθος 150 MB ή λιγότερο.
Διεξήχθησαν πειράματα για τον εντοπισμό βασικών παραγόντων που επηρεάζουν το μέγεθος του μοντέλου, συμπεριλαμβανομένου του μεγέθους του λεξιλογίου, της ενσωμάτωσης των λέξεων και της αρχιτεκτονικής του νευρικού δικτύου. Αρκετά θέματα μετάφρασης προέκυψαν κατά τη διάρκεια της διαδικασίας εφαρμογής, προκαλώντας την ανάπτυξη κατάλληλων λύσεων. Η ποιότητα του τελικού μοντέλου αξιολογήθηκε έναντι των κορυφαίων μεταφραστών κινητής τηλεφωνίας από την Google και τη Microsoft, αποδεικνύοντας την αποτελεσματικότητά της για πρακτική χρήση σε ταξιδιωτικές καταστάσεις.
Περιγραφή δεδομένων
Τα δεδομένα που χρησιμοποιήθηκαν για την εκπαίδευση του μοντέλου μετάφρασης ελήφθησαν από το corpus opus corpus. Υπήρχαν συνολικά 76 μ. Παράλληλες προτάσεις. Χρησιμοποιήσαμε επίσης το Corpus Tatoeba για DS που περιγράφεται στην ενότητα Φιλτράρισμα δεδομένων. Το Tatoeba είναι μια δωρεάν ηλεκτρονική συνεργατική βάση δεδομένων παραδείγματος προτάσεων που απευθύνονται σε μαθητές γλώσσας. Το σύνολο ανάπτυξης δημιουργήθηκε επίσης από το Tatoeba Corpus επιλέγοντας 2K τυχαία ζεύγη προτάσεων. Οι κύριες μετρήσεις του Tatoeba Corpus παρουσιάζονται στον Πίνακα 1. Ως δοκιμαστικό σετ, δημιουργούμε ένα μικρό σώμα πιο χρήσιμων αγγλικών προτάσεων που βρίσκονται σε διαφορετικούς ιστότοπους. Προσθέτουμε επίσης κάποιες προτάσεις Unigram και Bigram. Συνολικά, επιλέξαμε 86 προτάσεις.
Εξάρτηση μεγέθους μοντέλου
Κατά την επίλυση του προβλήματος της μείωσης του μεγέθους του μοντέλου, η κύρια πρόκληση είναι να προσδιοριστεί ποια υπερπαραμετρία έχουν το μεγαλύτερο αντίκτυπο στο μέγεθος. Πριν από την εφαρμογή του συστήματος μεταφράσεων νευρωνικών μηχανών (NMT), διεξήχθησαν πειράματα συγκρίνοντας το μέγεθος του μοντέλου με το συνολικό μέγεθος λεξιλογίου και το μέγεθος της ενσωμάτωσης λέξεων (Εικόνα 1). Διαφορετικά μοντέλα εκπαιδεύτηκαν μεταβάλλοντας αυτά τα υπερπαράμετρα.
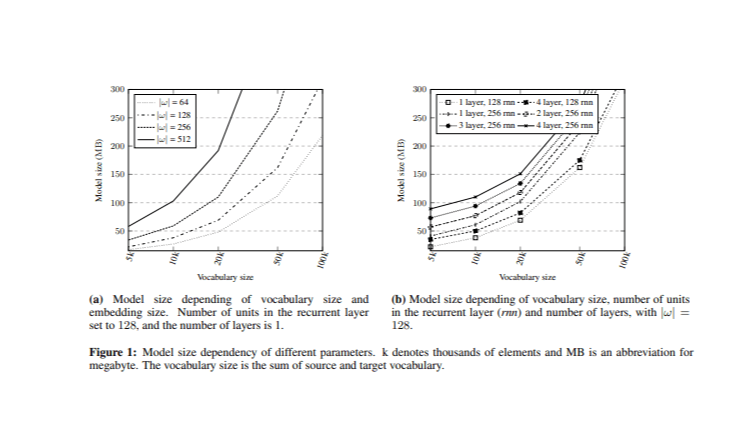
Στο αρχικό πείραμα, το επαναλαμβανόμενο στρώμα είχε 128 μονάδες με ένα στρώμα τόσο στις πλευρές του κωδικοποιητή όσο και του αποκωδικοποιητή. Τα συνδυασμένα μεγέθη λεξιλογίου (V) (πηγή και στόχος) μειώθηκαν σε διαφορετικά επίπεδα | V | = {5k, 10k, 20k, 50k και 100k} με βάση τις συχνότερες λέξεις στο corpus opus με ίση κατανομή μεταξύ της πηγής και των λεξιλογίων στόχου, με μέγεθος λεξιλογίου προέλευσης και στόχου σε | v |/2. Επιπλέον, διαφορετικά μεγέθη ενσωμάτωσης | ω | = {64, 128, 256, 512} αναλύθηκαν.
Στη συνέχεια εξετάστηκε η επίδραση διαφορετικών κρυφών μονάδων και ο αριθμός των στρωμάτων ενώ το μέγεθος της ενσωμάτωσης σταθεροποιήθηκε στο | Ω | = 128. Τα αποτελέσματα έδειξαν ότι ο αριθμός των στρωμάτων είχε ελάχιστη επίδραση στο μέγεθος του μοντέλου, ειδικά σε σύγκριση με τον αριθμό των κρυφών μονάδων και το μέγεθος της ενσωμάτωσης. Αυτή η ανάλυση παρέχει μια βάση για την επιλογή κατάλληλων τιμών υπερπαραμετρίας διατηρώντας παράλληλα το μέγεθος του μοντέλου εντός του στόχου των 150 MB.
Φιλτράρισμα δεδομένων
Το φιλτράρισμα δεδομένων αποτελείται από δύο κύρια βήματα. Πρώτον, καταργήθηκαν προτάσεις μεγαλύτερες από 20 λέξεις, καθώς οι μεταφραστές κινητής τηλεφωνίας έχουν σχεδιαστεί για να μεταφράζουν σύντομες προτάσεις. Δεύτερον, η επιλογή δεδομένων πραγματοποιήθηκε χρησιμοποιώντας σπάνια ανάκτηση N-gram. Αυτή η τεχνική στοχεύει να επιλέξει προτάσεις από τα διαθέσιμα δίγλωσσα δεδομένα που μεγιστοποιούν την κάλυψη του N-GRAM μέσα σε ένα μικρότερο σύνολο δεδομένων για συγκεκριμένο τομέα.
Η προσέγγιση περιελάμβανε τη διαλογή του πλήρους συνόλου δεδομένων με τη βαθμολογία σπάνιας κάθε πρότασης για να δοθεί προτεραιότητα στις πιο ενημερωτικές. Έστω χ να αντιπροσωπεύουν το σύνολο των n-grams στις προτάσεις που θα μεταφραστούν και w υποδηλώνει ένα από αυτά τα n-grams. Το C ( w ) υποδεικνύει τον αριθμό w στο σύνολο εκπαίδευσης της γλώσσας προέλευσης, ενώ το T είναι ένα όριο για τον προσδιορισμό του πότε ένα N-gram θεωρείται ασυνήθιστο. N ( w ) αναφέρεται στον αριθμό του w στην πρόταση προέλευσης f. Η βαθμολογία σπάνιας f είναι (1):
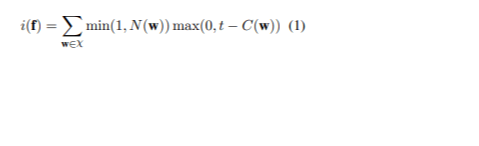
Για τα 60 εκατομμύρια προτάσεις από το Opus Corpus, μέχρι 5 n-grams εξήχθησαν από το Tatoeba Corpus, με στόχο το μέγιστο των 30 περιστατικών για κάθε N-gram. Για να διαχειριστεί το χρόνο εκτέλεσης, το σώμα χωρίστηκε σε έξι χωρίσματα, με την επιλογή που εκτελείται μεμονωμένα πριν από τη συγχώνευση των αποτελεσμάτων. Διεξήχθη μια τελική διαδικασία επιλογής για να εξασφαλιστεί ότι όχι n-gram ξεπέρασε το όριο εμφάνισης. Τελικά, αυτή η διαδικασία είχε ως αποτέλεσμα ένα σύνολο δεδομένων 740.000 προτάσεων με μέγεθος λεξιλογίου 19.400 λέξεων στη γλώσσα προέλευσης και 22.900 λέξεις στη γλώσσα -στόχο, με αποτέλεσμα ένα συνδυασμένο λεξιλόγιο 42.400 λέξεων. Το δείγμα βασίστηκε στο tokenized και stringified corpus.
Πειραματική ρύθμιση
Το σύστημα εκπαιδεύτηκε χρησιμοποιώντας το πλαίσιο Deep Learning OpenNMT, το οποίο επικεντρώνεται στην ανάπτυξη μοντέλων αλληλουχίας σε ακολουθία για μια ποικιλία εργασιών, συμπεριλαμβανομένης της μηχανικής μετάφρασης και της συνοπτικής συνόδου. Η κωδικοποίηση ζεύγους Byte (BPE) εφαρμόστηκε σε ένα επιλεγμένο σύνολο δεδομένων κατάρτισης και στη συνέχεια χρησιμοποιήθηκε για τα δεδομένα εκπαίδευσης, ανάπτυξης και δοκιμής. Χρησιμοποιήθηκε μια μακροχρόνια βραχυπρόθεσμη μνήμη (LSTM) επαναλαμβανόμενο νευρωνικό δίκτυο, συμπεριλαμβανομένου ενός παγκόσμιου στρώματος προσοχής για τη βελτίωση της μετάφρασης εστιάζοντας σε συγκεκριμένα τμήματα της προέλευσης. Η τροφοδοσία εισόδου χρησιμοποιήθηκε επίσης για να παρέχει διανύσματα προσοχής σε επόμενα βήματα χρόνου, αν και αυτό είχε μόνο αξιοσημείωτο αποτέλεσμα με τέσσερα ή περισσότερα στρώματα.
Η κατάρτιση περιελάμβανε 50 εποχές χρησιμοποιώντας το Adam Optimizer με ρυθμό μάθησης 0,0002. Το καλύτερο μοντέλο επιλέχθηκε με βάση την υψηλότερη βαθμολογία BLEU στο σύνολο ανάπτυξης και χρησιμοποιήθηκε για τη μετάφραση του σετ δοκιμών. Λόγω του μικρού μεγέθους του σετ δοκιμών, πραγματοποιήθηκε ανθρώπινη αξιολόγηση για να εκτιμηθεί η ποιότητα των μεταφράσεων.
Αποτέλεσμα και ανάλυση
Εκπαιδεύσαμε διαφορετικούς τύπους νευρωνικών δικτύων με βάση τις ιδέες στην ενότητα εξάρτησης του μοντέλου . Σε κάθε πείραμα, ρυθμίσαμε τα υπερπαραμετρικά διατηρώντας παράλληλα το συνολικό μέγεθος λεξιλογίου σταθερό σε 42,4k λέξεις. Ο Πίνακας 2 δείχνει τις τιμές υπερπαραμετρίας για κάθε πείραμα, καθώς και τα αποτελέσματα BLEU και τα μεγέθη μοντέλων.
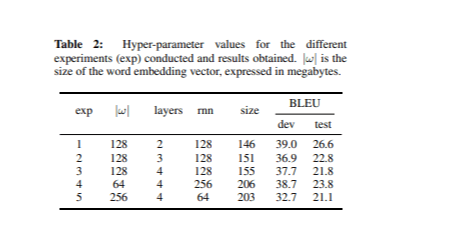
Το μοντέλο με τις καλύτερες επιδόσεις, όπως μετράται από τη βαθμολογία BLEU στο σύνολο ανάπτυξης, είχε 2 στρώματα και 128 μονάδες στο επαναλαμβανόμενο στρώμα με μέγεθος ενσωμάτωσης 128.
Τα προβλήματα που βρέθηκαν και οι λύσεις τους
Η ανάλυση των μεταφράσεων από το σύνολο δοκιμών αποκάλυψε τρία βασικά προβλήματα, για κάθε μία από τις οποίες προτάθηκε συγκεκριμένες λύσεις.
1. Επαναλαμβανόμενο πρόβλημα λέξεων
Το καλύτερο μοντέλο παρήγαγε σωστές μεταφράσεις για προτάσεις μεγαλύτερες από επτά λέξεις, αλλά συχνά δημιούργησαν επαναλαμβανόμενες λέξεις σε πολύ σύντομες προτάσεις (π.χ. "Perro Perro Perro "). Αυτό το πρόβλημα οφειλόταν στη διαφορά στο μήκος των προτάσεων μεταξύ των δεδομένων εκπαίδευσης και των δοκιμών, καθώς το σύνολο κατάρτισης περιείχε λίγες σύντομες προτάσεις (Εικόνα 2).
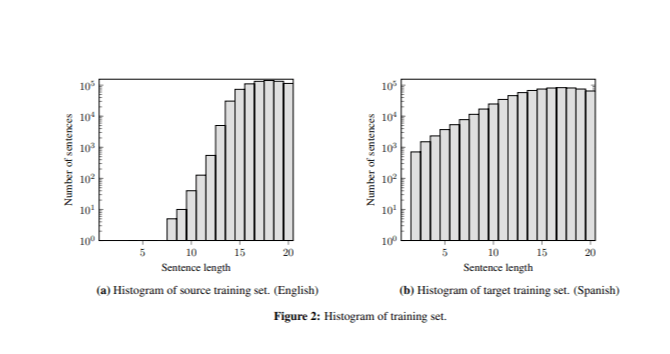
Για να μετριάσουμε αυτό, προσαρμόσαμε τη συνάρτηση βαθμολόγησης , προσθέτοντας ένα βήμα κανονικοποίησης (2). 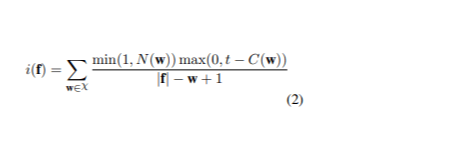
Αφού εφαρμόσαμε βαθμολογία απροσδόκητης συχνότητας για την επιλογή δεδομένων, επιλέξαμε ένα σύνολο δεδομένων 667.000 προτάσεων. Στον Πίνακα 3 παρουσιάζουμε το μέσο μήκος της φράσης στις γλώσσες πηγής και στόχου πριν και μετά την εφαρμογή της κανονικοποίησης του μήκους του προτάσεων.
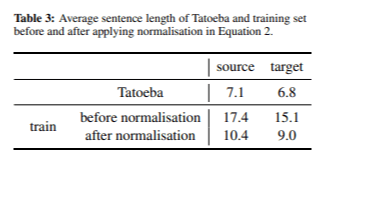
Η διαδικασία κανονικοποίησης μας επέτρεψε να επιτύχουμε σημαντικά συντομότερες προτάσεις τόσο στις γλώσσες πηγής όσο και στο στόχο. Το μοντέλο πέτυχε βαθμολογία BLEU 36,3 κατά τη διάρκεια της ανάπτυξης και 22,8 κατά τη διάρκεια των δοκιμών, με συνολικό μέγεθος μοντέλου 121 MB. Αν και αυτές οι βαθμολογίες είναι ελαφρώς χαμηλότερες από ό, τι σε προηγούμενα πειράματα, πιστεύουμε ότι το Bleu μπορεί να μην είναι πάντα ο καλύτερος δείκτης της ποιότητας μετάφρασης. Η χειρωνακτική ανάλυση επιβεβαίωσε ότι το πρόβλημα των επαναλαμβανόμενων λέξεων επιλύθηκε αποτελεσματικά.
2. Προσδοκία σημείων στίξης
Το μοντέλο παρήγαγε εσφαλμένες μεταφράσεις για πολύ σύντομες προτάσεις (π.χ. μετάφραση του "σκύλου" ως "amor") εκτός αν προστεθεί ένα σήμα στίξης (π.χ. "σκύλος"). Αυτό οφειλόταν στην προσδοκία του μοντέλου για στίξη στο τέλος των προτάσεων. Το 94% των ποινών κατάρτισης έληξε με ένα σημάδι στίξης. Προτάθηκαν δύο λύσεις για την αντιμετώπιση αυτού του ζητήματος:
- Ειδική λέξη Ending: Προσθέσαμε ένα ειδικό token @@ στο τέλος κάθε πρότασης. Αυτή η προσέγγιση εκπαιδεύει το μοντέλο για να αναγνωρίσει ότι κάθε πρόταση τελειώνει με @@, ενώ η προτελευταία λέξη μπορεί ή δεν μπορεί να είναι σημάδι στίξης. Αυτή η τεχνική εφαρμόστηκε ως ένα βήμα πριν και μετά την επεξεργασία, επομένως ονομάζεται Ειδική Λέξη Λέξη. Το μοντέλο χρησιμοποιώντας αυτή την τεχνική πέτυχε βαθμολογία BLEU 36,4 σε ανάπτυξη και 26,3 σε δοκιμές μετά από 21 εποχές, με μέγεθος 121 MB.
- Dual Corpus: Επέκταση του Corpus κατάρτισης συνδυάζοντας όλες τις υπάρχουσες προτάσεις που τελείωσαν με σημάδια στίξης, αφαιρώντας αυτούς τους χαρακτήρες. Αυτό επέτρεψε στο μοντέλο να μάθει ότι οι προτάσεις μπορούν να τελειώσουν με ή χωρίς σημάδι στίξης. Σε αυτή την περίπτωση, το μέγεθος του μοντέλου αυξήθηκε στα 156 MB, επιτυγχάνοντας βαθμολογία BLEU 37,3 σε ανάπτυξη και 25,1 σε δοκιμές.
Και οι δύο μέθοδοι επιλύουν αποτελεσματικά το πρόβλημα των προσδοκιών στίξης.
Ωστόσο, λόγω του μεγαλύτερου μεγέθους και της χαμηλότερης βαθμολογίας BLEU της στρατηγικής Dual Corpus, αποφασίσαμε να χρησιμοποιήσουμε μια ειδική τεχνική λήξης λέξεων.
3. Χαμένα τμήματα
Σημειώθηκε ότι κατά τη μετάφραση των τμημάτων που περιείχαν πολλαπλές σύντομες προτάσεις, μόνο η πρώτη από αυτές μεταφράστηκε (π.χ. "ευχαριστώ, αυτό ήταν πραγματικά χρήσιμο." Έγινε "Gracias").
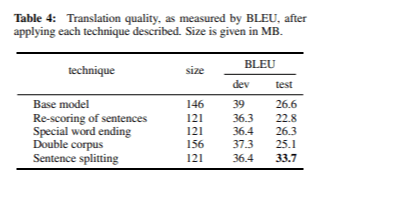
Για να αντιμετωπιστεί αυτό, εισήχθη ένα βήμα προεπεξεργασίας σε χωριστά τμήματα που βασίζονται σε σημάδια στίξης. Αυτή η προσαρμογή αύξησε τον αριθμό των τμημάτων από 86 σε 118 στο σύνολο δοκιμών. Μετά από αυτή την αλλαγή, οι μεταφράσεις βελτιώθηκαν σημαντικά, επιτυγχάνοντας βαθμολογία ανάπτυξης BLEU 36,4 και βαθμολογία δοκιμής 33,7, το υψηλότερο καταγεγραμμένο μέχρι σήμερα.
Τελική αξιολόγηση
Ο Πίνακας 4 συνοψίζει τις βαθμολογίες BLEU που λαμβάνονται μετά την εφαρμογή κάθε μιας από τις λύσεις που περιγράφονται σε προβλήματα που βρέθηκαν και τις λύσεις τους. Μετά την εφαρμογή του κανονικοποιημένου βαθμού απροσδόκητης συχνότητας, της ειδικής λέξης που τελειώνει και της προεπεξεργασίας των κατασκευασμένων προτάσεων, βελτιώσαμε την ποιότητα της δοκιμής που έθεσε περίπου 7 σημεία BLEU.
Στην τελική αξιολόγηση του συστήματος μετάφρασης μας, συγκρίναμε την ποιότητά του με τους μεταφραστές της Google και της Microsoft Mobile. Ο Πίνακας 5 παρουσιάζει τις βαθμολογίες BLEU και τα μεγέθη μοντέλων για κάθε μεταφραστή στο σύνολο δοκιμών.
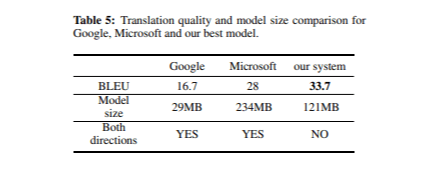
Συνολικά, και τα τρία συστήματα παρήγαγαν μεταφράσεις υψηλής ποιότητας, αν και παρατηρήθηκαν ορισμένες μικρές διαφορές. Το μοντέλο μας πραγματοποίησε ιδιαίτερα καλά με σημάδια στίξης και κεφαλαιοποίηση, ενώ η Google μεταφράζει συχνά άσχημα σημάδια στίξης και χρησιμοποίησε κεφαλαιοποίηση σπάνια. Αυτό μπορεί να εξηγήσει γιατί η Google Translate έλαβε χαμηλότερη βαθμολογία BLEU σε σύγκριση με τα άλλα δύο συστήματα, παρά το μικρότερο μέγεθος μοντέλου. Επιπλέον, τα μοντέλα της Google και της Microsoft είναι αμφίδρομα, πράγμα που σημαίνει ότι το μέγεθος του μοντέλου μας πρέπει να διπλασιαστεί (2 × 121 MB) για μια δίκαιη σύγκριση.
Σύναψη
Αυτό το έγγραφο περιγράφει την ανάπτυξη μιας συμπαγής μετάφραση νευρωνικής μηχανής για την αγγλική γλώσσα. Χρησιμοποιήσαμε μια μέθοδο επιλογής δεδομένων για να βελτιώσουμε την ικανότητα των δεδομένων εκπαίδευσης και κάναμε προσαρμογές για να βελτιώσουμε την ποιότητα της μετάφρασης. Προτάθηκαν λύσεις για την αντιμετώπιση των ζητημάτων επαναλαμβανόμενων λέξεων και των μεταφράσεων που λείπουν σε τμήματα. Το μοντέλο μας ξεπέρασε τους μεταφραστές Google και Microsoft Mobile σε βαθμολογίες BLEU, ειδικά στο χειρισμό της στίξης και της κεφαλαιοποίησης. Στα 121 MB, το μοντέλο μας είναι μικρότερο από ό, τι αρχικά εκτιμάται, παρέχοντας παράλληλα καλή ποιότητα μετάφρασης για τα περιβάλλοντα που σχετίζονται με τα ταξίδια. Οι μεταφράσεις είναι ομαλές και κατανοητές, κατάλληλες για χρήση εκτός σύνδεσης. Οι τρέχουσες προσπάθειες επικεντρώνονται στην περαιτέρω βελτίωση της ποιότητας και στη μείωση του μεγέθους του μοντέλου, συμπεριλαμβανομένων μεθόδων όπως η μείωση του βάρους.


