
Στην αξιολόγηση της ποιότητας της μηχανικής μετάφρασης, είναι σημαντικό όχι μόνο να συγκρίνουμε τα αποτελέσματα διαφορετικών συστημάτων, αλλά και να ελέγξουμε αν οι παρατηρούμενες διαφορές είναι στατιστικά σημαντικές. Αυτό μας επιτρέπει να εκτιμήσουμε αν τα αποτελέσματα είναι έγκυρα και μπορούν να γενικευθούν σε άλλα δεδομένα.
Σε αυτό το άρθρο, εξετάζουμε δύο από τις πιο διαδεδομένες μετρικές για την αξιολόγηση της ποιότητας μετάφρασης, τις BLEU και COMET, και αναλύουμε πώς να δοκιμάσουμε τη στατιστική σημαντικότητα των διαφορών μεταξύ δύο συστημάτων μετάφρασης χρησιμοποιώντας αυτές τις μετρικές.

Στατιστική Σημαντικότητα των BLEU και COMET
Η μετρική BLEU (Bilingual Evaluation Understudy) αξιολογεί την ποιότητα της μετάφρασης συγκρίνοντας τα n-grams ενός μεταφρασμένου κειμένου με αυτά μιας αναφοράς (ανθρώπινης) μετάφρασης. Σύμφωνα με τη μελέτη “Yes, We Need Statistical Significance Testing”, για να θεωρηθεί στατιστικά σημαντική η βελτίωση στη BLEU πρέπει η διαφορά να ξεπερνάει το 1.0 BLEU. Για “υψηλή σημαντικότητα” (p-value < 0.001), απαιτείται βελτίωση ≥ 2.0 BLEU.
Η μετρική COMET (Crosslingual Optimised Metric for Evaluation of Translation), η οποία βασίζεται σε μοντέλο μηχανικής μάθησης, μετρά την ποιότητα συγκριτικά με την αναφορά. Η μελέτη δείχνει ότι διαφορές 1 έως 4 πόντων ενδέχεται να μην είναι στατιστικά σημαντικές, ακόμη και διαφορά 4.0 COMET μπορεί να μην είναι.
Αυτό έχει ουσιαστικές συνέπειες για τους δημιουργούς μεταφραστικών συστημάτων: οι απλές συγκρίσεις αριθμητικών τιμών μπορεί να είναι παραπλανητικές. Είναι απαραίτητο να γίνονται στατιστικά τεστ για να ελεγχθεί αν οι διαφορές είναι ουσιαστικές.
Επιλογή Μετρικής για Σύγκριση Συστημάτων
Στο άρθρο “To Ship or Not to Ship: An Extensive Evaluation of Automatic Metrics for Machine Translation”, ερευνητές της Microsoft εξέτασαν ποια μετρική αντιστοιχεί καλύτερα με την αξιολόγηση από επαγγελματίες μεταφραστές.
Οι μεταφραστές μετέφρασαν το κείμενο χειροκίνητα (χωρίς μετα-επεξεργασία) και ένας ανεξάρτητος μεταφραστής επιβεβαίωσε την ποιότητα. Οι προτάσεις μεταφράστηκαν ξεχωριστά αλλά με πρόσβαση στα συμφραζόμενα.
Η COMET εμφάνισε τη μεγαλύτερη συσχέτιση με την ανθρώπινη αξιολόγηση.
Η μελέτη επίσης έδειξε πως η COMET είναι η πιο αξιόπιστη μετρική για τη σύγκριση διαφορετικών συστημάτων μεταξύ τους.
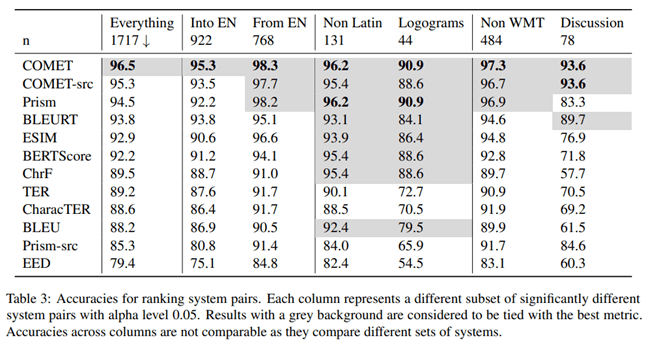
Για να ελέγξουν τη στατιστική σημαντικότητα, οι συγγραφείς χρησιμοποίησαν την προσέγγιση του άρθρου “Statistical Significance Tests for Machine Translation Evaluation”.
Είναι ξεκάθαρο ότι η COMET αποτελεί το πιο αξιόπιστο εργαλείο τόσο για σύγκριση με την ανθρώπινη μετάφραση όσο και για μεταξύ συστημάτων.
Έλεγχος Στατιστικής Σημαντικότητας
Είναι σημαντικό να επιβεβαιωθεί ότι οι διαφορές δεν είναι αποτέλεσμα τύχης. Ο Philipp Koehn προτείνει τη μέθοδο bootstrap στο άρθρο του.
Η μέθοδος bootstrap είναι μια στατιστική διαδικασία επαναληπτικής δειγματοληψίας με επανατοποθέτηση, που υπολογίζει την αβεβαιότητα εκτιμήσεων όπως διακύμανση, μέση τιμή, τυπική απόκλιση, διαστήματα εμπιστοσύνης.

Αλγόριθμος για έλεγχο στατιστικής σημαντικότητας:
1. Δημιουργείται τυχαίο bootstrap δείγμα ίδιου μεγέθους από το αρχικό.
2. Υπολογίζεται η μέση τιμή της μετρικής (π.χ., BLEU ή COMET).
3. Η διαδικασία επαναλαμβάνεται πολλές φορές (δεκάδες, εκατοντάδες).
4. Υπολογίζεται ο συνολικός μέσος.
5. Υπολογίζεται η διαφορά μέσων τιμών μεταξύ συστημάτων.
6. Κατασκευάζεται διάστημα εμπιστοσύνης.
7. Ελέγχεται αν η διαφορά είναι στατιστικά σημαντική.
Πρακτική Εφαρμογή
Η προσέγγιση αυτή υλοποιείται στη βιβλιοθήκη Unbabel/COMET. Εκτός από την αξιολόγηση, επιτρέπει και τον έλεγχο σημαντικότητας.
Η εφαρμογή μεθόδων όπως το bootstrap είναι κρίσιμη για την αντικειμενική αξιολόγηση συστημάτων μηχανικής μετάφρασης, διευκολύνοντας την επιλογή μοντέλων και τη σαφή παρουσίαση των αποτελεσμάτων στους χρήστες.
Συμπέρασμα
Κατά τη σύγκριση συστημάτων μηχανικής μετάφρασης, είναι ουσιώδες να χρησιμοποιούνται στατιστικές μέθοδοι ώστε να εντοπίζονται πραγματικές βελτιώσεις και να αποφεύγονται τυχαίοι παράγοντες. Αυτό επιτρέπει πιο αντικειμενική αξιολόγηση της προόδου της τεχνολογίας.



