
The initialization process is the critical first step in training a model, laying the foundation for subsequent training steps. This complex procedure involves several key steps, each of which is performed sequentially to ensure that the model is properly configured and functional.
Through this structured initialization, the model is not only prepared for training, but also optimized for performance, laying the foundation for efficient training and accurate predictions. This paper details the steps involved in the initialization phase and provides insight into the underlying mechanisms and configurations that contribute to successful model training.
Initialization process
Model training begins by initializing this process. The following steps occur sequentially when you start the training:
- the configuration file is read and finalized (auto_config and user config files are merged);
├── config = self._finalize_config() module runner.py
├── def _finalize_config() module runner.py
├── def auto_config() module transformer.py
- tensorflow calculation type is set;
When training with mixed precision (FP16), set_global_policy (“mixed_float16”) is passed to tensorflow.
├── mixed_precision = self._mixed_precision and misc.enable_mixed_precision() module runner.py
├── def enable_mixed_precision() module misc.py
- Transformer model (or other type of model defined by the user) is initialized;
The model is initialized only after the calculation type is set, because the calculation type is fixed in the private attributes of the model.
If you initialize the model before initializing the calculation type, the value in the model attributes will not change and will be default float32:
_dtype_policy: <Policy “float32”>
_compute_dtype_object: <dtype: 'float32'>
├── model = self._init_model (config) module runner.py
├── def _init_model() runner.py
- the model optimizer is defined and initialized;
From the autoconfig of the Transformer model takes the name of the optimizer, which is set by default to LazyAdam. This optimizer is implemented in the TensorFlow Addons library.
The NoamDecay attenuation function is initialized with the following parameters:
━ 1) scale - the value from the Learning rate parameter of the training configuration file is set (in our example the value is 2);
━ 2) model_dim - the value from the num_units (Rnn size) parameter of the training configuration file is set (in our example the value is 4);
━ 3) warmup_steps - sets the value from the Warmup steps parameter of the training configuration file (in our example, the value is 8000).
The ScheduleWrapper wrapper class is initialized to augment the behavior of the learning rate scheduler with the following parameters:
━ 1) schedule - initialized above the NoamDecay fading function;
━ 2) step_start - set value from the start_decay_steps parameter of the training configuration file (default value is 0);
━ 3) step_duration - set value from the decay_step_duration parameter of the training configuration file (default value 1);
━ 4) minimum_learning_rate - set the value from the Minimum learning rate parameter of the training configuration file (in our example, the value is 0.0001).
LazyAdam optimizer class is initialized with the following parameters:
━ 1) learning_rate - ScheduleWrapper class initialized above;
━ 2) kwargs - dictionary of beta coefficients from the optimizer_params parameter of the training configuration file (in our example {'beta_1': 0.9, 'beta_2': 0.998});
━ 3) when training with mixed precision (FP16), the LazyAdam class is inherited from the tf.keras.mixed_precision.LossScaleOptimizer class, which initializes the following parameters:
- initial_scale = 32 768 - the value by which the value obtained from the loss function will be corrected;
- dynamic_growth_steps = 2 000 - how often to update the value to which the value of the loss function will be corrected.
├── optimizer = model.get_optimizer() module runner.py
├── def get_optimizer() module model.py
├── def make_learning_rate_schedule() module schedules/lr_schedules.py
├── def init() class NoamDecay (tf.keras.optimizers.schedules.LearningRateSchedule) module schedules/lr_schedules.py
├── def init() class ScheduleWrapper schedules/lr_schedules.py
├── ef make_optimizer() module optimizers/utils.py
- is set to batch_size_multiple;
If the Mixed precision or Jit compile function is activated, batch_size_multiple will be 8, otherwise 1.
├── batch_size_multiple = (...) module runner.py
- a function for creating and converting a dataset is created;
├── dataset_fn = (...) module runner.py
- if the effective_batch_size value is passed , the value at which the gradient will be updated is calculated;
├── accum_steps = _count_batch_accum() module runner.py
├── def _count_batch_accum() module runner.py
- embeddings for source and for target are initialized;
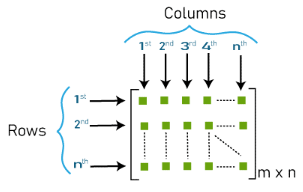
Embeddings dimension will be determined by the dictionary size and the size of the parameter num_units (Rnn size), where m is the number of tokens in the dictionary, n is the value of num_units. (Image 1 - matrix_m_n)
Embeddings are initialized via the tf.keras.Layer object, the add_weight function , which is called via the def build() function of the WordEmbedder class.
├── source_inputter = inputters.WordEmbedder(embedding_size=num_units)
├── def build()
├── target_inputter = inputters.WordEmbedder(embedding_size=num_units)
├── def build()
For example, for a dictionary of size 700 tokens and num_units (Rnn size) with a value of 8, a matrix containing 700 rows of 8 numbers each will be generated. Embeddings will look something like this:
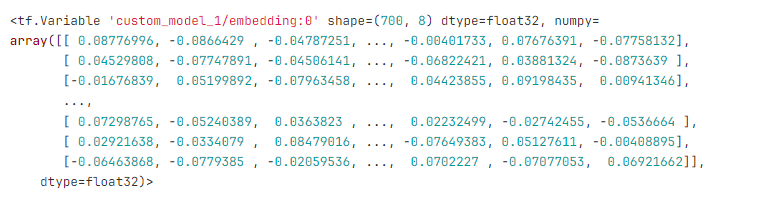
The values that are presented in the embedding matrix are formed according to a certain mechanism. For example, for a matrix of dimension 700x8:

We will have a matrix of dimension 700 x 8, where the values will be from -0.0920 to 0.0920, taken randomly from a uniform distribution. The mechanism described above is called Xavier Initialization. Implementation in tensorflow:
├── class GlorotNormal().init()
├── class VarianceScaling().call()
- weights (layers) of the model are initialized;
├── encoder = SelfAttentionEncoder() module transformer.py
├── self.layer_norm = common.LayerNorm() module self_attention_encoder.py
├── LayerNorm() module common.py
├── SelfAttentionEncoderLayer() module self_attention_encoder.py
├── self.self_attention = MultiHeadAttention() module layers/transformer.py
├── def build() module layers/transformer.py
├── TransformerLayerWrapper(self.self_attention) module layers/transformer.py
├── self.ffn = FeedForwardNetwork() module layers/transformer.py
├── TransformerLayerWrapper(self.ffn) module layers/transformer.py
├── decoder = SelfAttentionDecoder() module transformer.py
├── self.layer_norm = common.LayerNorm() module self_attention_decoder.py
├── LayerNorm() module common.py
├── SelfAttentionDecoderLayer() module self_attention_decoder.py
├── self.self_attention = MultiHeadAttention() module layers/transformer.py
├── def build() module layers/transformer.py
├── TransformerLayerWrapper(self.self_attention) module layers/transformer.py
├── attention = MultiHeadAttention() module layers/transformer.py
├── TransformerLayerWrapper(attention) module layers/transformer.py
├── self.ffn = FeedForwardNetwork() module layers/transformer.py
├── TransformerLayerWrapper(self.ffn) module layers/transformer.py
How the model initially looks like , weights and their values are shown on the example of a small network dimension:
- vocab: 26
- num_units: 4
- num_layers: 1
- num_heads: 2
- ffn_inner_dim: 1
- maximum_relative_position: 8
The model can be schematically depicted as follows. (Image 2 - model)
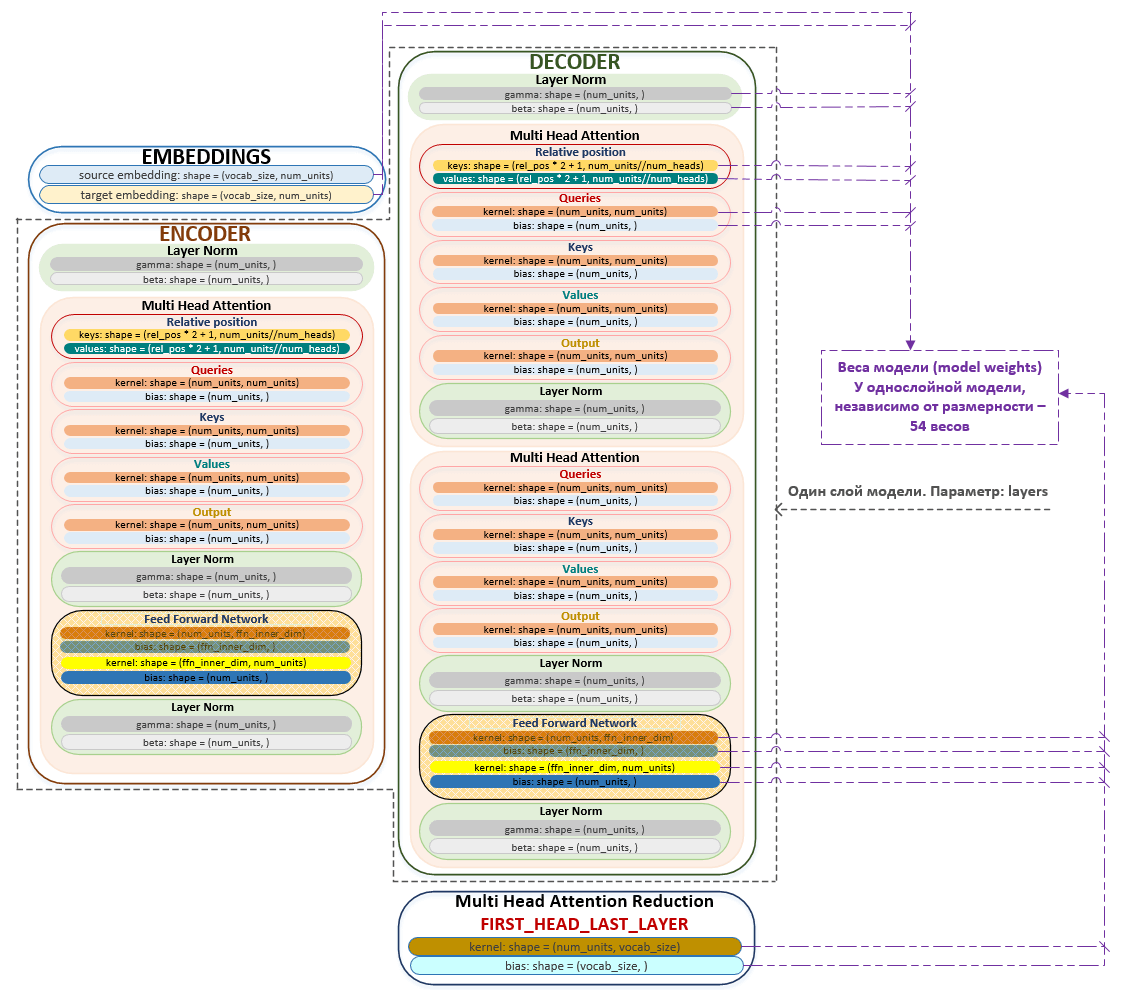
The kernel (i.e., main) weights of the model are initialized using the “Xavier Initialization” mechanism described above. The queries, keys, values and output layers are initialized via tf.keras.layers.Dense with the addition of the offset vector 'use_bias': True. FeedForwardNetwork weights are also initialized via tf.keras.layers.Dense with the activation of the linear layer tf.nn.relu. The normalization layer is initialized via tf.keras.layers.LayerNormalization, where beta dimension will be represented by zeros and gamma dimension by ones.
Layer normalization (Layer normalization, LN) is a deep learning technique used to stabilize the learning process and improve the performance of neural networks. It solves the internal covariance shift (ICS) problem where the distribution of activations within a layer changes during the learning process, making it difficult to train the network efficiently. A paper in which the Layer Normalization technique was presented Layer Normalization.
When initializing the model, the following condition must be met: num_units % num_heads, i.e. the dimensionality of embeddings (and respectively queries, keys and values) must be a multiple of the number of heads in MultiHeadAttention.
In fact, the matrices queries, keys and values are divided by the number specified in the num_heads parameter and smaller matrices are formed, the number of which is equal to num_units // num_heads. The algorithm is implemented in the split_heads function of the ransformer.py module. (Image 3 - Multi Head Attention)
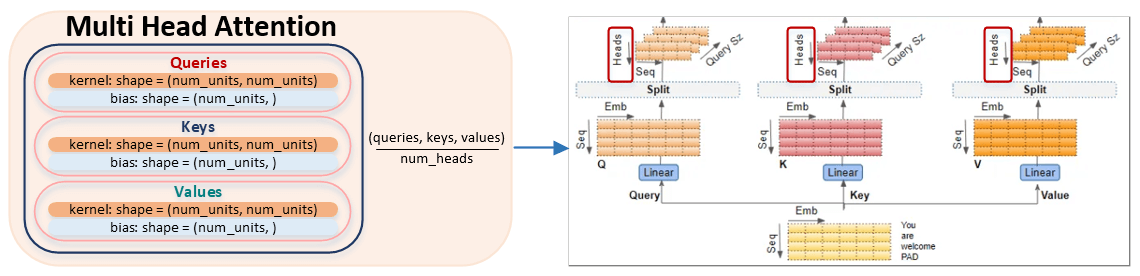
Let's consider the algorithm of partitioning the matrices queries, keys and values by the number of heads. For simplicity of perception, we will take the dimensionality of num_units equal to 4 and the number of heads num_heads equal to 2.
For example, we have a token batch:

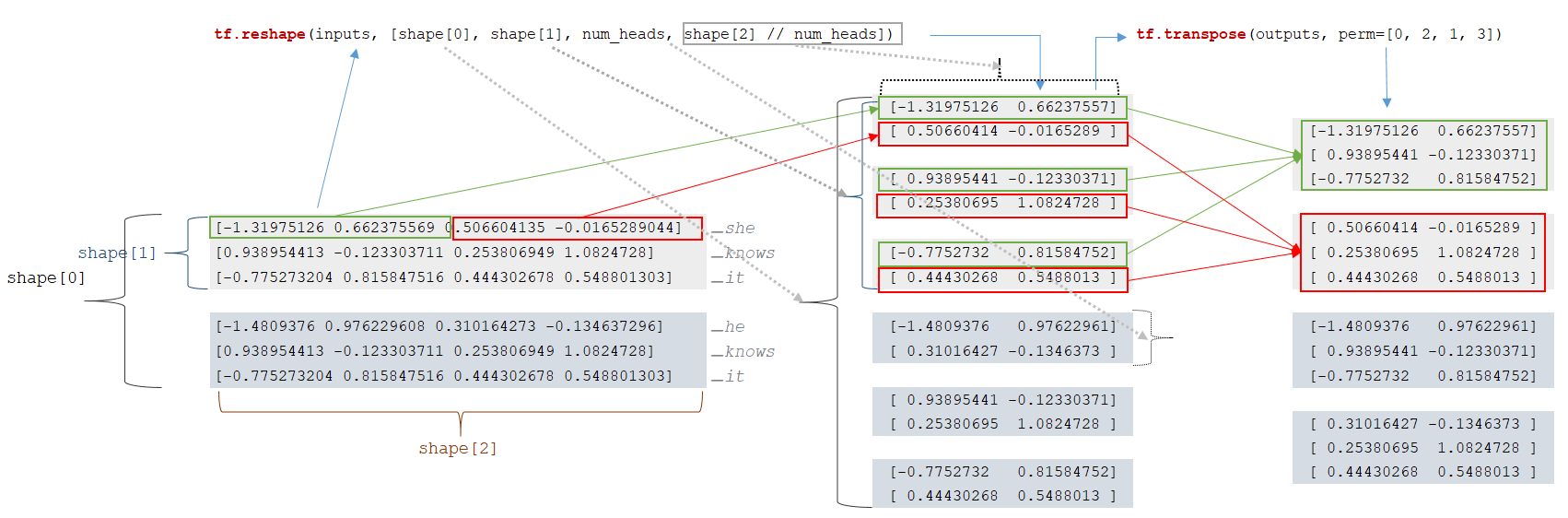
For each token, a vector representation of the token is extracted from the embedding matrix (the mechanism is described below) and a matrix of vectors is formed. The dimensionality of the batchet is calculated: input_shapes = [2, 3, 4]. There are 2 sequences in the batches, each sequence has 3 tokens, each token is represented by a vector of dimensionality 4. The next step is to change the dimensionality of the inputs matrix :
- outputs = tf.reshape(inputs, [shape[0], shape[1], num_heads, shape[2] // num_heads]) → tf.reshape(inputs, [2, 3, 2, 4 // 2])
- outputs = tf.transpose(outputs, perm=[0, 2, 1, 3])
After reshaping the dimensionality, we obtain matrices of lower dimensionality. (Image 4 - Reshape matrix)
This is the end of the model initialization process and the training process itself begins.
Conclusion
The process of model initialization is a crucial prerequisite for effective learning, ensuring that all configurations, optimizers, and embeddings are properly set up. By systematically defining the type of computation, preparing the dataset, and initializing the model weights using techniques such as Xavier initialization and layer normalization, the framework can be optimized. This detailed approach not only improves computational efficiency, but also stabilizes the learning process, paving the way for successful model training and accurate predictions. Understanding these fundamental steps is essential for those who want to effectively utilize deep learning models.


