Products & Services
Discover our advanced natural language processing solutions for over 100 languages, compatible with Linux, Windows, server-based, and cloud platforms.
Machine Translation
-

On-premise Machine Translation
Deploys securely as a Docker container on Linux or Windows, with browser UI and REST API integration.
-

Translation API
Integrate translation capabilities in just 5 minutes using a simple and efficient REST API.
-
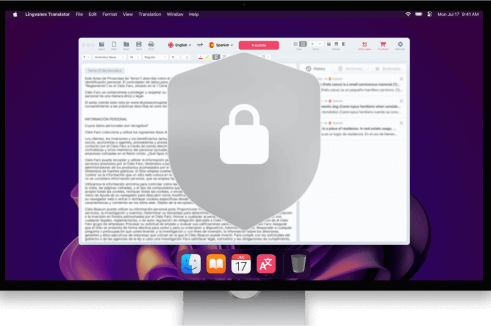
Translator for PC
Desktop app for Windows and macOS to translate text, documents, and websites, with offline functionality.
-
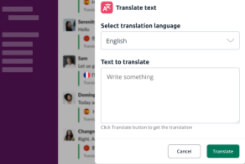
Translator for Slack
Translate messages in channels or direct messages with support for 109 languages directly within Slack.
Speech Recognition

On-premise Speech Recognition
This type of technology is installed and runs locally on the company's own servers, running either Linux or Windows. It enables organizations to process and analyze speech in 91 languages, including all punctuation marks, without requiring an internet connection.

Subtitle Generator
The tool supports a wide range of popular formats to ensure seamless compatibility across platforms. Supported formats include audio files (MP3, WAV, AAC, FLAC), video files (MP4, AVI, MKV, MOV), and subtitles (SRT, VTT, ASS, SSA, SUB).
Case Studies









Contact Us

Completed
Your request has been sent successfully
