Bei der Qualitätsbewertung maschineller Übersetzungen ist es wichtig, nicht nur die Ergebnisse verschiedener Übersetzungssysteme zu vergleichen, sondern auch zu prüfen, ob die festgestellten Unterschiede statistisch signifikant sind. Dadurch lässt sich beurteilen, ob die erzielten Ergebnisse valide sind und auf andere Daten übertragen werden können.
In diesem Artikel untersuchen wir zwei der gängigsten Metriken zur Beurteilung der Übersetzungsqualität, BLEU und COMET, und analysieren, wie die statistische Signifikanz von Unterschieden zwischen den beiden Übersetzungssystemen anhand dieser Metriken getestet werden kann.

Statistische Signifikanz von BLEU und COMET
Die BLEU-Metrik (Bilingual Evaluation Understudy) bewertet die Übersetzungsqualität, indem sie die N-Gramme in einem übersetzten Text mit den N-Grammen in einer Referenzübersetzung (menschliche Übersetzung) vergleicht. Laut der Studie „Ja, wir brauchen Tests zur statistischen Signifikanz“ muss die Differenz größer als 1,0 BLEU-Score sein, um eine statistisch signifikante Verbesserung der BLEU-Kennzahl gegenüber früheren Arbeiten behaupten zu können. Wenn wir eine „hochsignifikante“ Verbesserung als „p-Wert < 0,001“ betrachten, muss die Verbesserung 2,0 BLEU-Punkte oder mehr betragen.
Eine weitere weit verbreitete Metrik, COMET (Crosslingual Optimised Metric for Evaluation of Translation), verwendet ein maschinelles Lernmodell, um die Qualität einer Übersetzung im Vergleich zu einer Referenzübersetzung zu bewerten. Die Studie zeigte, dass ein Unterschied von 1 bis 4 Punkten statistisch unbedeutend sein kann, d. h. innerhalb der Fehlergrenze. Sogar der Unterschied zwischen 4,0 COMET-Werten kann unbedeutend sein.
Diese Ergebnisse haben wichtige praktische Auswirkungen für Entwickler maschineller Übersetzungssysteme. Ein bloßer Vergleich numerischer Kennzahlen kann zu irreführenden Schlussfolgerungen hinsichtlich der Verbesserung der Übersetzungsqualität führen. Stattdessen sollten statistische Tests durchgeführt werden, um festzustellen, ob die beobachteten Unterschiede wirklich von Bedeutung sind.
Auswählen einer Metrik zum Vergleich von Übersetzungssystemen
Im Artikel „To Ship or Not to Ship: An Extensive Evaluation of Automatic Metrics for Machine Translation“ untersuchten Forscher von Microsoft, welche Metrik zur Beurteilung der Qualität maschineller Übersetzungen besser mit der Bewertung professioneller Übersetzer korreliert. Zu diesem Zweck führten sie das folgende Experiment durch.
Professionelle Übersetzer mit Kenntnissen der Zielsprache übersetzen den Text zunächst manuell ohne Nachbearbeitung und anschließend bestätigt ein unabhängiger Übersetzer die Qualität dieser Übersetzungen. Die Übersetzer erkannten den Kontext in anderen Sätzen, übersetzten die Sätze jedoch einzeln.
Den Ergebnissen dieser Studie zufolge wies die COMET-Metrik, welche die Übersetzung auf Basis einer Referenzvariante bewertet, im Vergleich mit Bewertungen durch professionelle Übersetzer die höchste Korrelation und Genauigkeit auf.
Die Autoren des Artikels untersuchten außerdem, welche Metrik beim Vergleich der Qualität verschiedener maschineller Übersetzungssysteme die höchste Genauigkeit liefert. Ihren Erkenntnissen zufolge ist COMET das zuverlässigste Maß, um Übersetzungssysteme miteinander zu vergleichen.
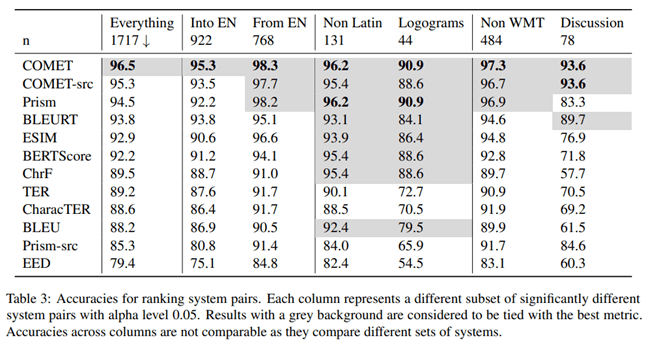
Um die statistische Signifikanz der Unterschiede zwischen den Ergebnissen zu testen, verwendeten die Autoren den im Artikel “Statistical Significance Tests for Machine Translation Evaluation” beschriebenen Ansatz.
Es ist klar, dass die COMET-Metrik das zuverlässigste Instrument zur Bewertung der Qualität maschineller Übersetzungen ist, sowohl im Vergleich mit menschlichen Übersetzungen als auch beim Vergleich verschiedener Übersetzungssysteme untereinander. Die Schlussfolgerung ist wichtig für Entwickler maschineller Übersetzungssysteme, die die Leistung ihrer Modelle objektiv bewerten und vergleichen müssen.
Statistischer Signifikanztest
Dabei muss darauf geachtet werden, dass die beobachteten Unterschiede zwischen den Übersetzungssystemen statistisch signifikant sind, also nicht mit hoher Wahrscheinlichkeit auf Zufallsfaktoren zurückzuführen sind. Zu diesem Zweck schlägt Philipp Koehn in seinem Artikel „Tests auf statistische Signifikanz zur Bewertung maschineller Übersetzungen“ die Verwendung der Bootstrap-Methode vor.
Bei der Bootstrap-Resampling-Methode handelt es sich um ein statistisches Verfahren auf Grundlage der Stichprobenziehung mit Zurücklegen, um die Präzision (Bias) von Stichprobenschätzungen hinsichtlich Varianz, Mittelwert, Standardabweichung, Konfidenzintervallen und anderen Strukturmerkmalen einer Stichprobe zu ermitteln. Schematisch lässt sich das Bootstrap-Verfahren wie folgt darstellen:

Ein Algorithmus zum Testen der statistischen Signifikanz:
1. Aus der Originalstichprobe wird zufällig eine Bootstrap-Stichprobe gleicher Größe generiert, wobei einige Beobachtungen mehrmals und andere möglicherweise überhaupt nicht erfasst werden.
2. Für jede Bootstrap-Stichprobe wird der Mittelwert einer Metrik (z. B. BLEU oder COMET) berechnet.
3. Das Verfahren der Bootstrap-Stichprobennahme und Durchschnittsberechnung wird viele Male (Zehntel-, Hunderter- oder Tausendfach) wiederholt.
4. Aus den erhaltenen Durchschnittswerten wird der Gesamtdurchschnitt berechnet, der als Durchschnitt der gesamten Stichprobe gilt.
5. Die Differenz der Mittelwerte der verglichenen Systeme wird berechnet.
6. Für die Differenz zwischen den Durchschnittswerten wird ein Konfidenzintervall erstellt.
7. Anhand der statistischen Kriterien wird beurteilt, ob das Konfidenzintervall für die Differenz der Durchschnittswerte statistisch signifikant ist.
Praktische Anwendung
Der oben beschriebene Ansatz ist für die COMET-Metrik in der Unbabel/COMET-Bibliothek implementiert, die neben der Berechnung der COMET-Metrik auch die Möglichkeit bietet, die statistische Signifikanz der erzielten Ergebnisse zu testen. Dieser Ansatz ist ein wichtiger Schritt hin zu einer zuverlässigeren und valideren Bewertung maschineller Übersetzungssysteme. Ein einfacher Vergleich von Messwerten kann oft irreführend sein, insbesondere wenn die Unterschiede gering sind.
Die Anwendung statistischer Analysemethoden wie Bootstrap ist ein wichtiger Schritt, um die Leistung maschineller Übersetzungssysteme objektiv zu bewerten und zu vergleichen. Dadurch können Entwickler fundiertere Entscheidungen bei der Auswahl optimaler Ansätze und Modelle treffen und den Benutzern eine zuverlässigere Präsentation der Ergebnisse bieten.
Abschluss
Daher ist es beim Vergleich maschineller Übersetzungssysteme wichtig, statistische Methoden zu verwenden, um sinnvolle Verbesserungen von Zufallsfaktoren zu unterscheiden. Dadurch ist eine objektivere Bewertung des Fortschritts der maschinellen Übersetzungstechnologie möglich.