
Η Lingvanex αναπτύσσει λύσεις μετάφρασης μηχανών για πάνω από επτά χρόνια. Κάθε μήνα, επεξεργαζόμαστε δισεκατομμύρια σειρές δεδομένων σε περισσότερες από 100 γλώσσες για να εκπαιδεύσουν τα μοντέλα γλωσσών που προσφέρουν εξαιρετικές επιδόσεις. Αλλά πώς καταφέρνουμε να υποστηρίξουμε με συνέπεια ένα τόσο ευρύ φάσμα γλωσσών, βελτιώνοντας ταυτόχρονα την ποιότητα της μετάφρασης μετά τον μήνα;
Σε αυτό το άρθρο, θα μοιραστώ πληροφορίες από την έρευνά μας και τα εργαλεία που συμβάλλουν στην επιτυχία μας. Επίσης, θα εξετάσουμε ένα ισχυρό εργαλείο που έχει σχεδιαστεί για να βελτιώσει την ποιότητα της μετάφρασης κειμένου. Θα συζητήσουμε πώς αυτό το εργαλείο βοηθά στην προετοιμασία δεδομένων, στα μοντέλα μετάφρασης και στη δοκιμή της απόδοσής τους. Με τη διάσπαση των εμπλεκόμενων βημάτων, στοχεύουμε στην σαφή κατανόηση του τρόπου με τον οποίο η μετάφραση της γλώσσας μπορεί να βελτιωθεί μέσω συστηματικών διαδικασιών.

Βασικές πληροφορίες σχετικά με το στούντιο δεδομένων
Data Studio είναι ένα εργαλείο για την εργασία σε εργασίες NLP, το οποίο είναι απαραίτητο για τη βελτίωση της ποιότητας της μετάφρασης κειμένου. Χρησιμοποιώντας το στούντιο δεδομένων, μπορείτε να εκπαιδεύσετε μοντέλα μετάφρασης γλώσσας, να διαμορφώσετε διάφορες παραμέτρους για αυτές τις εκπαιδεύσεις, να μεταφέρετε τα δεδομένα, να φιλτράρετε τα δεδομένα με διάφορες παραμέτρους, να λάβετε μετρήσεις, να δημιουργήσετε δεδομένα κατάρτισης, δοκιμών και επικύρωσης κ.λπ.
Η γενική διαδικασία δημιουργίας ενός μοντέλου γλώσσας έχει ως εξής:
Προεπεξεργασία δεδομένων: Το στάδιο της προετοιμασίας δεδομένων πριν από την εκπαίδευση του μοντέλου.
Διήθηση με δομικά και σημασιολογικά φίλτρα.
Συλλογή ενός κοινού συνόλου δεδομένων: Αφαίρεση των πλεονασμάτων, ομοιόμορφα διανομής θεμάτων και μήκους, ταξινόμηση.
Ετικέτα για ταξινόμηση δεδομένων.
Φόρτωση ενός κοινού συνόλου δεδομένων σε στούντιο δεδομένων για επαλήθευση.
Δημιουργία δεδομένων για επικύρωση και δοκιμή του μοντέλου.
Εκπαίδευση του μοντέλου.
Διερεύνηση δοκιμών ποιότητας: δομικές και σημασιολογικές μετρήσεις μέτρησης.
Ανίχνευση σφαλμάτων στις μεταφράσεις, αναλύοντας σφάλματα σε σύνολα δεδομένων, διορθώνοντας τα και συμπληρώνοντας με ένα μεταφρασμένο μονο-Corpus, εάν είναι απαραίτητο.
Επαναλάβετε το στάδιο συλλογής ενός κοινού συνόλου δεδομένων.
Προετοιμασία δεδομένων
Για να δημιουργήσετε ένα μοντέλο γλώσσας για μετάφραση κειμένου, απαιτούνται 3 τύποι δεδομένων:
1) Το σύνολο δεδομένων κατάρτισης ή το σύνολο δεδομένων μάθησης
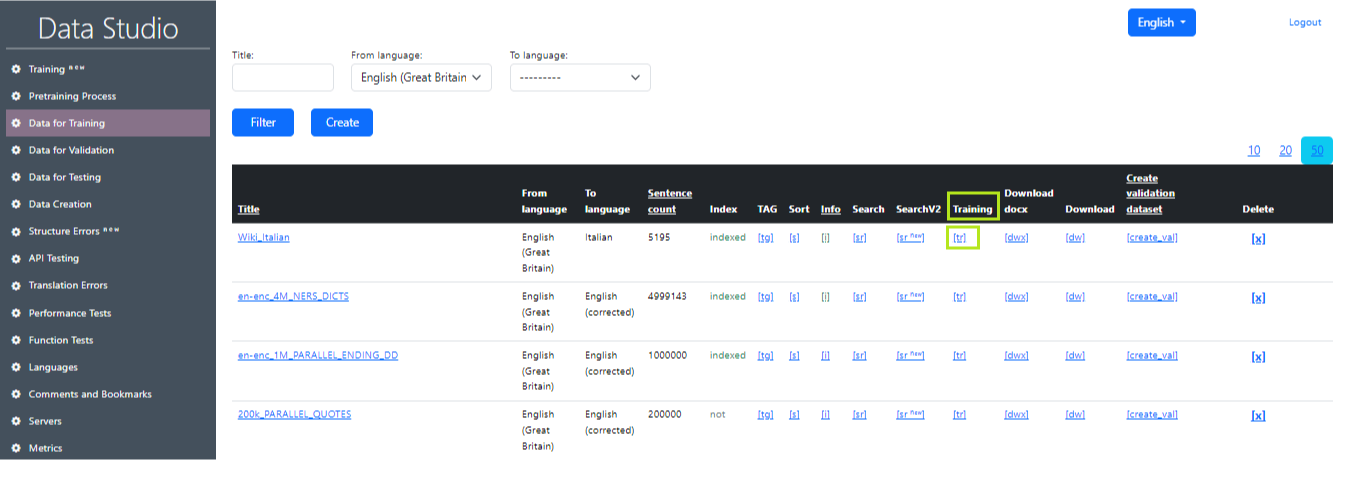
Ένα σύνολο δεδομένων που χρησιμοποιείται για την εκπαίδευση ενός μοντέλου γλώσσας. Αυτά είναι ζεύγη προτάσεων σε διαφορετικές γλώσσες (πηγή και στόχος). Μπορείτε να χρησιμοποιήσετε διάφορα σύνολα δεδομένων κατάρτισης ταυτόχρονα κατά την κατάρτιση ενός μοντέλου. Είναι σημαντικό να ληφθεί υπόψη η συνέπεια της μορφής και της δομής των δεδομένων, έτσι ώστε το μοντέλο να μπορεί να χρησιμοποιήσει σωστά πληροφορίες από όλα τα σύνολα δεδομένων κατάρτισης. Αυτό το παράθυρο εργασίας εμφανίζει τα παρασκευασμένα σύνολα δεδομένων μεγάλου όγκου (σύνολο δεδομένων) στο οποίο το μοντέλο AI εκπαιδεύεται για μετάφραση. Ένα παράδειγμα της οθόνης εργασίας "Δεδομένων εκπαίδευσης" στο στούντιο δεδομένων εμφανίζεται στην εικόνα 1.
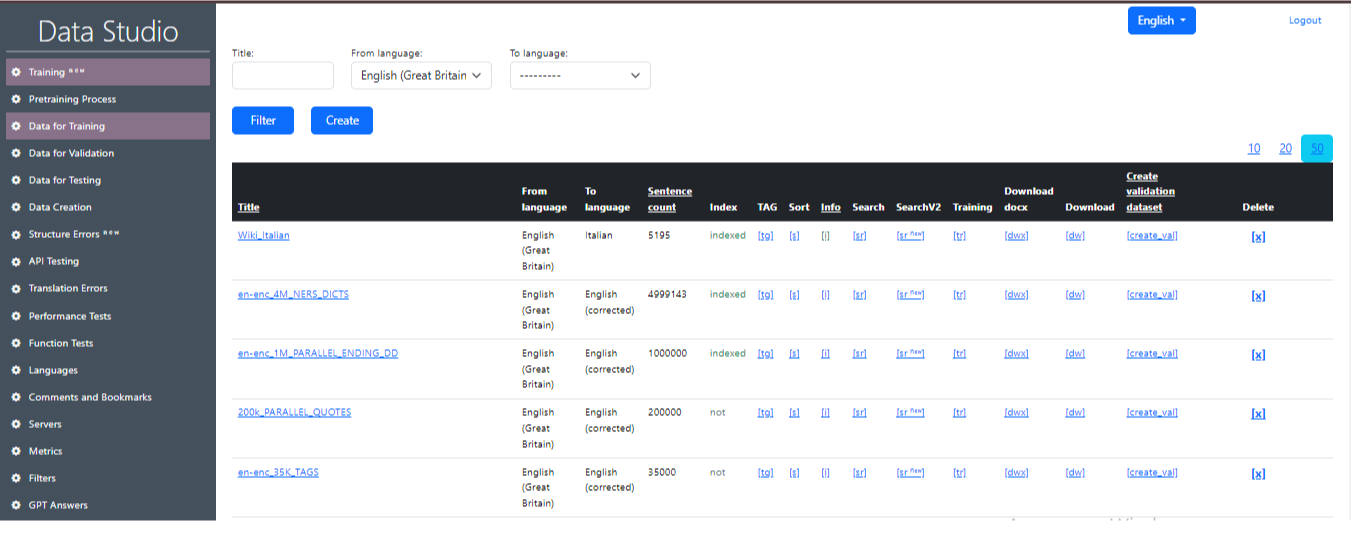
Περιγραφή τιμών στον πίνακα "Δεδομένα εκπαίδευσης":
- Τίτλος : Τίτλος που καθορίζει το όνομα της καταχώρησης.
- από τη γλώσσα : γλώσσα από την οποία γίνεται η μετάφραση.
- στη γλώσσα : γλώσσα στην οποία γίνεται η μετάφραση.
- μετρητής προτάσεων : αριθμός καταχωρήσεων (προτάσεις) στο αρχείο.
- Δείκτης : Εμφανίζει εάν το σύνολο δεδομένων είναι ευρετηριασμένο ή όχι (για να αποκτήσετε γρήγορη πρόσβαση σε αυτό).
- ετικέτα : αντικαθιστά ένα ορισμένο ποσοστό αριθμών στο σύνολο δεδομένων με & lt; tag & gt;. Είναι απαραίτητο για τη λογική που σηματοδοτεί λέξεις που δεν πρέπει να μεταφράζονται (όταν το μοντέλο είναι εκπαιδευμένο). Το ποσοστό της αντικατάστασης ετικετών έχει οριστεί στις ρυθμίσεις. Όταν εμφανιστεί η αντικατάσταση, δημιουργείται ένα νέο σύνολο δεδομένων με ένα όνομα (ετικέτα) στο τέλος.
- Ταξινόμηση : Ταξινόμηση του συνόλου δεδομένων με τον αριθμό των λέξεων στην πρόταση και αλφαβητικά, έτσι ώστε να είναι βολικό να το κοιτάξετε με τα μάτια σας για ανάλυση. Όταν εμφανιστεί η αντικατάσταση, δημιουργείται ένα νέο σύνολο δεδομένων με ένα όνομα (ταξινομημένο) στο τέλος.
- info : Παρέχει πληροφορίες σχετικά με το σύνολο δεδομένων.
- Αναζήτηση : Αναζητήστε συγκεκριμένες λέξεις και φράσεις στο σύνολο δεδομένων. Αυτή η λειτουργικότητα είναι απαραίτητη για να βρεθούν προτάσεις με λανθασμένη μετάφραση στο σύνολο δεδομένων. Για παράδειγμα, όπου η γάτα μεταφράζεται ως "σκύλος".
- Εκπαίδευση : Μετακινεί το σύνολο δεδομένων στη σελίδα εκπαίδευσης.
- Κατεβάστε : Κατεβάστε το αρχείο με το σύνολο δεδομένων στον υπολογιστή σας σε μορφή.
- download_doc x: Κατεβάστε το αρχείο με το σύνολο δεδομένων στον υπολογιστή σας σε μορφή.
- Δημιουργία επικύρωσης dt : δημιουργεί ένα αρχείο επικύρωσης από τα δεδομένα εκπαίδευσης. Οι παράμετροι ορίζονται στις ρυθμίσεις.
- Διαγραφή : Διαγράφει την εγγραφή.
2) Το σύνολο δεδομένων επικύρωσης
Αυτό το σύνολο δεδομένων χρησιμοποιείται για την αξιολόγηση της απόδοσης του μοντέλου κατά τη διάρκεια της εκπαίδευσης. Βοηθά στη βελτιστοποίηση των παραμέτρων του μοντέλου και εμποδίζει την υπερφόρτωση, επιτρέποντάς μας να αξιολογήσουμε πόσο καλά γενικεύει το μοντέλο στα δεδομένα που δεν έχει δει κατά τη διάρκεια της εκπαίδευσης.
Για παράδειγμα, ας πούμε ότι έχουμε αγγλικές προτάσεις και τις αντίστοιχες γαλλικές μεταφράσεις τους. Το σύνολο δεδομένων κατάρτισης θα περιέχει αυτά τα ζεύγη προτάσεων, όπου η αγγλική πρόταση θα είναι η είσοδος και η γαλλική μετάφραση θα είναι ο στόχος. Το μοντέλο θα εκπαιδευτεί σε αυτό το σύνολο δεδομένων, προσπαθώντας να προβλέψει τις σωστές γαλλικές μεταφράσεις για τις αγγλικές προτάσεις. Μετά την εκπαίδευση του μοντέλου στα δεδομένα εκπαίδευσης, θέλουμε να αξιολογήσουμε την απόδοσή του σε νέα δεδομένα. Για να γίνει αυτό, χρησιμοποιούμε το σύνολο δεδομένων επικύρωσης, το οποίο περιέχει επίσης ζευγάρια αγγλικών προτάσεων και τις γαλλικές μεταφράσεις τους. Τροφοδοτούμε τις αγγλικές προτάσεις από το σύνολο δεδομένων επικύρωσης στο μοντέλο και συγκρίνουμε τις προβλέψεις του με τις πραγματικές γαλλικές μεταφράσεις από αυτό το σύνολο δεδομένων. Αυτό μας επιτρέπει να αξιολογήσουμε πόσο καλά το μοντέλο γενικεύει στα δεδομένα που δεν έχει δει πριν.
Η χρήση δεδομένων κατάρτισης και επικύρωσης συμβάλλει στη δημιουργία ακριβέστερων και γενικευμένων μοντέλων μεταφραστών γλωσσών που μπορούν να μεταφράσουν αποτελεσματικά νέες προτάσεις σε άλλες γλώσσες. Ένα παράδειγμα της οθόνης εργασίας "Επικύρωσης δεδομένων" στο στούντιο δεδομένων εμφανίζεται στην εικόνα 2.
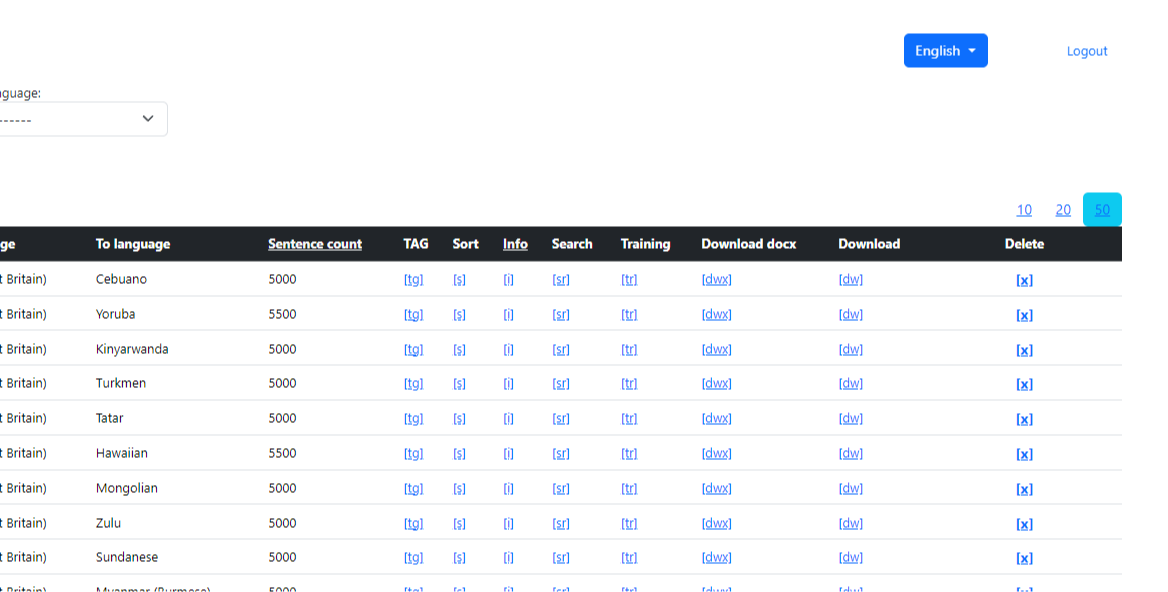
3) Δοκιμές δεδομένων
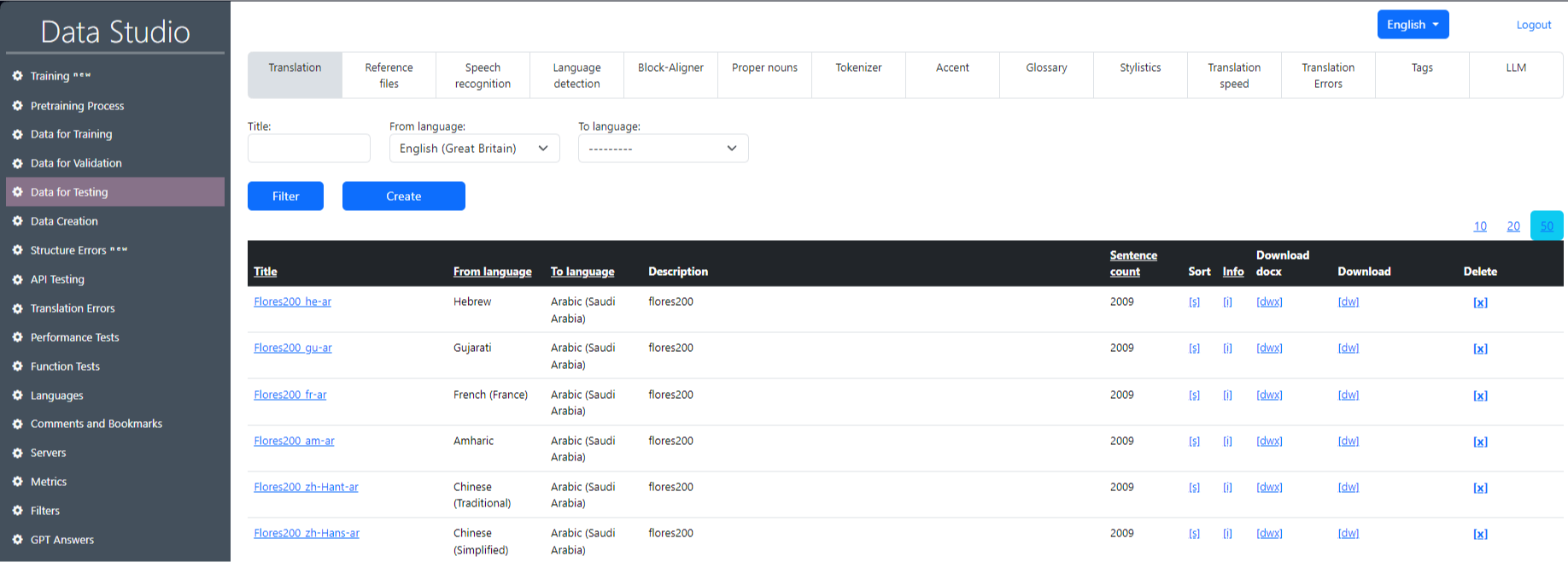
Αυτό το σύνολο δεδομένων είναι απαραίτητο για τη δοκιμή της ποιότητας των εκπαιδευμένων μοντέλων, χρησιμοποιώντας τα αρχεία που είναι αποθηκευμένα σε αυτό, χωρισμένα σε καρτέλες. Μόλις οριστικοποιηθούν το μοντέλο και τα υπερπαραμετρικά χρησιμοποιώντας τα σύνολα εκπαίδευσης και επικύρωσης, το σύνολο δοκιμών χρησιμοποιείται για την αξιολόγηση της απόδοσης του μοντέλου. Ένα παράδειγμα της οθόνης εργασίας "Δοκιμών δεδομένων" στο στούντιο δεδομένων εμφανίζεται στην Εικόνα 3.
Διαδικασία προ-κατάρτισης
Προηγουμένως, πραγματοποιήθηκαν ταυτόχρονα οι διαδικασίες κατάρτισης Tokenization και μοντέλων, οι οποίες είχαν ως αποτέλεσμα τον χρόνο αδράνειας GPU (η ενοικίαση διακομιστή καταβάλλεται ανεξάρτητα από το εάν το μοντέλο εκπαιδεύεται ή όχι) ενώ περιμένει να ολοκληρωθεί ο Tokenization στην CPU. Για τη βελτιστοποίηση της χρήσης των πόρων, αναπτύχθηκε μια "διαδικασία πριν από την κατάρτιση". Τώρα ο Tokenization εκτελείται ξεχωριστά από την κατάρτιση, η οποία επιτρέπει την κατάρτιση μοντέλων στη GPU χωρίς διακοπές. Ένα παράδειγμα της οθόνης εργασίας "πριν από την προπόνηση" στο στούντιο δεδομένων και μια από τις διακύμανσης των προκαταρκτικών εργασιών παρουσιάζονται στην εικόνα 4 και την εικόνα 5.
Η ποιότητα της μετάφρασης του εκπαιδευμένου μοντέλου εξαρτάται από:
- Δεδομένα κατάρτισης ·
- Ορίστε παραμέτρους για το νευρωνικό δίκτυο κατά τη διάρκεια της εκπαίδευσης.
- Παράμετροι συμπερασμάτων.
- Μορφοποίηση κειμένου πριν μεταβεί στο νευρωνικό δίκτυο (σπάζοντας μακρές προτάσεις σε μικρά κομμάτια και συγκόλληση μεταφράσεων μαζί αργότερα, φέρνοντας διαφορετικά εισαγωγικά και άλλα σύμβολα σε τυποποιημένα).
Διαδικασία για τη διεξαγωγή της διαδικασίας προ-κατάρτισης
Για να εκτελέσετε το Tokenization, πρέπει να κάνετε τα εξής:
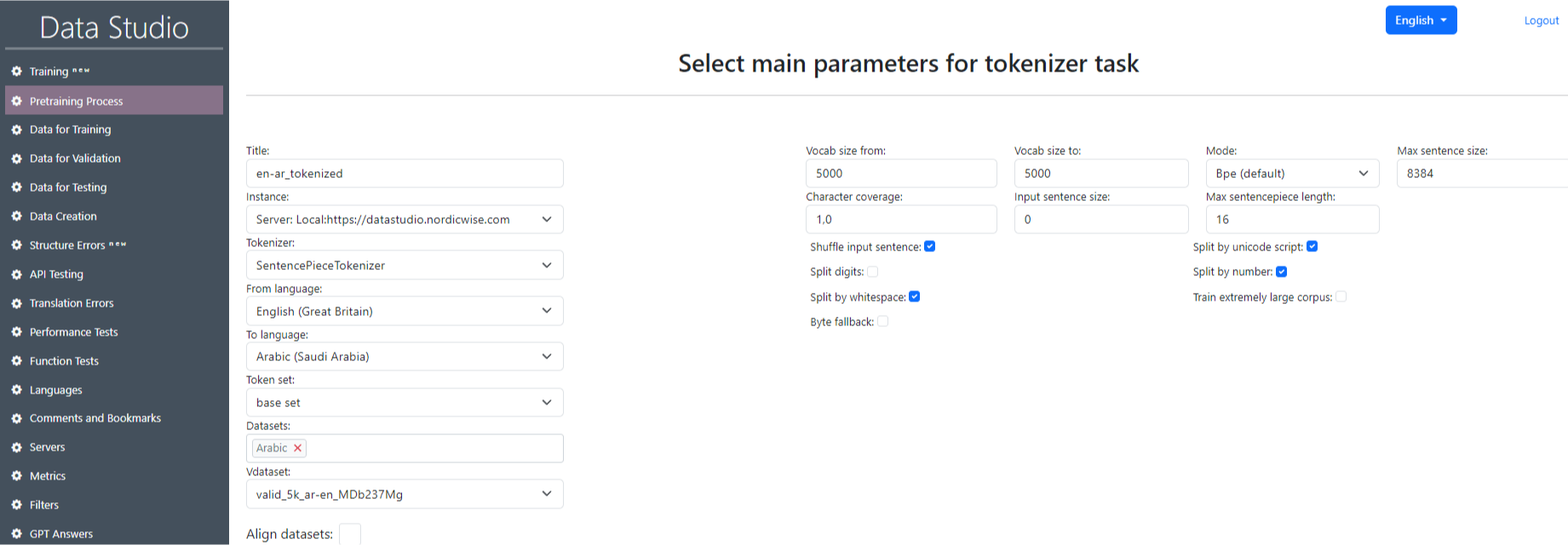
Κάντε κλικ στο κουμπί "Δημιουργία" στο κύριο παράθυρο της ενότητας "Pre-Training Process" (Εικόνα 6).

Στην ανοιχτή σελίδα "Επιλέξτε Κύριες παραμέτρους για την εργασία Tokenizer" Συμπληρώστε όλα τα πεδία χρησιμοποιώντας τους πίνακες 3.1 "Παράμειες παραμέτρους Tokenization", 3.2 "Παράμειες παραμέτρους Tokenization" OpenNMTTokenizer ". Κάντε κλικ στην επιλογή "Υποβολή". Μετά από αυτό, η εργασία που δημιουργήσαμε θα εμφανιστεί στον πίνακα στην κύρια σελίδα της ενότητας.
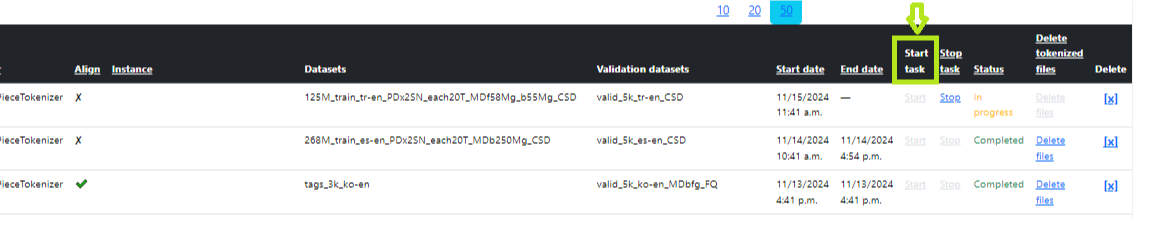
Στον πίνακα στην κύρια σελίδα της ενότητας, βρείτε την εργασία που δημιουργήσαμε και κάντε κλικ στο "Ξεκινήστε" απέναντι από την εργασία μας (Εικόνα 7 - Έναρξη του Tokenization). Μετά την εκτόξευση, η κατάσταση θα είναι "in_queue", λίγο αργότερα - "ξεκίνησε", μετά την ολοκλήρωση - "ολοκληρωμένη". Μπορείτε να ξεκινήσετε πολλές διαδικασίες tokenization ταυτόχρονα. Σε αυτή την περίπτωση, μετά τη δημιουργία, κάντε κλικ στην επιλογή "Ξεκινήστε" για καθένα. Όλες οι εργασίες πρέπει να τοποθετηθούν στην ουρά (στην ουρά) και να εκτελούνται διαδοχικά το ένα μετά το άλλο. Μετά την εκτόξευση, όλα θα έχουν την κατάσταση "in_queue". Μετά την επιτυχή εκτέλεση, η κατάσταση θα ενημερωθεί διαδοχικά στο "ολοκληρωμένο". Μετά την επιτυχή συμβουλή, το σύνολο δεδομένων θα είναι διαθέσιμο για επιλογή στο πεδίο "Προαπαιτούμενα δεδομένα" στην ενότητα "Εκπαίδευση V2".
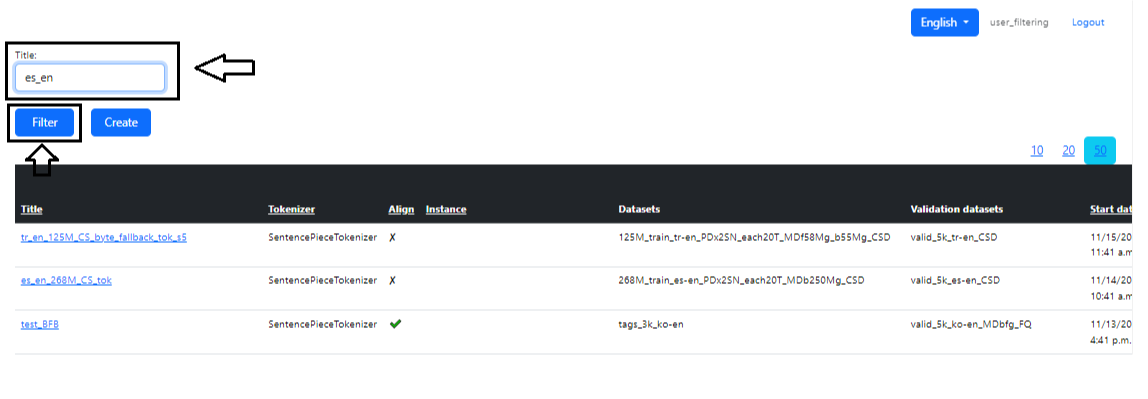
Στην κύρια σελίδα της ενότητας υπάρχει μια αναζήτηση για την εργασία που χρειαζόμαστε. Για να το κάνετε αυτό, πρέπει να πληκτρολογήσετε το όνομα της εργασίας ή μέρος του στο πεδίο "Όνομα" και κάντε κλικ στο "Φίλτρο". Μπορείτε επίσης να ταξινομήσετε στον ίδιο τον πίνακα κάνοντας κλικ στα ονόματα στηλών (Εικόνα 8 - Αναζήτηση).
Για να διαγράψετε μια εργασία, πρέπει να κάνετε κλικ στο σταυρό στη στήλη "Διαγραφή" απέναντι από την εργασία που χρειάζεστε (Εικόνα 9 - Διαγραφή).

Εκπαίδευση
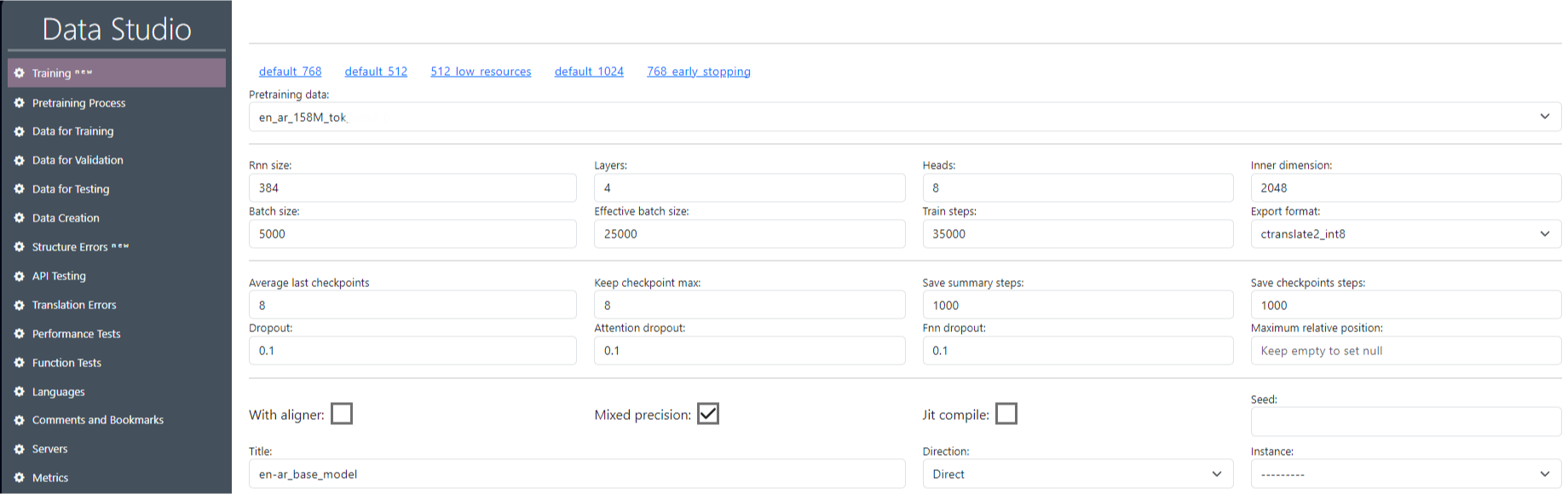
Κάθε εκπαίδευση δημιουργεί ένα μοντέλο για μία κατεύθυνση μετάφρασης, για παράδειγμα Αγγλικά-Γαλλικά. Για να κάνετε έναν μεταφραστή, για παράδειγμα από τα ρωσικά στα αγγλικά, πρέπει να εκπαιδεύσετε προς την άλλη κατεύθυνση. Εάν κάνουμε ένα μοντέλο μετάφρασης από την αγγλική σε γλώσσα x, προς την παράμετρο κατεύθυνσης - καθορίστε "άμεση", εάν από τη γλώσσα x στα αγγλικά, τότε προς την παράμετρο κατεύθυνσης - καθορίστε "αντίστροφη". Η πρώτη και η δεύτερη γλώσσα δεν είναι απαραιτήτως αγγλικά, άμεσα - απλά δείχνει ότι η επιλογή των γλωσσών από και προς τα αριστερά προς τα δεξιά. Πριν ξεκινήσετε την εκπαίδευση, πρέπει να ορίσετε τις παραμέτρους για αυτήν την εκπαίδευση (Εικόνα 10).
Για να εκτελέσετε μια προπόνηση, πρέπει να κάνετε τα εξής:
Προσθέστε δεδομένα εκπαίδευσης. Κάντε κλικ στο "TR" (Εικόνα 11) στη σειρά του συνόλου δεδομένων που χρειαζόμαστε στον πίνακα "Δεδομένα κατάρτισης". Μετά από αυτό, το σύνολο δεδομένων θα είναι διαθέσιμο για επιλογή στην ενότητα "Εκπαίδευση".
Προσθέστε δεδομένα για επικύρωση. Κάντε κλικ στο "TR" (Εικόνα 12) στη σειρά του απαιτούμενου συνόλου δεδομένων επικύρωσης στον πίνακα "Δεδομένα επικύρωσης". Μετά από αυτό, το σύνολο δεδομένων επικύρωσης θα είναι διαθέσιμο για επιλογή στην ενότητα "Εκπαίδευση".
Στην ενότητα "Εκπαίδευση", καθορίστε όλες τις απαραίτητες παραμέτρους (PenencePieCeTokenizer και OpenNMT Tokenizer Tokenization Parameters και παραμέτρους μοντέλου), καθώς και "τίτλο" (το όνομα της εκπαίδευσής μας).
Επιλέξτε τα απαραίτητα σύνολα δεδομένων κατάρτισης και επικύρωσης.
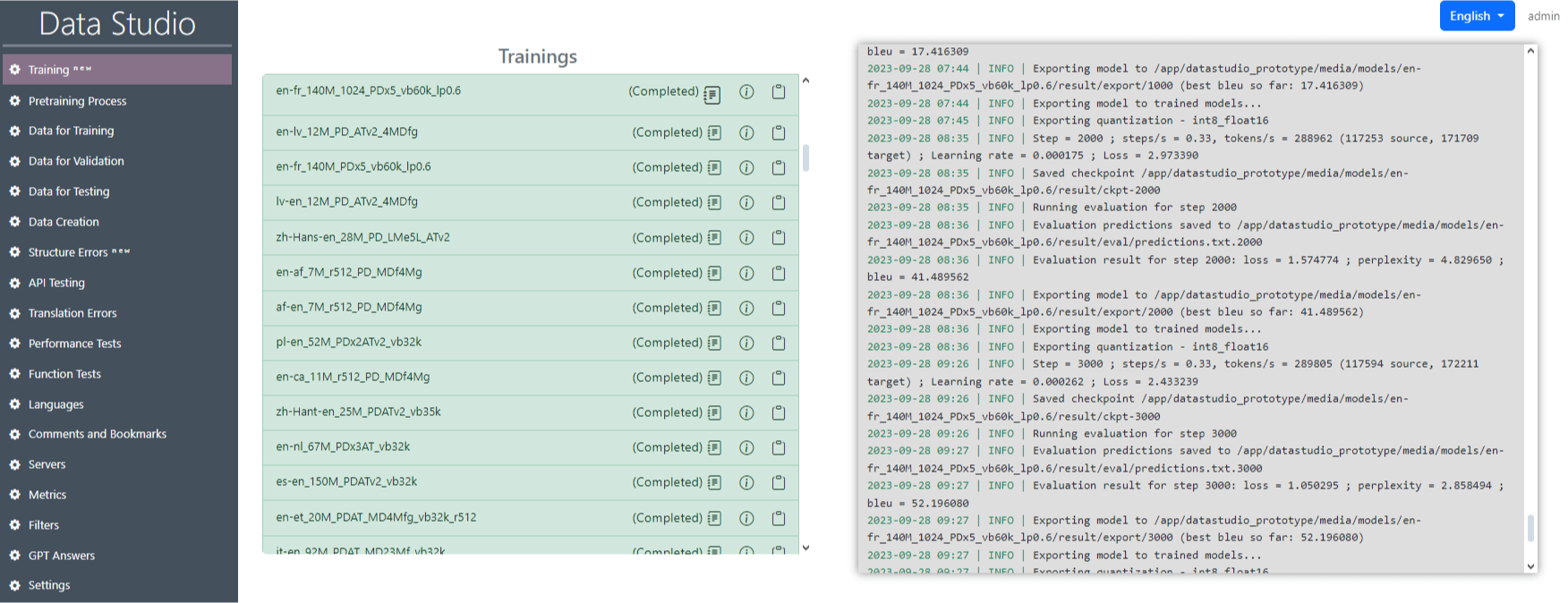
Κάντε κλικ στο κουμπί "Δημιουργία και εκτέλεση" (Εικόνα 13). Μετά από αυτό, η εκπαίδευση θα ξεκινήσει και τα αρχεία θα αρχίσουν να εμφανίζονται στα αρχεία καταγραφής (Εικόνα 14).

Δοκιμασία
Υπάρχουν δύο ειδικά τμήματα στο στούντιο δεδομένων για την παρακολούθηση της ποιότητας της μετάφρασης: API Testing και Σφάλματα δομής . Ας εξετάσουμε με περισσότερες λεπτομέρειες το καθένα από αυτά
Δοκιμή API
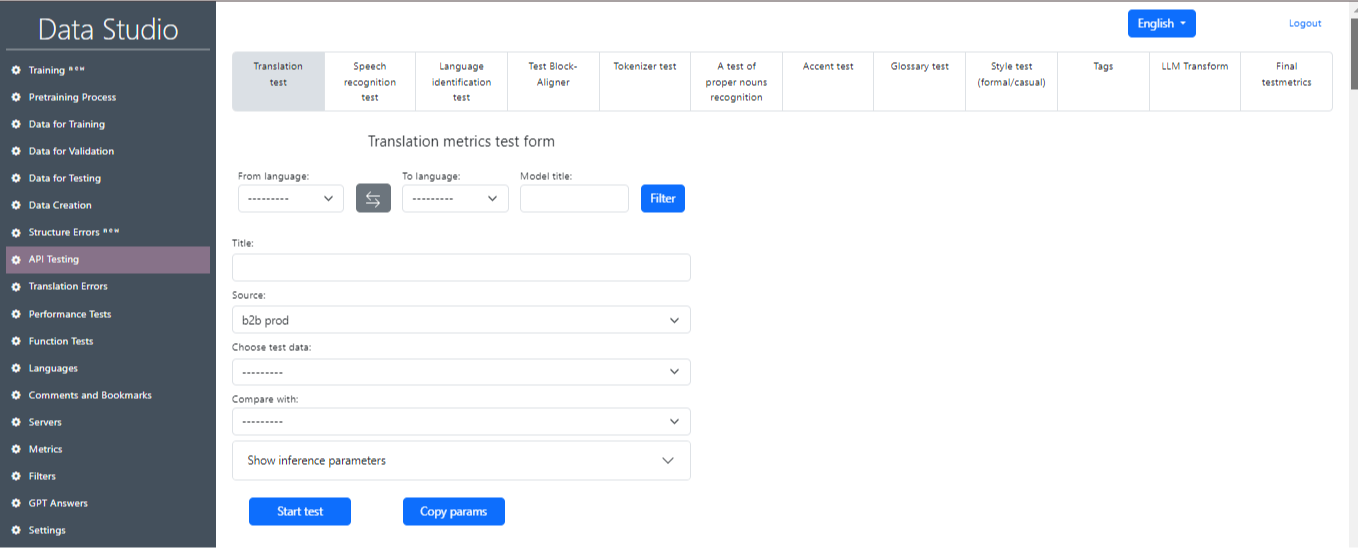
Το τμήμα δοκιμών API προορίζεται για τη δοκιμή του εκπαιδευμένου μοντέλου σύμφωνα με τις μονάδες όπως η δοκιμή μετάφρασης, η δοκιμή αναγνώρισης ομιλίας, η δοκιμή αναγνώρισης γλώσσας και άλλοι (Εικόνα 15). Είναι επίσης δυνατό να ληφθεί ένας συνοπτικός πίνακας των τελικών μετρήσεων δοκιμής (Εικόνα 16).
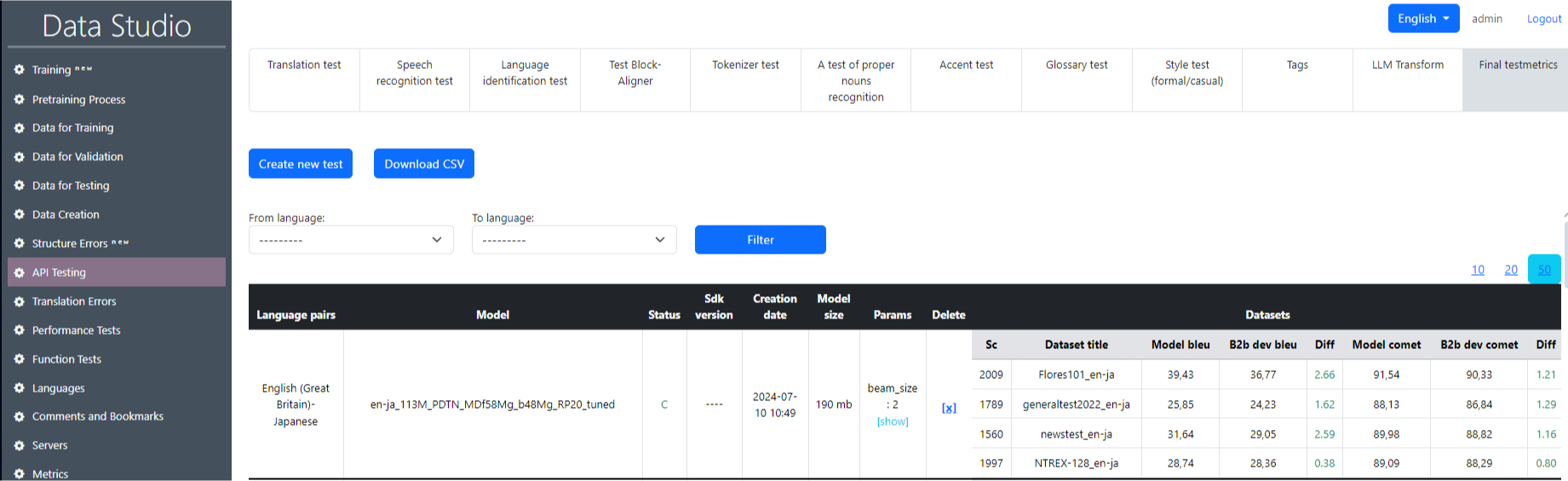
Ακολουθεί μια κατανομή του τι αντιπροσωπεύει κάθε στήλη και μετρική σε αυτή την ενότητα:
τελικό μπλοκ
- Ημερομηνία : Η χρονική σήμανση όταν εκτελέστηκε κάθε δοκιμή.
- Από/στη γλώσσα : Οι γλώσσες πηγής και στόχου για δοκιμές μετάφρασης.
- Κατάσταση : Υποδεικνύει την κατάσταση της δοκιμής μετάφρασης (όλα σημειώνονται ως ολοκληρωμένα).
- Μοντέλο : Το συγκεκριμένο μοντέλο που χρησιμοποιείται για μετάφραση (μερικά πεδία είναι κενά, που υποδηλώνουν απροσδιόριστα μοντέλα).
- Δοκιμαστικό σύνολο δεδομένων : Το σύνολο δεδομένων που χρησιμοποιείται για δοκιμές, όπως το "Flores200", το "NTREX-128" ή άλλες που αντιπροσωπεύουν διαφορετικές συλλογές δεδομένων για δοκιμές μετάφρασης γλωσσών.
- Αριθμός προτάσεων : ο αριθμός των προτάσεων στο σύνολο δεδομένων δοκιμών.
- Server : Το όνομα του διακομιστή που χρησιμοποιείται για την εκτέλεση της δοκιμής.
- BLEU : Μια μέτρηση που αξιολογεί την ποιότητα της μετάφρασης συγκρίνοντας το κείμενο μεταφράσεων με μηχανές σε μία ή περισσότερες μεταφράσεις αναφοράς. Οι υψηλότερες βαθμολογίες BLEU υποδεικνύουν γενικά μεταφράσεις υψηλότερης ποιότητας.
- bleu ref : Η βαθμολογία αναφοράς BLEU, ενδεχομένως υποδεικνύοντας μια τέλεια ή προηγούμενη βαθμολογία αναφοράς.
- bleu diff : Η διαφορά μεταξύ της τρέχουσας βαθμολογίας BLEU και της βαθμολογίας αναφοράς, που παρουσιάζεται με πράσινο (θετική διαφορά) ή κόκκινο (αρνητική διαφορά).
- Comet : Μια άλλη μέτρηση ποιότητας μετάφρασης, ενδεχομένως πιο ευαίσθητη στο περιβάλλον από το BLEU.
- comet ref : Η βαθμολογία αναφοράς Comet.
- comet diff : Η διαφορά στη βαθμολογία Comet σε σχέση με το σημείο αναφοράς.
- Χρόνος μετάφρασης : Ο χρόνος που χρειάστηκε για να ολοκληρωθεί η μετάφραση, πιθανώς σε δευτερόλεπτα.
- Διαγραφή : Δυνατότητα διαγραφής της δοκιμαστικής εγγραφής.
Η πρώτη διαφορά εξάγει τη βαθμολογία bleu , η δεύτερη εξάγει τη βαθμολογία comet . Το Bleu και ο Comet είναι μετρήσεις που χρησιμοποιούνται για την αξιολόγηση της ποιότητας της μηχανικής μετάφρασης:
- bleu : μια στατιστική μέτρηση που μετρά την επικάλυψη των n-grams (ακολουθίες λέξεων) μεταξύ μεταφράσεων μηχανών και μεταφράσεων αναφοράς. Είναι απλό, γρήγορο και ευρέως χρησιμοποιούμενο, αλλά δεν λαμβάνει υπόψη τα συνώνυμα ή το πλαίσιο.
- Comet : Μια νευρική μέτρηση που χρησιμοποιεί βαθιά μάθηση για να αξιολογήσει τις μεταφράσεις συγκρίνοντας την πηγή, την αναφορά και τον υποψήφιο. Καταγράφει καλύτερα το νόημα και το πλαίσιο, που ταιριάζει περισσότερο με την ανθρώπινη κρίση, αλλά είναι υπολογιστικά δαπανηρή.
Το αρχείο με τη διεξαγωγή δοκιμών μοιάζει με αυτό (εικόνα 17). Η διεπαφή παρέχει μια κατανομή της ποιότητας μετάφρασης μεταξύ διαφορετικών εκδόσεων των μεταφράσεων για μεμονωμένες προτάσεις στο σύνολο δεδομένων. Ακολουθεί μια εξήγηση των στοιχείων σε αυτήν την οθόνη:
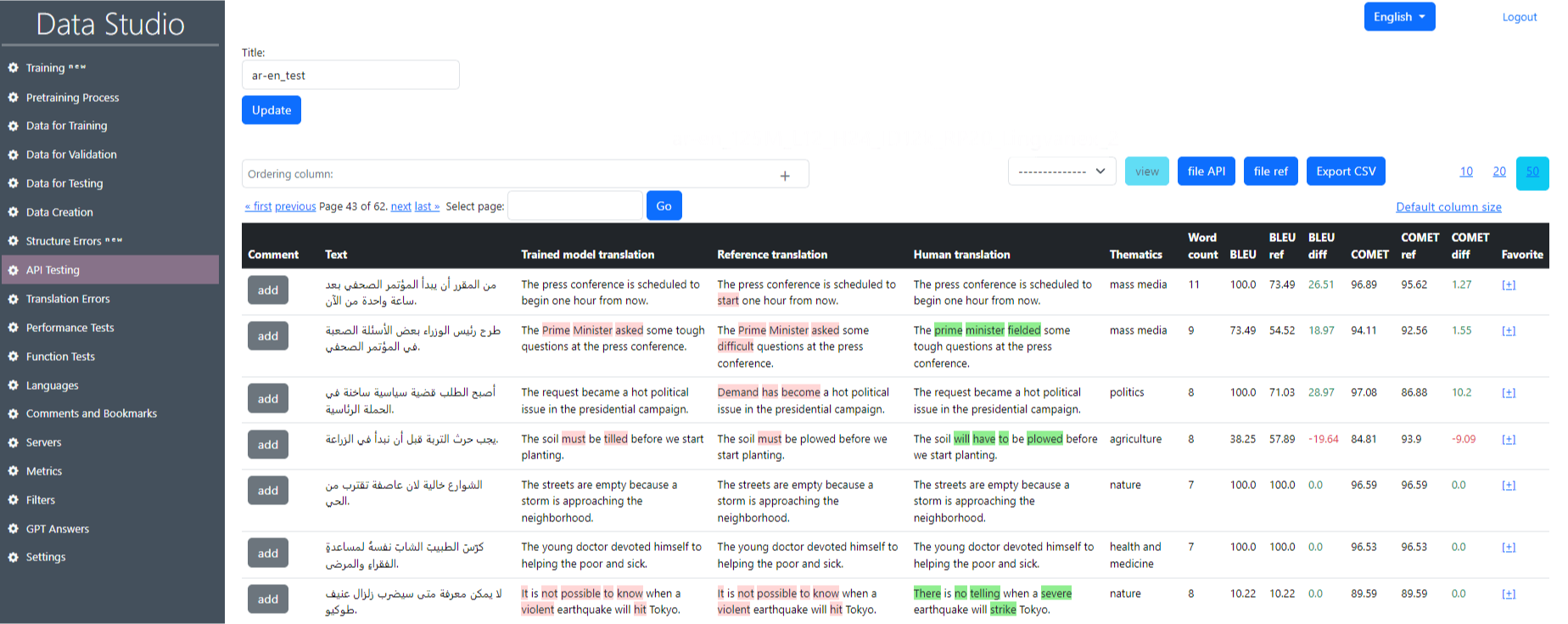
- Σχόλιο : Η δυνατότητα προσθήκης μιας περιγραφής.
- Κείμενο : Αυτό είναι το αρχικό κείμενο που στάλθηκε για μετάφραση.
- Μετάφραση αναφοράς : Το αποτέλεσμα του μοντέλου αρχείου API/αναφοράς.
- Ανθρώπινη μετάφραση : μετάφραση που γίνεται από έναν άνθρωπο.
- θεματική : Θέμα μετάφρασης.
- Count Word : ο αριθμός των λέξεων σε μια πρόταση.
- bleu : Μετρική αξιολόγηση.
- bleu ref : ref. Μετρική αξιολόγηση αρχείων.
- bleu diff: διαφορά μεταξύ Metric Bleu Ref και Bleu.
- Comet : Μετρική αξιολόγηση.
- comet ref : ref. Μετρική αξιολόγηση αρχείων.
- Διαφορά Comet: μεταξύ του μετρικού κομήτη και του κομήτη.
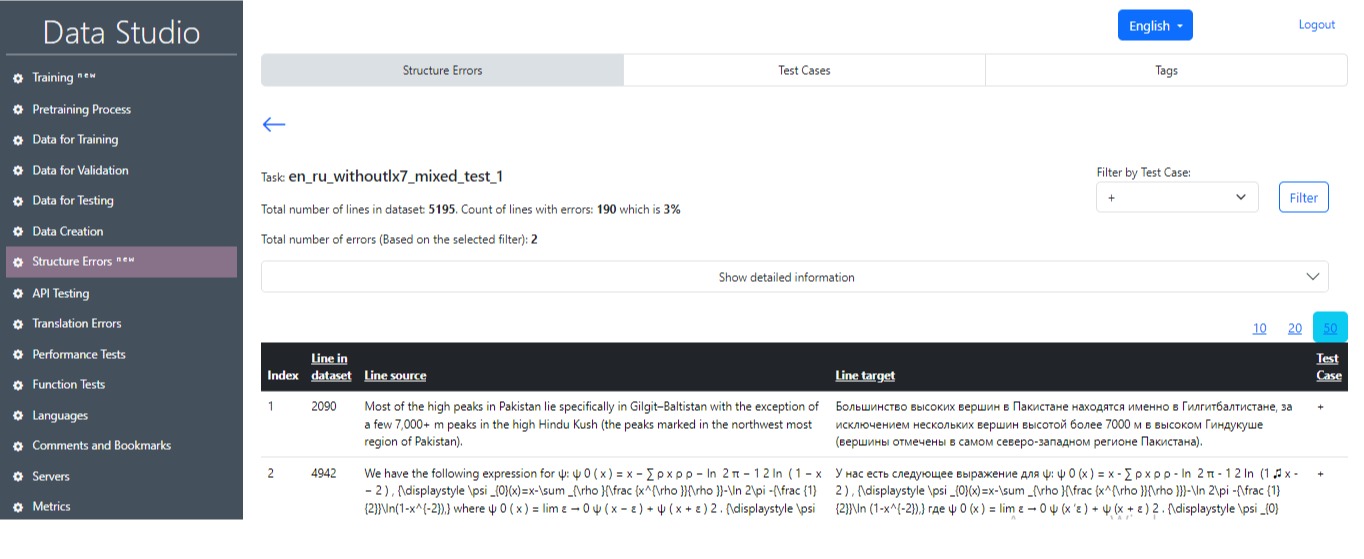
Σφάλματα δομής
Η κύρια σελίδα της ενότητας δομικών σφαλμάτων εμφανίζεται στην εικόνα 18 και φέρει μερικά επιπλέον διαμερίσματα:
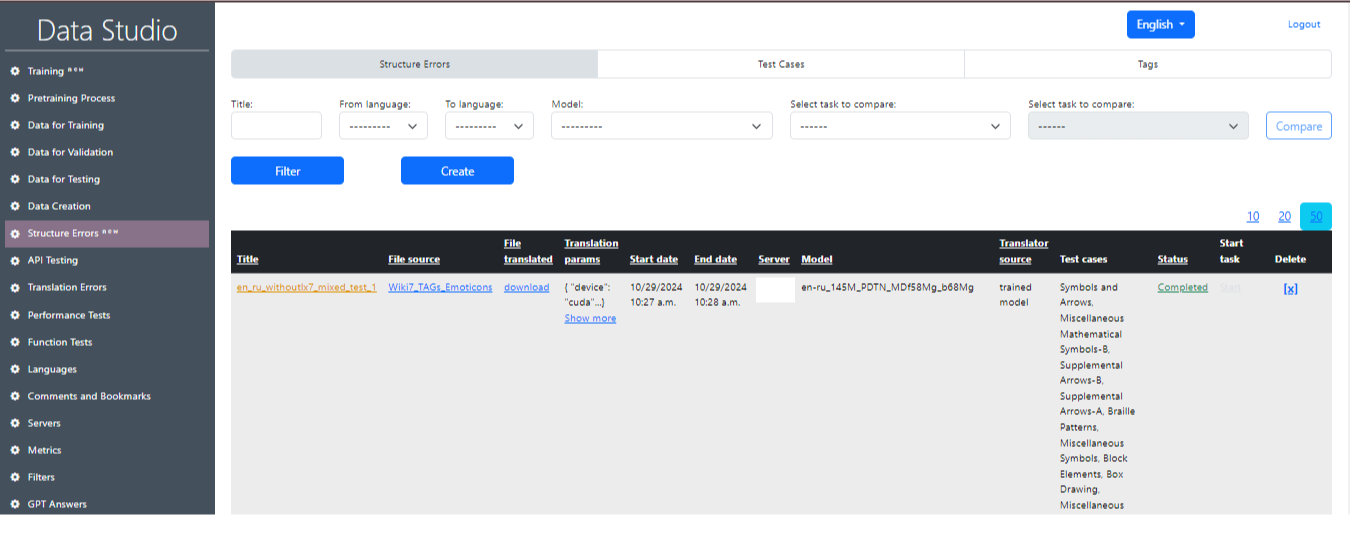
1) Σφάλματα δομής :
- Τίτλος: Αυτό το πεδίο σας επιτρέπει να εισαγάγετε έναν τίτλο για τα σφάλματα δομής.
- Από τη γλώσσα: Αυτό το μενού σας επιτρέπει να επιλέξετε τη γλώσσα προέλευσης.
- Στη γλώσσα: Αυτό το μενού σας επιτρέπει να επιλέξετε τη γλώσσα -στόχο.
- Μοντέλο: Αυτό το αναπτυσσόμενο μενού σας επιτρέπει να επιλέξετε το μοντέλο που θα χρησιμοποιηθεί.
- Επιλέξτε την εργασία για να συγκρίνετε: Επιλογή ενός TASC με LX7 και χωρίς LX7 για να συγκρίνετε τα αποτελέσματα των δύο δοκιμών.
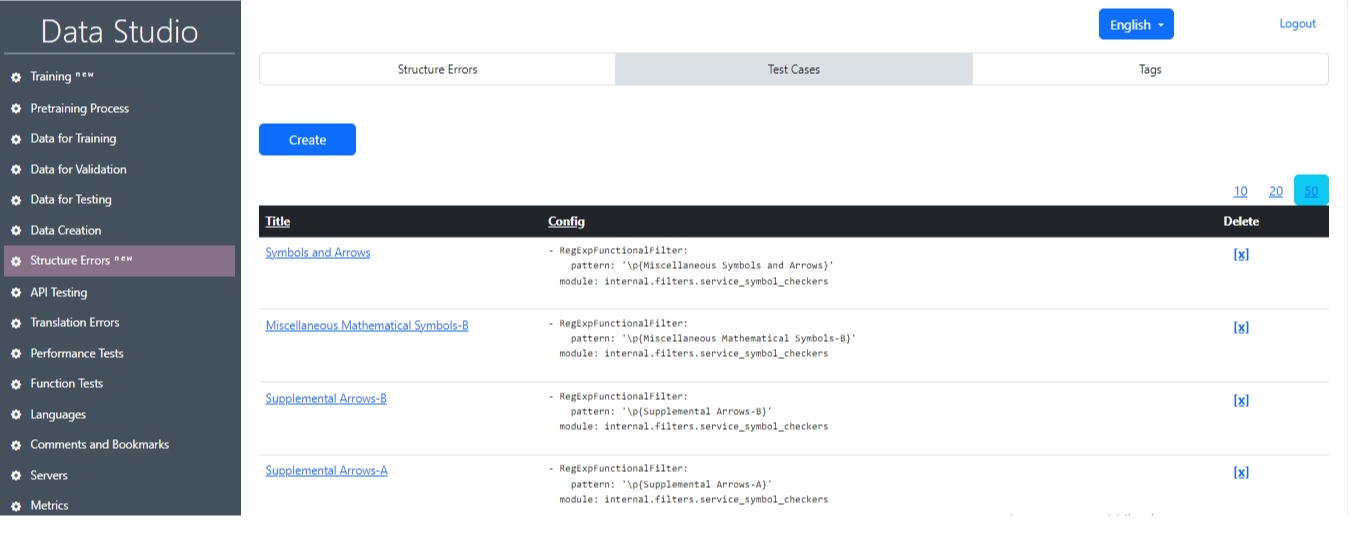
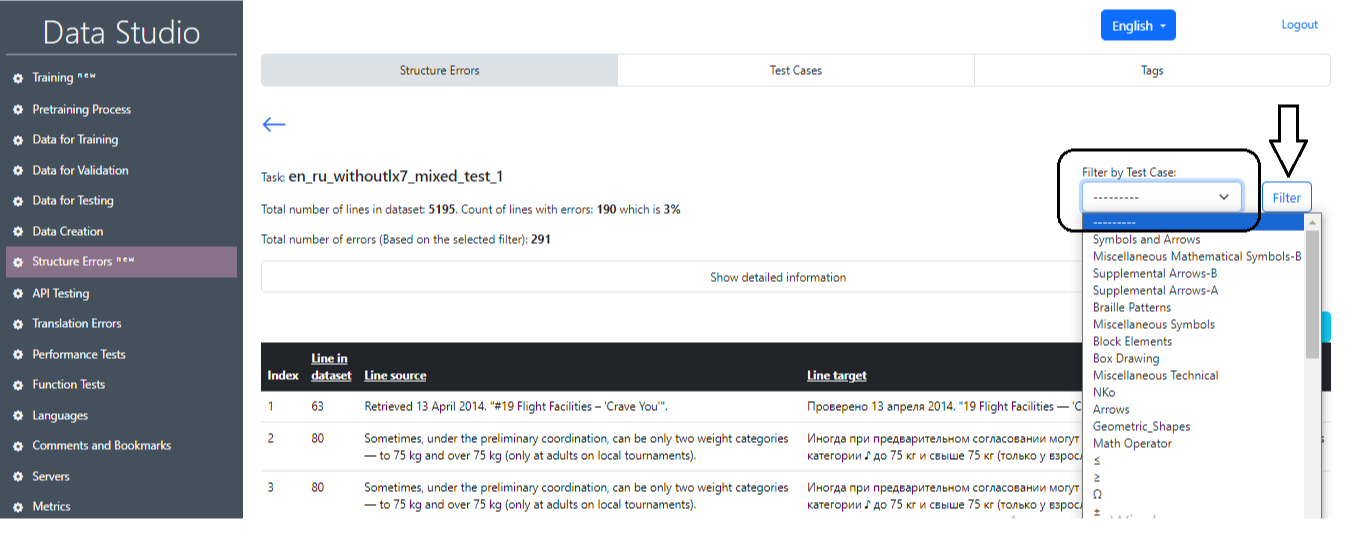
2) Περιπτώσεις δοκιμής (Εικόνα 19): Αυτή η ενότητα εμφανίζει περιπτώσεις δοκιμών που χρησιμοποιούνται για την εύρεση σφαλμάτων. Η λειτουργία αυτών των δοκιμαστικών περιπτώσεων βασίζεται σε κανονικές εκφράσεις και φίλτρα.
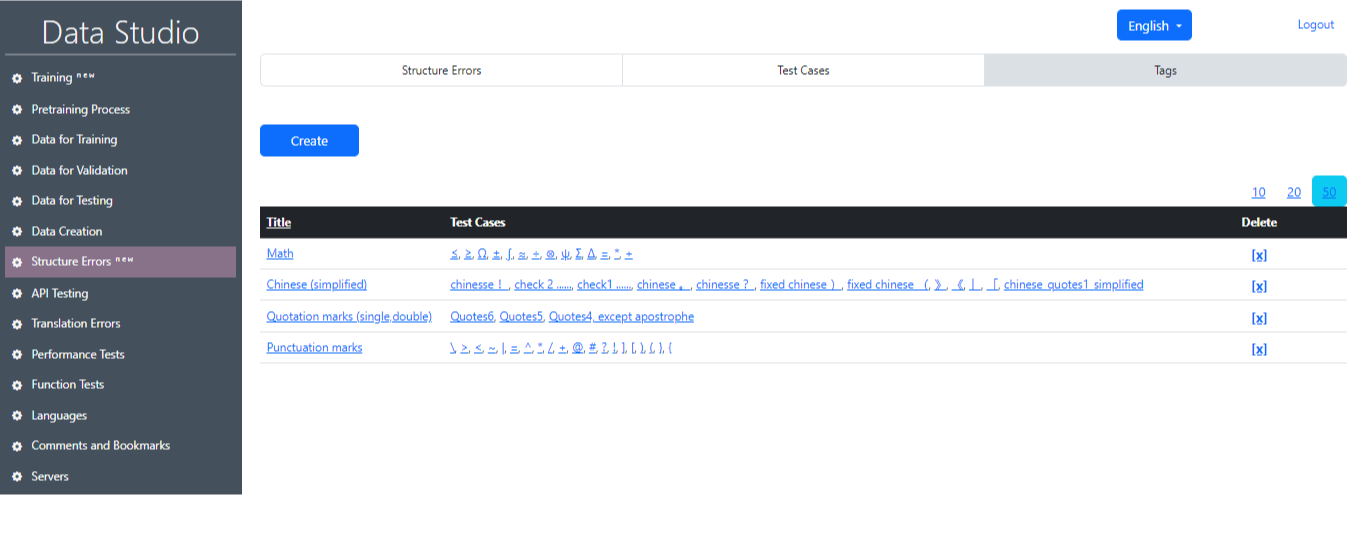
3) Ετικέτες (Εικόνα 20): Σε αυτή την ενότητα ο χρήστης μπορεί να επιλέξει μια συγκεκριμένη ομάδα δοκιμαστικών περιπτώσεων. Αυτές οι περιπτώσεις δοκιμών ομαδοποιούνται με βάση τις κατηγορίες εργασιών, π.χ. σύμβολα και βέλη, διάφορα, μαθηματικά κ.λπ. ή γλώσσα.
Το Image 21 δείχνει μια λεπτομερή προβολή μιας συγκεκριμένης εργασίας μετάφρασης στη διεπαφή στούντιο δεδομένων. Ας περιγράψουμε τα βασικά τμήματα και τις πληροφορίες που παρουσιάζονται:
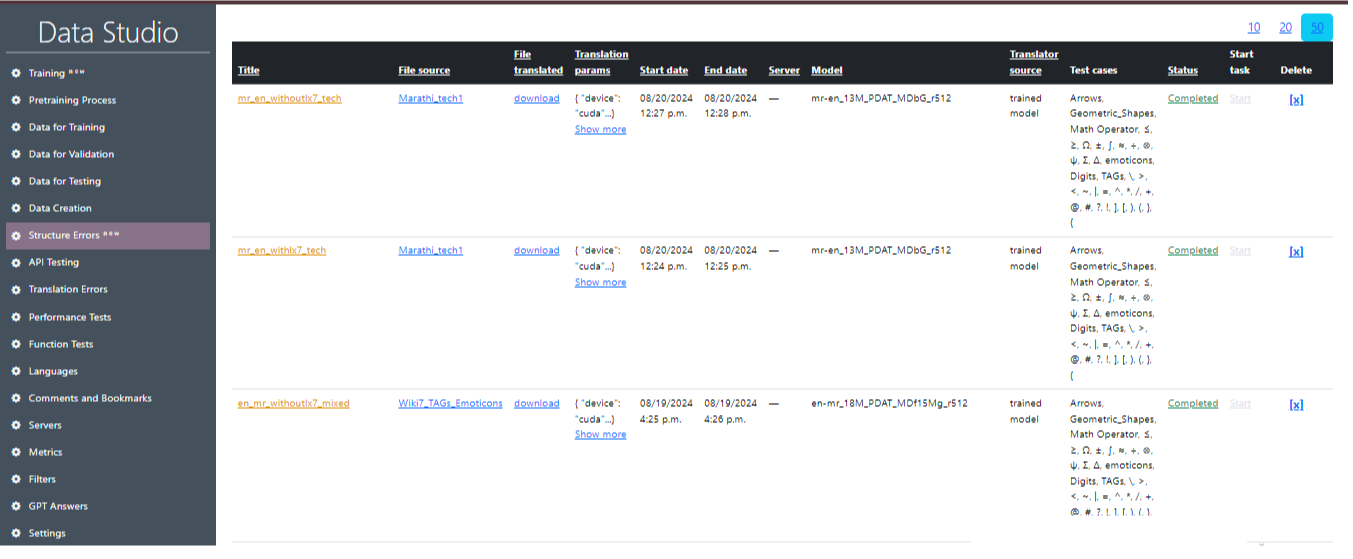
- Τίτλος : Αυτό εμφανίζει τον τίτλο ή το όνομα της εργασίας μετάφρασης.
- Πηγή αρχείων : Αυτό εμφανίζει την πηγή του αρχείου που χρησιμοποιείται για τη μετάφραση.
- Παράμετροι μετάφρασης: Αυτή η ενότητα παρέχει λεπτομέρειες μετάφρασης, συμπεριλαμβανομένης της χρησιμοποιούμενης συσκευής (GUDA ή CPU), μετάφραση με ή χωρίς LX7, compute_type και beam_size.
- Ημερομηνία έναρξης : Παρουσιάζει πληροφορίες σχετικά με την ημερομηνία και την ώρα που εκτελείται η εργασία.
- Ημερομηνία λήξης : Παρέχει πληροφορίες σχετικά με την ημερομηνία και την ώρα που ολοκληρώθηκε η εργασία.
- διακομιστής : διακομιστής που χρησιμοποιείται.
- Μοντέλο : Μοντέλο που χρησιμοποιείται.
- Πηγή μετάφρασης : Πηγή μετάφρασης.
- περιπτώσεις δοκιμής : περιπτώσεις δοκιμών που χρησιμοποιούνται ή ομάδα περιπτώσεων δοκιμής.
- Κατάσταση : Αυτό το μπλοκ εμφανίζει όλες τις ολοκληρωμένες και συνεχιζόμενες εργασίες.
- Εργασία Έναρξης : Αυτή η στήλη υποδεικνύει την κατάσταση της εργασίας μετάφρασης.
- Διαγραφή : Αφαίρεση της εργασίας.
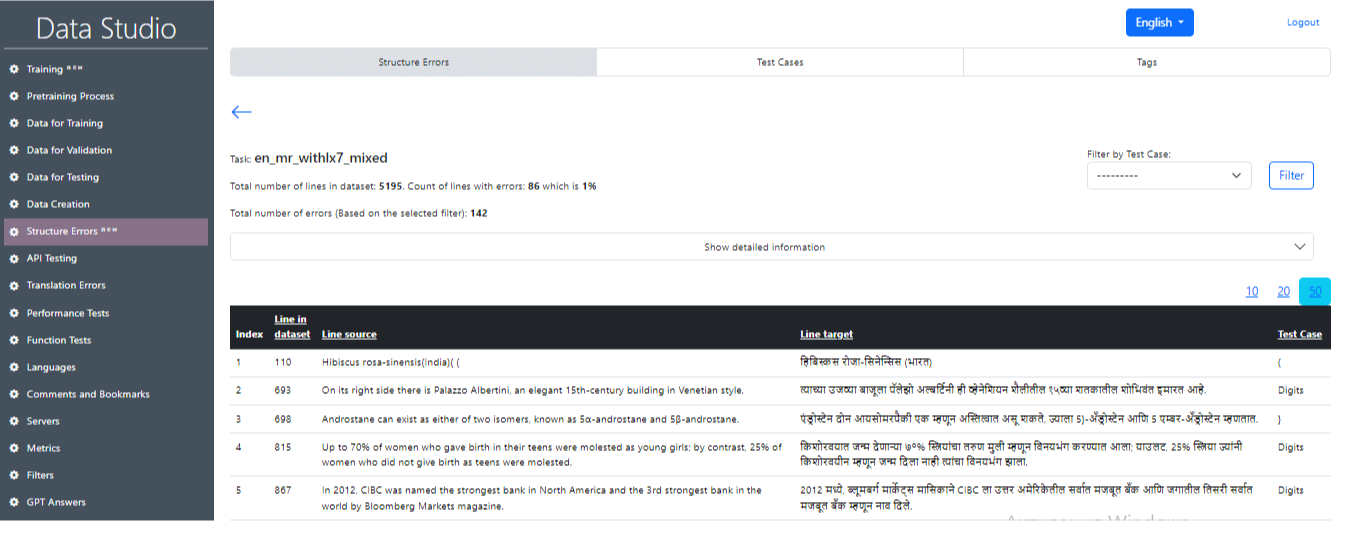
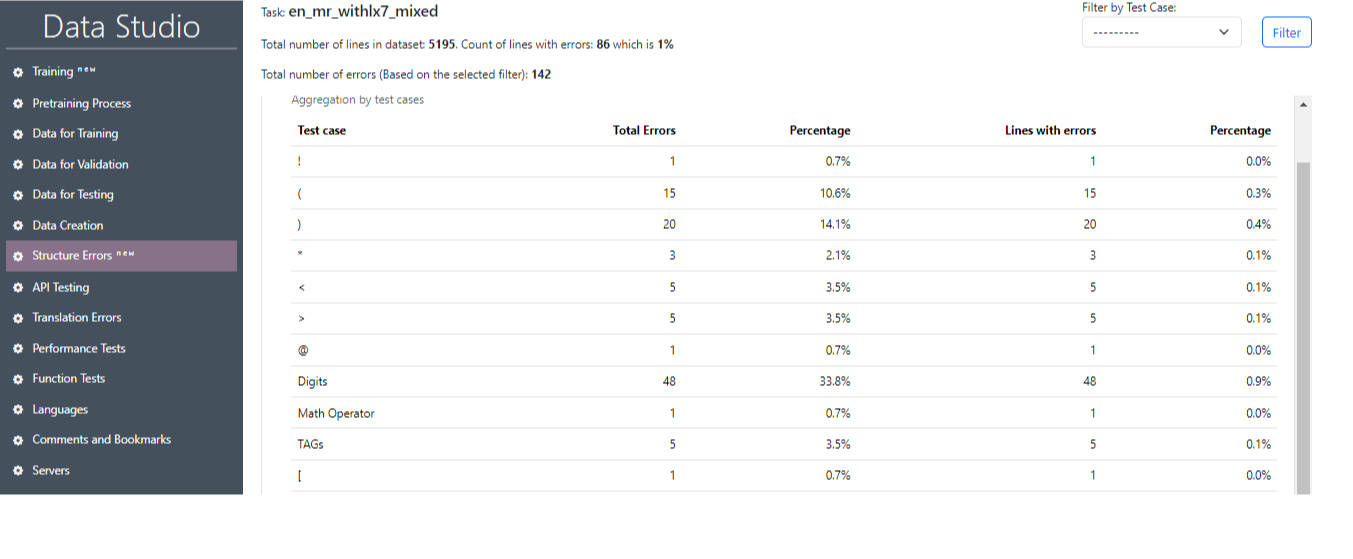
Μετά την επιτυχή ολοκλήρωση της εργασίας, είναι δυνατόν να ληφθούν οι κύριες πληροφορίες σχετικά με τα αποτελέσματα των δοκιμών (Εικόνα 22), όπου θα εμφανιστούν τα κύρια στατιστικά στοιχεία (εικόνα 23), καθώς και οι αριθμοί των προτάσεων που περιέχουν σφάλμα και σχετικό κείμενο. Είναι επίσης δυνατό να επιλέξετε μια μεμονωμένη περίπτωση δοκιμής και προτάσεις με αυτή τη δοκιμαστική περίπτωση κάνοντας κλικ στο κουμπί φίλτρου (Εικόνα 24, Εικόνα 25).
Σύναψη
Σε αυτό το άρθρο, διερευνήσαμε τις δυνατότητες του Lingvanex Data Studio, ένα ισχυρό εργαλείο που έχει σχεδιαστεί για να βελτιώσει την ποιότητα της μηχανικής μετάφρασης. Με την επεξεργασία τεράστιων ποσοτήτων δεδομένων και την εφαρμογή συστηματικών προσεγγίσεων στην κατάρτιση, την επικύρωση και τα μοντέλα δοκιμών, είμαστε σε θέση να προσφέρουμε εξαιρετικά αποτελέσματα μετάφρασης σε ένα ευρύ φάσμα γλωσσών. Συζητήσαμε τα κρίσιμα βήματα που εμπλέκονται στην ανάπτυξη αποτελεσματικών γλωσσικών μοντέλων, συμπεριλαμβανομένης της προετοιμασίας δεδομένων, της κατάρτισης και των αυστηρών μεθοδολογιών δοκιμών. Η ενσωμάτωση της κατάρτισης, της επικύρωσης και των δοκιμών δεδομένων διασφαλίζει ότι τα μοντέλα μας όχι μόνο μαθαίνουν αποτελεσματικά, αλλά και γενικεύονται καλά σε νέα, αόρατα δεδομένα.
Χάρη στη συνεχιζόμενη έρευνα και τα καινοτόμα εργαλεία στη διάθεσή μας, συνεχίζουμε να βελτιώνουμε τις μεταφραστικές μας διαδικασίες, βελτιώνοντας την ακρίβεια και την απόδοση μήνα μετά το μήνα.


