
Key Takeaways
- OpenAI Whisper and Lingvanex are designed for different use cases. Whisper is an open-source ASR model for building custom speech recognition solutions, while Lingvanex is a complete enterprise speech recognition platform.
- Both platforms support multilingual and offline speech recognition, but they differ in deployment options, integration capabilities, and enterprise features such as real-time streaming and speaker diarization.
- Production deployments require more than transcription accuracy. Organizations should also evaluate scalability, deployment flexibility, security, infrastructure requirements, and long-term maintenance.
- Whisper offers maximum flexibility for developers, whereas Lingvanex reduces engineering effort by providing built-in APIs, deployment tools, and commercial support.
- The best choice depends on your business requirements. Organizations building custom AI applications may prefer Whisper, while enterprises processing business-critical or regulated data often benefit from a production-ready platform like Lingvanex.

OpenAI Whisper has become one of the most popular open-source speech recognition models thanks to its strong multilingual accuracy, broad language support, and free availability. It is widely used for transcription, subtitle generation, voice assistants, meeting transcription, and AI-powered applications, making it the default starting point for many developers building speech-to-text solutions.
However, selecting a speech recognition platform for production environments involves much more than choosing an accurate model. Organizations must also consider deployment options, real-time streaming, scalability, infrastructure requirements, data privacy, speaker diarization, commercial support, and the ability to process confidential information. As a result, many businesses evaluate enterprise platforms that extend beyond the capabilities of a standalone open-source model.
This article provides a detailed comparison of OpenAI Whisper and Lingvanex across the areas that matter most for real-world deployments, including recognition accuracy, performance, streaming, deployment, security, enterprise features, and scalability. Whether you are building a new speech recognition application or looking for a production-ready Whisper alternative, this guide will help you determine which platform best fits your technical and business requirements.
What is OpenAI Whisper
OpenAI Whisper is an open-source automatic speech recognition (ASR) model developed by OpenAI and released in 2022. It was trained on a large multilingual dataset containing hundreds of thousands of hours of audio collected from diverse sources, enabling it to recognize speech across many languages and acoustic conditions. Since its release, Whisper has become one of the most widely adopted speech-to-text models in both research and commercial projects.
Unlike many traditional speech recognition systems, Whisper supports multilingual transcription, speech translation, and automatic language identification within a single model. Because it is freely available under an open-source license, developers can deploy it on their own infrastructure and integrate it into custom applications without relying on proprietary cloud services.
Although Whisper delivers impressive recognition quality, it is fundamentally a machine learning model rather than a complete speech recognition platform. Organizations building production systems often need to combine Whisper with additional components for streaming, deployment, monitoring, speaker recognition, and enterprise management.
Key Features
OpenAI Whisper provides a broad set of capabilities that make it suitable for many speech recognition tasks:
- Automatic speech recognition (ASR) for multiple languages;
- Speech-to-text transcription for recorded audio;
- Speech translation into English;
- Automatic language detection;
- Support for multilingual audio;
- Open-source model with self-hosting support;
- GPU and CPU inference;
- Integration into custom applications through open-source libraries.
These features have made Whisper a popular choice for developers building transcription services, subtitle generation tools, AI assistants, meeting transcription software, and research projects.
Strengths
One of Whisper's biggest advantages is its combination of strong recognition accuracy and open-source availability. Developers can download the model, run it locally, and customize the surrounding infrastructure to fit their own workflows without vendor lock-in.
Additional strengths include:
- High transcription accuracy across many languages;
- Free and open-source licensing;
- Large developer and research community;
- Self-hosted deployment options;
- Continuous improvements through community-driven projects such as faster-whisper and whisper.cpp;
- Flexibility for building custom speech recognition pipelines.
These characteristics make Whisper an excellent choice for prototyping, academic research, internal tools, and organizations with experienced machine learning teams capable of managing their own infrastructure.
Limitations
While Whisper is a powerful speech recognition model, it does not provide many of the capabilities required for enterprise production environments out of the box. Deploying Whisper at scale typically requires additional engineering effort and supporting infrastructure.
Some of its most common limitations include:
- No native real-time streaming support;
- No built-in speaker diarization;
- GPU resources are recommended for high-performance inference;
- Requires additional infrastructure for scalable production deployment;
- Limited enterprise support and commercial SLAs;
- May produce hallucinated text when processing silent or low-quality audio;
- Additional components are often needed for monitoring, security, and workflow integration.
For these reasons, many organizations use Whisper as the core recognition engine during research and development, while evaluating commercial speech recognition platforms that provide deployment, scalability, security, and enterprise features as part of a complete solution.
What is On-premise Lingvanex Speech Recognition
On-premise Lingvanex Speech Recognition is an enterprise speech-to-text platform designed for organizations that require secure, scalable, and production-ready speech recognition. Unlike standalone ASR models, Lingvanex provides a complete solution that combines speech recognition technology with deployment tools, APIs, enterprise management capabilities, and flexible infrastructure options. The platform supports both cloud and on-premise deployments, allowing businesses to process audio while maintaining full control over their data.
The platform is built for real-world business environments where reliability, security, and ease of integration are as important as transcription accuracy. It can be integrated into existing applications through APIs and SDKs and supports large-scale processing of audio from meetings, customer calls, media content, voice assistants, and business communications.
Key Features
Lingvanex Speech Recognition includes a comprehensive set of features designed for enterprise workloads:
- Automatic speech recognition for more than 90 languages;
- Real-time and batch speech transcription;
- Speaker diarization for multi-speaker conversations;
- Automatic punctuation and text formatting;
- Noise-resistant speech recognition;
- Support for low-quality audio recordings;
- REST API and SDK integration;
- Cloud and on-premise deployment;
- Docker-based installation;
- Scalable processing for high-volume workloads.
These capabilities enable organizations to deploy speech recognition quickly without building and maintaining a complex ASR infrastructure from scratch.
Enterprise Capabilities
Lingvanex is designed to meet the operational and security requirements of enterprise organizations. Companies can deploy the platform entirely within their own infrastructure, ensuring that sensitive voice data never leaves their network. This makes it suitable for industries with strict privacy, compliance, or regulatory requirements.
Enterprise capabilities include:
- Secure on-premise deployment;
- Offline speech recognition without internet connectivity;
- Private cloud deployment;
- Processing of confidential business data;
- Enterprise API integration;
- High-volume and multi-user processing;
- Custom deployment and infrastructure configuration;
- Commercial support and regular software updates.
These features make Lingvanex a practical choice for organizations that require predictable performance, data sovereignty, and long-term platform support.
Typical Use Cases
Lingvanex On-premise Speech Recognition is used across a wide range of industries and business scenarios where secure and accurate speech processing is essential.
Common use cases include:
- Call center transcription and analytics;
- Meeting and conference transcription;
- Healthcare documentation;
- Legal interview and courtroom transcription;
- Government and public sector deployments;
- Financial services and compliance recording;
- Media captioning and subtitle generation;
- Customer support automation;
- Voice-enabled enterprise applications;
- Multilingual business communication.
For organizations moving from experimental ASR projects to production deployments, Lingvanex provides a complete enterprise speech recognition platform that combines recognition technology with the infrastructure, security, and management capabilities required for large-scale business use.
Whisper vs. Lingvanex Comparison
OpenAI Whisper and Lingvanex both provide high-quality speech recognition, but they are designed for different purposes. Whisper is an open-source speech recognition model that gives developers the flexibility to build their own ASR pipelines. Lingvanex, on the other hand, is a complete enterprise speech recognition platform that combines speech recognition with deployment tools, APIs, security features, and commercial support.
The comparison below highlights the key differences between the two solutions across deployment, functionality, scalability, and enterprise capabilities.
| Feature | OpenAI Whisper | Lingvanex |
|---|---|---|
| Primary Use Case | Designed primarily as an open-source speech recognition model for research, experimentation, and custom ASR applications. | Designed as a commercial speech recognition platform for organizations deploying ASR in production environments. |
| Licensing | Open-source model that can be downloaded and deployed without licensing fees. | Commercial software available under enterprise licensing. |
| Deployment Options | Typically deployed as a self-hosted solution and integrated into custom infrastructure. | Supports cloud, private cloud, and on-premise deployments using a unified platform. |
| Offline Processing | Can operate entirely offline when deployed on local infrastructure. | Supports fully offline deployments for organizations requiring local data processing. |
| Real-Time Streaming | Real-time streaming can be implemented using additional software components and custom pipelines. | Includes native support for real-time speech recognition through the platform APIs. |
| Speaker Diarization | Speaker diarization is typically implemented using third-party tools or additional models. | Includes built-in speaker diarization as part of the platform. |
| Language Support | Supports speech recognition in more than 90 languages. | Supports speech recognition in more than 90 languages. |
| Automatic Language Detection | Provides automatic language identification within the recognition pipeline. | Supports automatic language detection for multilingual speech recognition. |
| API and SDK | Integration is commonly performed through community libraries or custom APIs. | Provides official REST APIs and SDKs for application integration. |
| Batch Processing | Supports batch transcription of recorded audio files. | Supports batch transcription for large-scale processing workflows. |
| Scalability | Scaling depends on the deployment architecture and infrastructure implemented by the organization. | Designed to support multi-user and high-volume enterprise deployments. |
| Vocabulary and Domain Adaptation | Custom terminology typically requires model fine-tuning or additional adaptation techniques. | Supports enterprise customization for domain-specific terminology and deployment scenarios. |
| Audio Quality Handling | Recognition quality may vary depending on audio quality and preprocessing methods. | Includes features designed to improve recognition of noisy and lower-quality audio. |
| Deployment Management | Deployment, monitoring, scaling, and maintenance are managed by the organization. | Provides a complete deployment platform with enterprise management capabilities. |
| Security and Privacy | Security depends on the deployment architecture and operational practices used by the organization. | Supports secure cloud, private cloud, and on-premise deployments for organizations with data privacy requirements. |
| Support | Primarily supported through the open-source community and ecosystem. | Includes commercial support and regular software updates. |
| Typical Users | Developers, researchers, and organizations building custom speech recognition solutions. | Enterprises, government organizations, healthcare providers, financial institutions, and other organizations deploying speech recognition at scale. |
Although both solutions can deliver high-quality speech recognition, they target different audiences. Whisper is an excellent choice for developers who want full control over an open-source model and are prepared to build and maintain their own infrastructure. Lingvanex is designed for organizations that need a production-ready platform with built-in APIs, enterprise deployment options, commercial support, and security features required for processing business-critical and confidential voice data.
The following sections examine these differences in greater detail, comparing performance, deployment, security, scalability, and real-world use cases to help determine which solution is the better fit for your requirements.
Performance Comparison of Whisper and Lingvanex
Speech recognition quality cannot be evaluated by a single metric. A production-ready ASR platform should combine high transcription accuracy with fast processing speed and efficient hardware utilization. In this section, we compare OpenAI Whisper and Lingvanex using three key performance indicators: Word Error Rate (WER), Character Error Rate (CER), and audio processing speed.
All tests were performed using the same audio dataset, hardware configuration, and evaluation methodology. Each platform processed identical recordings across English, German, French, Spanish, Russian, and Italian. Recognition quality was evaluated using Word Error Rate (WER) and Character Error Rate (CER), while processing speed was measured as the time required to transcribe one minute of audio.
Speech Recognition Accuracy (WER/ CER)
The accuracy of automatic speech recognition systems is commonly evaluated using Word Error Rate (WER) and Character Error Rate (CER). WER measures the percentage of incorrectly recognized words, while CER measures transcription errors at the character level. Lower values indicate better recognition performance.
Word Error Rate (WER)
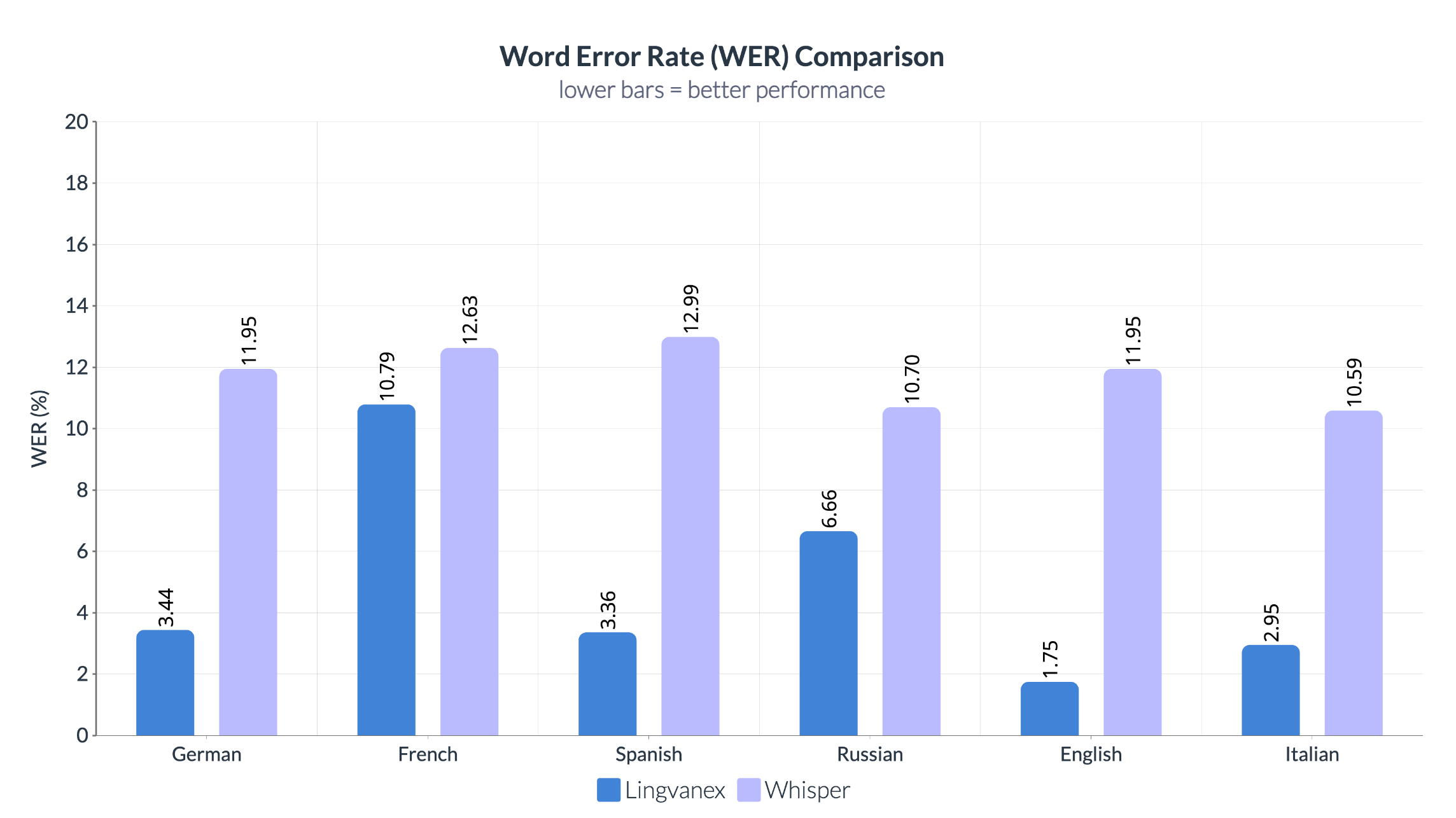
The comparison demonstrates a consistent advantage for Lingvanex across all evaluated languages. Lingvanex achieves significantly lower Word Error Rate than Whisper, particularly for English (1.75% vs. 11.95%), German (3.44% vs. 11.95%), Spanish (3.36% vs. 12.99%), and Italian (2.95% vs. 10.59%). These results indicate that Lingvanex produces substantially fewer transcription errors, making it better suited for production workloads where transcription accuracy directly affects downstream applications.
Character Error Rate (CER)
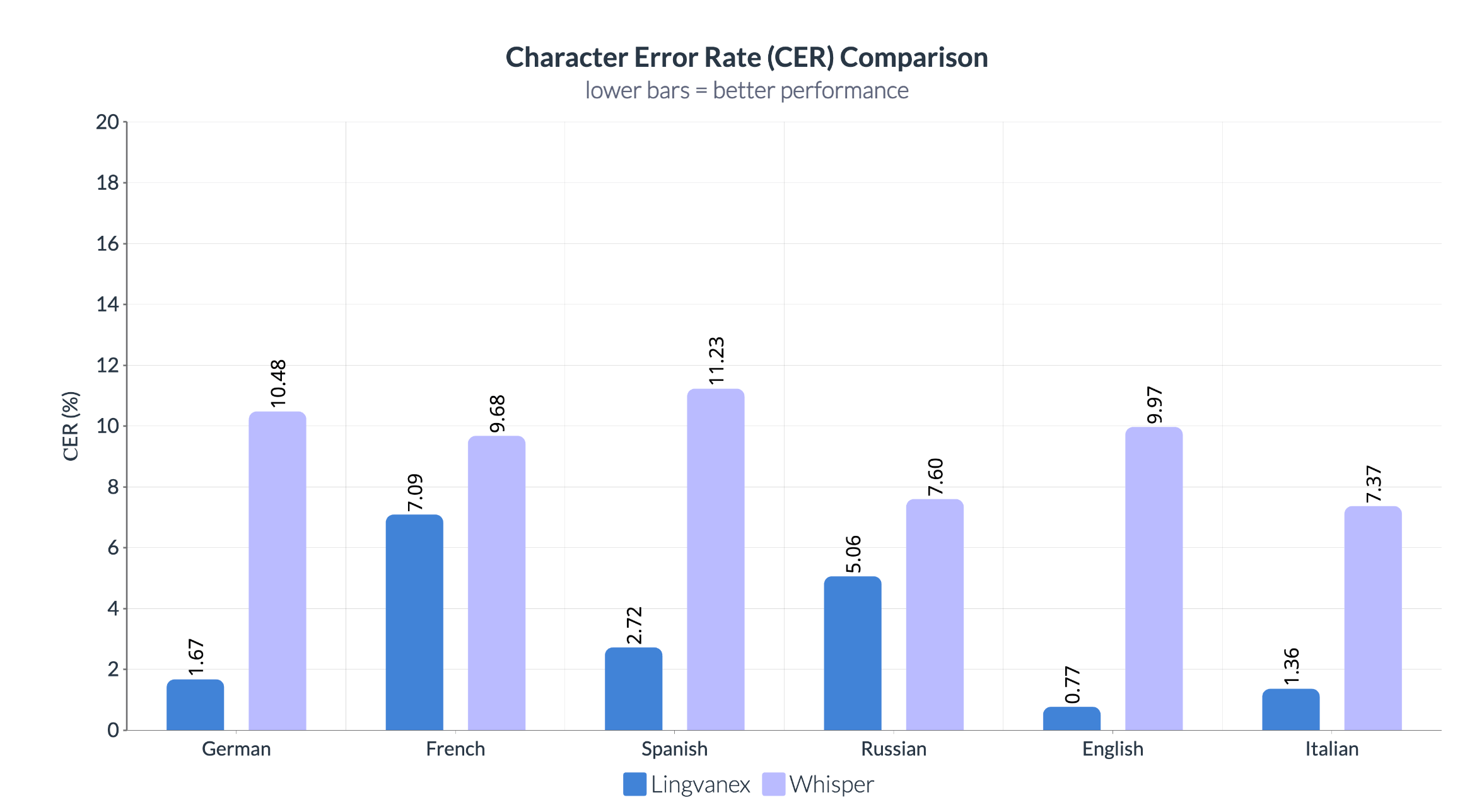
Character Error Rate provides a more detailed view of transcription quality by measuring errors at the character level. Lingvanex consistently outperforms Whisper across every tested language, with particularly strong results for English (0.77% vs. 9.97%) and German (1.67% vs. 10.48%). Lower CER is especially valuable when recognizing names, technical terminology, product codes, and other content where even a single incorrect character may change the meaning.
Processing Speed
Recognition accuracy is only one aspect of speech recognition performance. For live applications and enterprise-scale workloads, processing speed directly influences user experience, infrastructure costs, and overall system scalability.
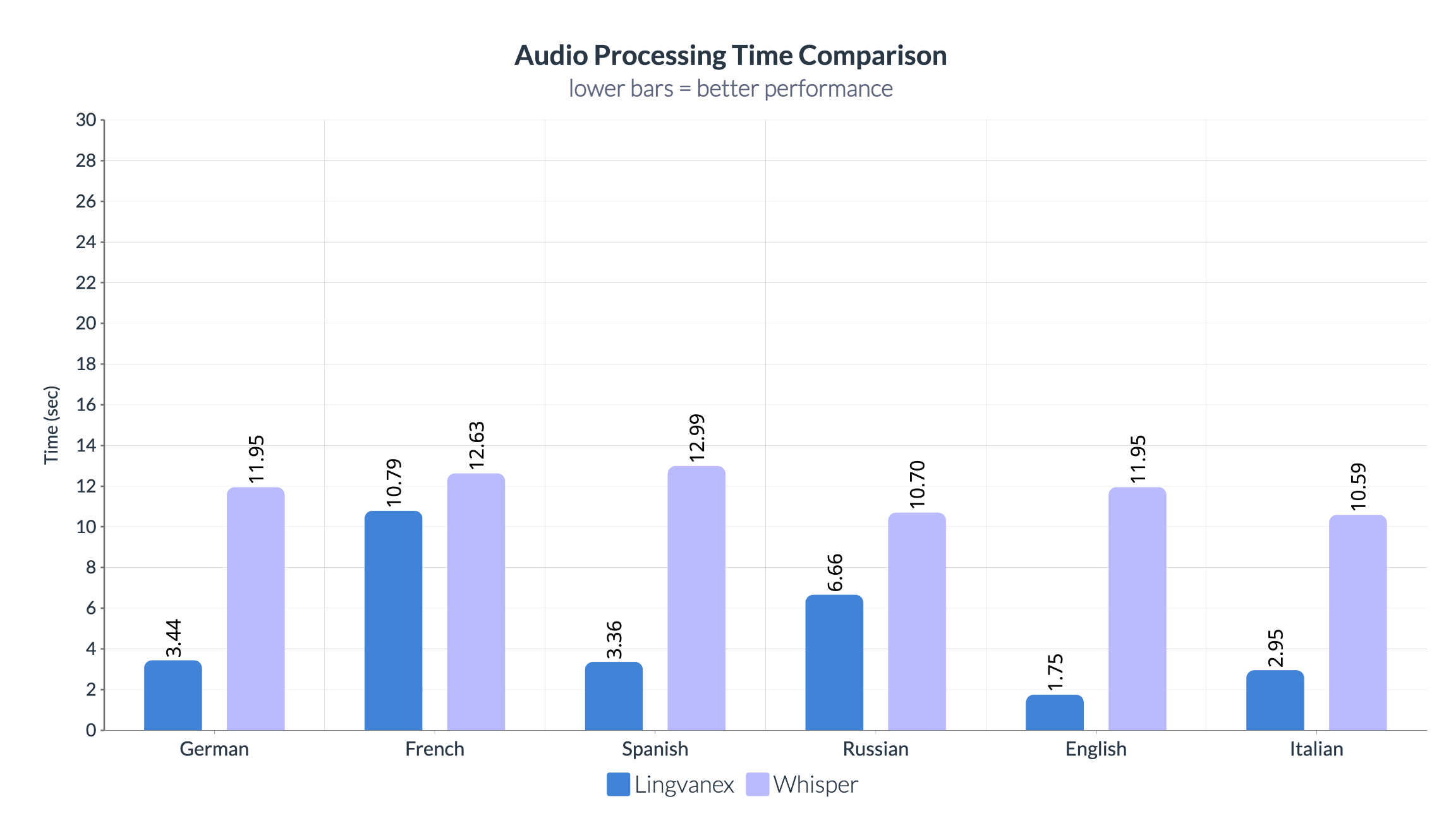
Lingvanex processes audio considerably faster than Whisper across all evaluated languages. For example, one minute of English audio is processed in only 1.75 seconds by Lingvanex, compared with 11.95 seconds for Whisper. Similar improvements are observed across German, Spanish, Russian, French, and Italian. Faster processing enables lower latency for real-time applications while also reducing hardware utilization and improving throughput for large-scale batch transcription.
Hardware Efficiency for Speech Recognition
Performance is determined not only by model quality but also by the computational resources required to achieve that performance. Efficient hardware utilization can significantly reduce infrastructure costs, especially for organizations processing thousands of hours of audio every month.
| Aspect | OpenAI Whisper | Lingvanex |
|---|---|---|
| CPU Inference | Supported, but larger Whisper models may require more processing time on CPUs. | Designed to provide efficient CPU inference for production deployments. |
| GPU Utilization | GPU acceleration is commonly used to improve throughput and reduce latency, particularly for large models. | Supports GPU acceleration for high-throughput and low-latency speech recognition. |
| Inference Engine | Performance depends on the selected implementation, such as the original Whisper project or optimized community alternatives like faster-whisper. | Uses a production-oriented inference engine designed for enterprise speech recognition workloads. |
| Scalability | Scaling typically requires organizations to design and manage their own deployment architecture. | Designed to support scalable deployments for multi-user and high-volume processing. |
| Deployment Efficiency | Infrastructure optimization depends on the organization's implementation and operational practices. | Provides an integrated deployment platform intended to simplify infrastructure management. |
Resource Requirements
The benchmark results demonstrate that Lingvanex consistently delivers lower transcription error rates and faster processing than Whisper across all tested languages. While Whisper remains a capable open-source speech recognition model, organizations deploying ASR in production environments must also consider processing speed, infrastructure efficiency, and scalability. The combination of lower WER, lower CER, and faster inference allows Lingvanex to reduce transcription errors, improve user experience, and process significantly larger audio volumes with the same computing resources.
Real-World Use Cases
The best speech recognition platform depends on the specific requirements of your application. While OpenAI Whisper is well suited for research projects and custom AI pipelines, enterprise environments often require additional capabilities such as real-time streaming, speaker diarization, secure deployment, and commercial support. The following examples illustrate which solution is better suited for common business scenarios.
Call Centers and Customer Support
Customer service operations require fast and accurate transcription of large volumes of conversations, often in real time. In addition to speech recognition, organizations typically need speaker diarization, API integration, scalability, and secure processing of customer data.
Whisper can be integrated into call center solutions, but organizations must build the surrounding infrastructure for streaming, speaker identification, and production deployment. Lingvanex provides these capabilities as part of an enterprise-ready platform, making it better suited for large-scale customer support environments.
Meeting Transcription
Businesses increasingly rely on automatic transcription for internal meetings, video conferences, and webinars. Accurate punctuation, speaker separation, and multilingual support improve the readability of meeting transcripts and simplify knowledge sharing.
Whisper performs well for offline meeting transcription, while Lingvanex offers additional enterprise features that simplify deployment for organizations processing meetings at scale.
Healthcare
Healthcare organizations process highly sensitive patient information and must comply with strict security and privacy requirements. Speech recognition systems used for clinical documentation must deliver high accuracy while ensuring that confidential medical data remains protected.
Both Whisper and Lingvanex can be deployed within private infrastructure. However, Lingvanex provides a production-ready platform with enterprise deployment options and commercial support, reducing the operational effort required to build and maintain a secure medical transcription system.
Legal and Government Organizations
Legal professionals and government agencies often work with confidential interviews, hearings, contracts, and official communications. These environments typically require offline processing, secure deployment, and complete control over sensitive information.
While Whisper offers the flexibility of self-hosting, organizations remain responsible for building and maintaining the surrounding infrastructure. Lingvanex is designed for secure enterprise deployments, making it well suited for organizations with strict compliance and data sovereignty requirements.
Financial Services
Banks, insurance companies, and financial institutions use speech recognition for customer service, compliance monitoring, and internal communications. These applications demand reliable performance, secure data processing, and scalable infrastructure capable of handling large volumes of audio.
Lingvanex provides enterprise deployment options and commercial support that simplify production adoption, while Whisper is better suited for organizations with dedicated engineering teams building custom speech recognition solutions.
AI Voice Assistants and Conversational AI
Developers building AI assistants, voice interfaces, or conversational applications often prioritize flexibility and customization. Whisper is a popular choice for these scenarios because it is open source and can be integrated into custom machine learning pipelines.
For organizations moving beyond prototypes to production systems, Lingvanex offers additional capabilities such as real-time streaming, enterprise APIs, and production-ready deployment that reduce implementation complexity.
Which Platform Fits Your Use Case?
There is no universal winner between Whisper and Lingvanex—the right choice depends on your priorities. Whisper is an excellent option for research, experimentation, and custom speech recognition pipelines built by experienced development teams. Lingvanex is better suited for organizations that require a production-ready platform with enterprise deployment, built-in APIs, commercial support, and secure processing of business-critical audio.
Final Verdict
OpenAI Whisper and Lingvanex are both powerful speech recognition solutions, but they are designed for different audiences and deployment scenarios. Whisper is an open-source ASR model that offers flexibility, transparency, and full control over the speech recognition pipeline. Lingvanex is a complete enterprise speech recognition platform that combines high recognition accuracy with production-ready deployment, security, scalability, and commercial support.
Choose OpenAI Whisper if:
- You need a free, open-source speech recognition model.
- You're building research projects, prototypes, or experimental AI applications.
- Your team has the expertise to develop and maintain a custom ASR infrastructure.
- You require maximum flexibility and control over the underlying model.
Choose Lingvanex if:
- You need a production-ready speech recognition platform.
- Your organization requires secure cloud, private cloud, or on-premise deployment.
- You process confidential or regulated data and need complete control over your infrastructure.
- You need real-time transcription, built-in APIs, speaker diarization, and enterprise-grade support.
- You want to reduce engineering effort and deploy speech recognition faster.
Ultimately, the choice depends on your priorities. If your goal is to experiment with speech recognition technology and build a custom solution from the ground up, Whisper remains one of the strongest open-source options available. If your goal is to deploy speech recognition reliably in a production environment with enterprise security, scalability, and long-term support, Lingvanex provides a comprehensive platform designed for those requirements.


