In diesem Artikel stellen wir die Herausforderungen vor, die mit der Entwicklung einer mobilen Version eines neuronalen maschinellen Übersetzungssystems verbunden sind. Ziel ist es, die Übersetzungsqualität zu maximieren und gleichzeitig die Modellgröße zu reduzieren. Wir erklären den gesamten Prozess der Implementierung der Übersetzungs-Engine am Beispiel des englisch-spanischen Sprachpaars. Wir beschreiben die aufgetretenen Herausforderungen und die implementierten Lösungen.
Die wichtigsten in dieser Arbeit verwendeten Methoden umfassen:
- Datenauswahl mit hilfe seltener N-Gramm-Wiederherstellung;
- Anfügen eines speziellen Wortes an das Ende jedes Satzes;
- Erstellen zusätzlicher Beispiele ohne abschließende Interpunktion.

Die letzten beiden Methoden wurden entwickelt, um ein Übersetzungsmodell zu erstellen, das Sätze ohne abschließenden Punkt oder andere Satzzeichen generiert. Die seltene N-Gramm-Wiederherstellung wurde auch erstmals verwendet, um ein neues Korpus zu erstellen, anstatt nur einen Datensatz in einer Domäne zu erweitern.
Schließlich gelangen wir zu einem kleinen Modell, das eine ausreichend gute Qualität für den täglichen Gebrauch bietet.
Der Lingvanex-Ansatz
Lingvanex ist eine Marke für Sprachprodukte von Nordicwise LLC, die sich auf Offline-Übersetzungs- und Wörterbuchanwendungen für mobile und Desktop-Plattformen spezialisiert hat. In Zusammenarbeit mit Sciling, einem auf End-to-End-Lösungen für maschinelles Lernen spezialisierten Unternehmen, wurde ein kleines Englisch-Spanisch-Übersetzungsmodell für den mobilen Einsatz entwickelt. Das Hauptziel bestand darin, genaue Übersetzungen in alltäglichen Szenarien bereitzustellen, insbesondere für Reisende, die aufgrund von Roaming-Kosten, fehlenden lokalen SIM-Karten oder schlechter Konnektivität in bestimmten Gebieten möglicherweise keinen Internetzugang haben. Um dies zu erreichen, konzentrierte sich das Projekt darauf, die Modellgröße mithilfe von Datenauswahltechniken zu minimieren und eine endgültige Größe von 150 MB oder weniger anzustreben.
Es wurden Experimente durchgeführt, um Schlüsselfaktoren zu identifizieren, die die Modellgröße beeinflussen, darunter Vokabulargröße, Worteinbettung und neuronale Netzwerkarchitektur. Während des Implementierungsprozesses traten mehrere Übersetzungsprobleme auf, die die Entwicklung geeigneter Lösungen erforderten. Die Qualität des endgültigen Modells wurde im Vergleich zu führenden mobilen Übersetzern von Google und Microsoft bewertet, was seine Wirksamkeit für den praktischen Einsatz in Reisesituationen demonstrierte.
Datenbeschreibung
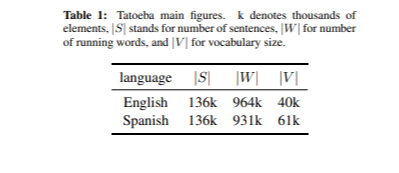
Die zum Trainieren des Übersetzungsmodells verwendeten Daten wurden aus dem OPUS-Korpus bezogen. Insgesamt gab es 76 Millionen parallele Sätze. Wir haben auch das Tatoeba-Korpus für DS verwendet, das im Abschnitt „Datenfilterung“ beschrieben wird. Tatoeba ist eine kostenlose Online-Datenbank mit Beispielsätzen für Sprachlernende. Das Entwicklungsset wurde ebenfalls aus dem Tatoeba-Korpus erstellt, indem 2.000 zufällige Satzpaare ausgewählt wurden. Die wichtigsten Kennzahlen des Tatoeba-Korpus sind in Tabelle 1 aufgeführt. Als Testset haben wir ein kleines Korpus nützlicherer englischer Sätze erstellt, die auf verschiedenen Websites zu finden sind. Wir haben auch einige Unigramm- und Bigram-Sätze hinzugefügt. Insgesamt haben wir 86 Sätze ausgewählt.
Abhängigkeit der Modellgröße
Bei der Lösung des Problems der Modellgrößenreduzierung besteht die größte Herausforderung darin, zu bestimmen, welche Hyperparameter den größten Einfluss auf die Größe haben. Vor der Implementierung des neuronalen maschinellen Übersetzungssystems (NMT) wurden Experimente durchgeführt, bei denen die Modellgröße mit der Gesamtvokabulargröße und der Worteinbettungsgröße verglichen wurde (Abbildung 1). Durch Variation dieser Hyperparameter wurden verschiedene Modelle trainiert.
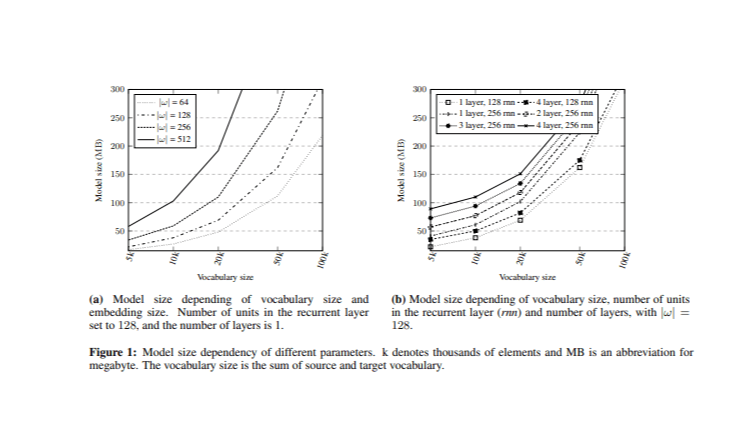
Im ersten Experiment hatte die rekurrierende Schicht 128 Einheiten mit einer Schicht sowohl auf der Encoder- als auch auf der Decoderseite. Die kombinierten Vokabelgrößen (V) (Quelle und Ziel) wurden auf verschiedene Ebenen |V| = {5k, 10k, 20k, 50k und 100k} reduziert, basierend auf den häufigsten Wörtern im Opus-Korpus mit gleichmäßiger Verteilung zwischen den Quell- und Zielvokabularen, wobei die Quell- und Zielvokabelgröße auf |V|/2 eingestellt war. Darüber hinaus wurden verschiedene Einbettungsgrößen |ω| = {64, 128, 256, 512} analysiert.
Anschließend wurde die Auswirkung unterschiedlicher versteckter Einheiten und Anzahl von Schichten untersucht, während die Einbettungsgröße auf |ω| = 128 festgelegt war. Die Ergebnisse zeigten, dass die Anzahl der Schichten einen minimalen Einfluss auf die Modellgröße hatte, insbesondere im Vergleich zur Anzahl der versteckten Einheiten und der Einbettungsgröße. Diese Analyse bietet eine Grundlage für die Auswahl geeigneter Hyperparameterwerte, während die Modellgröße innerhalb des Ziels von 150 MB gehalten wird.
Datenfilterung
Die Datenfilterung bestand aus zwei Hauptschritten. Zunächst wurden Sätze mit mehr als 20 Wörtern entfernt, da mobile Übersetzer darauf ausgelegt sind, kurze Sätze zu übersetzen. Zweitens wurde die Datenauswahl mithilfe der Infrequent n-gram Recovery durchgeführt. Diese Technik zielt darauf ab, aus den verfügbaren zweisprachigen Datensätze auszuwählen, die die N-Gramm-Abdeckung innerhalb eines kleineren, domänenspezifischen Datensatzes maximieren.
Der Ansatz umfasste das Sortieren des gesamten Datensatzes nach dem Infrequentity-Score jedes Satzes, um die informativsten Sätze zu priorisieren. Lassen Sie χ die Menge der N-Gramme in den zu übersetzenden Sätzen darstellen und w eines dieser N-Gramme bezeichnen. C(w) gibt die Anzahl der w im Trainingssatz der Ausgangssprache an, während t ein Schwellenwert ist, um zu bestimmen, wann ein N-Gramm als ungewöhnlich gilt. N(w) bezieht sich auf die Anzahl der w im Ausgangssatz f. Der Infrequentity-Score von f> ist (1):
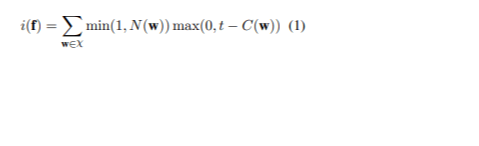
Für die 60 Millionen Sätze aus dem Opus-Korpus wurden bis zu 5 N-Gramme aus dem Tatoeba-Korpus extrahiert, wobei für jedes N-Gramm maximal 30 Vorkommen angestrebt wurden. Um die Laufzeit zu verwalten, wurde das Korpus in sechs Partitionen aufgeteilt, wobei die Auswahl einzeln durchgeführt wurde, bevor die Ergebnisse zusammengeführt wurden. Ein abschließender Auswahlprozess wurde durchgeführt, um sicherzustellen, dass kein N-Gramm den Vorkommensschwellenwert überschritt. Letztendlich führte dieser Prozess zu einem Datensatz von 740.000 Sätzen mit einem Wortschatz von 19.400 Wörtern in der Ausgangssprache und 22.900 Wörtern in der Zielsprache, was einen kombinierten Wortschatz von 42.400 Wörtern ergab. Die Stichprobe basierte auf dem tokenisierten und stringifizierten Korpus.
Versuchsaufbau
Das System wurde mithilfe des Deep-Learning-Frameworks OpenNMT trainiert, das sich auf die Entwicklung von Sequenz-in-Sequenz-Modellen für eine Vielzahl von Aufgaben konzentriert, darunter maschinelle Übersetzung und Zusammenfassung. Byte Pair Encoding (BPE) wurde auf einen ausgewählten Trainingsdatensatz angewendet und dann für die Trainings-, Entwicklungs- und Testdaten verwendet. Es wurde ein rekurrentes neuronales Netzwerk mit langem Kurzzeitgedächtnis (LSTM) verwendet, einschließlich einer globalen Aufmerksamkeitsebene zur Verbesserung der Übersetzung durch Fokussierung auf bestimmte Teile des Quellsatzes. Der Eingabe-Feed wurde auch verwendet, um Aufmerksamkeitsvektoren für nachfolgende Zeitschritte bereitzustellen, obwohl dies nur bei vier oder mehr Ebenen einen spürbaren Effekt hatte.
Das Training umfasste 50 Epochen unter Verwendung des Adam-Optimierers mit einer Lernrate von 0,0002. Das beste Modell wurde basierend auf dem höchsten BLEU-Score des Entwicklungssatzes ausgewählt und zum Übersetzen des Testsatzes verwendet. Aufgrund der geringen Größe des Testsatzes wurde eine menschliche Bewertung durchgeführt, um die Qualität der Übersetzungen zu beurteilen.
Ergebnis und Analyse
Wir haben verschiedene Arten neuronaler Netzwerke basierend auf den Ideen im Abschnitt „Abhängigkeit der Modellgröße“ trainiert. In jedem Experiment haben wir die Hyperparameter angepasst, während wir die Gesamtvokabulargröße bei 42,4.000 Wörtern belassen haben. Tabelle 2 zeigt die Hyperparameterwerte für jedes Experiment sowie die BLEU-Werte und Modellgrößen.
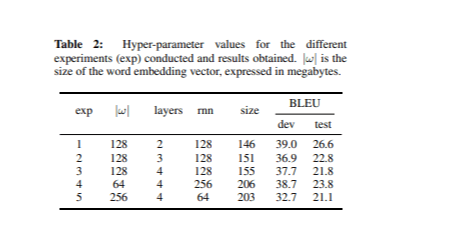
Das leistungsstärkste Modell, gemessen am BLEU-Score des Entwicklungssatzes, hatte 2 Schichten und 128 Einheiten in der rekurrierenden Schicht mit einer Einbettungsgröße von 128. Bemerkenswerterweise war dieses Modell auch das kleinste unter den in Tabelle 2 aufgeführten.
Gefundene Probleme und ihre Lösungen
Die Analyse der Übersetzungen aus dem Testsatz ergab drei Hauptprobleme, für die jeweils spezifische Lösungen vorgeschlagen wurden.
1. Problem mit wiederholten Wörtern
Das beste Modell lieferte korrekte Übersetzungen für Sätze mit mehr als sieben Wörtern, generierte jedoch häufig wiederholte Wörter in sehr kurzen Sätzen (z. B. „ perro perro perro “). Dieses Problem war auf den Unterschied in der Satzlänge zwischen den Trainings- und Testdaten zurückzuführen, da der Trainingssatz nur wenige kurze Sätze enthielt (Abbildung 2).
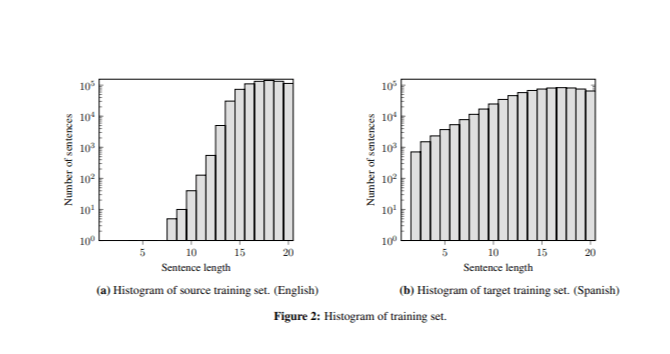
Um diesen Effekt zu mildern, haben wir die Bewertungsfunktion „Seltene N-Gramm-Wiederherstellung“ durch Hinzufügen eines Normalisierungsschritts angepasst (2).
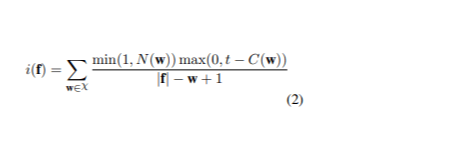
Nachdem wir zur Datenauswahl die Unfrequenzbewertung angewendet hatten, wählten wir einen Datensatz mit 667.000 Sätzen aus. In Tabelle 3 zeigen wir die durchschnittliche Satzlänge in der Ausgangs- und Zielsprache vor und nach der Anwendung der Satzlängennormalisierung.
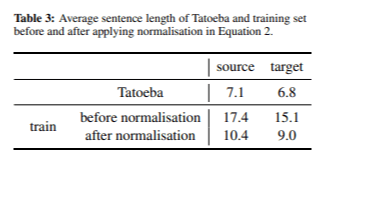
Durch den Normalisierungsprozess konnten wir sowohl in der Ausgangs- als auch in der Zielsprache deutlich kürzere Sätze erzielen. Das Modell erreichte während der Entwicklung einen BLEU-Score von 36,3 und während des Tests von 22,8 bei einer Gesamtmodellgröße von 121 MB. Obwohl diese Werte etwas niedriger sind als in früheren Experimenten, glauben wir, dass BLEU möglicherweise nicht immer der beste Indikator für die Übersetzungsqualität ist. Die manuelle Analyse bestätigte, dass das Problem der Wortwiederholungen effektiv gelöst wurde.
2. Erwartung von Satzzeichen
Das Modell lieferte falsche Übersetzungen für sehr kurze Sätze (z. B. die Übersetzung von „dog“ als „amor“), sofern kein Satzzeichen hinzugefügt wurde (z. B. „dog“). Dies lag an der Erwartung des Modells von Satzzeichen am Ende von Sätzen; 94 % der Trainingssätze endeten mit einem Satzzeichen. Zur Behebung dieses Problems wurden zwei Lösungen vorgeschlagen:
- Spezielle Wörter: Wir fügen am Ende jedes Satzes ein spezielles Token @@ hinzu. Dieser Ansatz trainiert das Modell, zu erkennen, dass jeder Satz mit @@ endet, während das vorletzte Wort ein Satzzeichen sein kann oder nicht. Diese Technik wurde als Vor- und Nachbearbeitungsschritt implementiert, daher wird sie als spezielle Wortendung bezeichnet. Das Modell, das diese Technik verwendet, erreichte nach 21 Epochen bei einer Größe von 121 MB einen BLEU-Score von 36,4 in der Entwicklung und 26,3 beim Testen.
- Dualer Korpus: Wir haben den Trainingskorpus erweitert, indem wir alle vorhandenen Sätze, die mit Satzzeichen endeten, kombiniert und diese Zeichen entfernt haben. Dadurch konnte das Modell lernen, dass Sätze mit oder ohne Satzzeichen enden können. In diesem Fall erhöhte sich die Modellgröße auf 156 MB und erreichte einen BLEU-Score von 37,3 in der Entwicklung und 25,1 beim Testen.
Beide Methoden lösten das Problem der Interpunktionserwartung effektiv;
Aufgrund der größeren Größe und des niedrigeren BLEU-Scores der dualen Korpusstrategie entschieden wir uns jedoch für eine spezielle Wortendungstechnik.
3. Fehlende Segmente
Es wurde festgestellt, dass bei der Übersetzung von Segmenten mit mehreren kurzen Sätzen nur der erste davon übersetzt wurde (z. B. wurde aus „Danke. Das war wirklich hilfreich.“ „Gracias.“).
Um dies zu beheben, wurde ein Vorverarbeitungsschritt eingeführt, um Segmente basierend auf Satzzeichen zu trennen. Diese Anpassung erhöhte die Anzahl der Segmente im Testsatz von 86 auf 118. Nach dieser Änderung verbesserten sich die Übersetzungen erheblich und erreichten einen BLEU-Entwicklungswert von 36,4 und einen Testwert von 33,7, den höchsten bisher verzeichneten Wert.
Endgültige Bewertung
Tabelle 4 fasst die BLEU-Werte zusammen, die nach Anwendung der einzelnen im Abschnitt „Gefundene Probleme und ihre Lösungen“ beschriebenen Lösungen erzielt wurden. Nach Anwendung des normalisierten Unfrequenz-Werts, der speziellen Wortendung und der Vorverarbeitung der konstruierten Sätze haben wir die Qualität des Testsatzes um etwa 7 BLEU-Punkte verbessert.
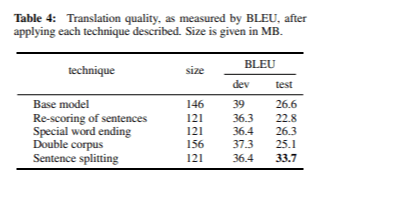
Bei der abschließenden Bewertung unseres Übersetzungssystems verglichen wir dessen Qualität mit den mobilen Übersetzern von Google und Microsoft. Tabelle 5 zeigt die BLEU-Werte und Modellgrößen für jeden Übersetzer im Testset.
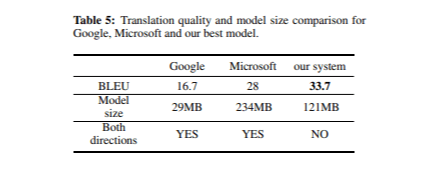
Insgesamt lieferten alle drei Systeme qualitativ hochwertige Übersetzungen, obwohl einige geringfügige Unterschiede festgestellt wurden. Unser Modell schnitt besonders gut bei Satzzeichen und Großschreibung ab, während Google Translate Satzzeichen häufig falsch platzierte und Großschreibung selten verwendete. Dies könnte erklären, warum Google Translate im Vergleich zu den beiden anderen Systemen trotz seiner geringeren Modellgröße einen niedrigeren BLEU-Score erhielt. Darüber hinaus sind die Modelle von Google und Microsoft bidirektional, was bedeutet, dass unsere Modellgröße für einen fairen Vergleich verdoppelt werden muss (2 × 121 MB).
Fazit
Dieses Dokument beschreibt die Entwicklung einer kompakten mobilen neuronalen maschinellen Übersetzung für Englisch-Spanisch. Wir verwendeten eine Datenauswahlmethode, um die Fitness der Trainingsdaten zu verbessern, und nahmen Anpassungen vor, um die Übersetzungsqualität zu verbessern. Es wurden Lösungen vorgeschlagen, um die Probleme wiederholter Wörter und fehlender Übersetzungen in Segmenten zu beheben. Unser Modell übertraf die mobilen Übersetzer von Google und Microsoft bei den BLEU-Scores, insbesondere bei der Verarbeitung von Satzzeichen und Großschreibung. Mit 121 MB ist unser Modell kleiner als ursprünglich geschätzt, bietet aber dennoch eine gute Übersetzungsqualität für reisebezogene Kontexte. Die Übersetzungen sind flüssig und verständlich und für die Offline-Nutzung geeignet. Derzeitige Bemühungen konzentrieren sich auf die weitere Verbesserung der Qualität und die Reduzierung der Modellgröße, einschließlich Methoden wie Gewichtsreduzierung.