
This article is a continuation of the first part “Inference generation mechanism in a trained sequence generation model”, which is devoted to the process of inference generation in a trained sequence generation model, illustrating its architecture and functionality on the example of the phrase “he knows it”. In this part, we consider the remaining three steps of the inference generation mechanism.
By breaking down the step-by-step operations involved in sequence generation, we aim to provide a comprehensive understanding of how these models produce coherent and contextually appropriate outputs. This study will not only help to understand the underlying mechanisms of sequence generation, but also lay the foundation for future improvements in model development and application.

Step1
By word_ids matrix obtained at step step = 0 we extract vector representations of tokens from the target embeddings matrix of the trained model and together with encoder_outputs matrix duplicated by the number of beam_size is fed to the decoder input. From the decoder we get the matrix logits and attention. (Image 1 - logits and attention matrices)
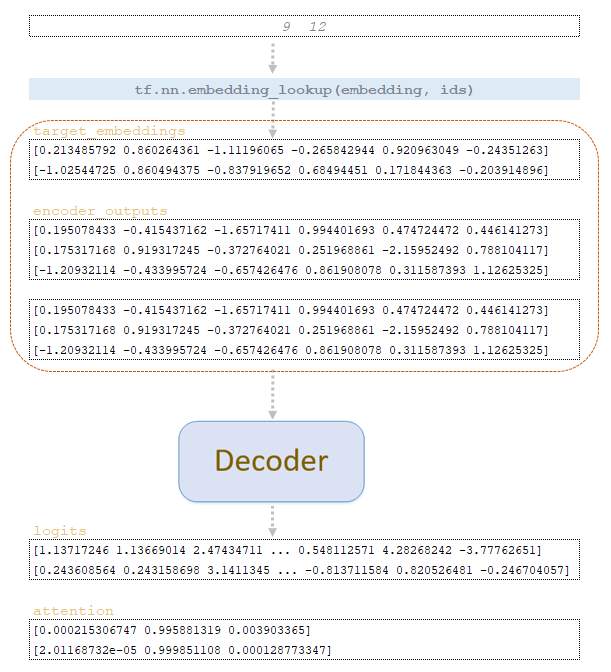
After passing the above operations we get after step 1 the matrices word_ids, cum_log_probs, finished, and dictionary extra_vars/.
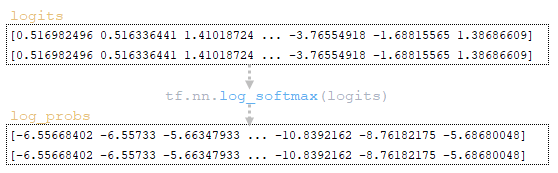
(Image 2a - logits and log_probs) (Image 2b - total_probs) (Image 2c - top_scores and top_ids) (Image 2d - matrices word_ids, cum_log_probs, finished, and dictionary extra_vars)
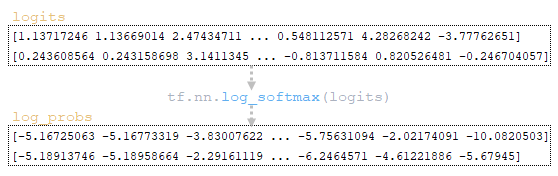

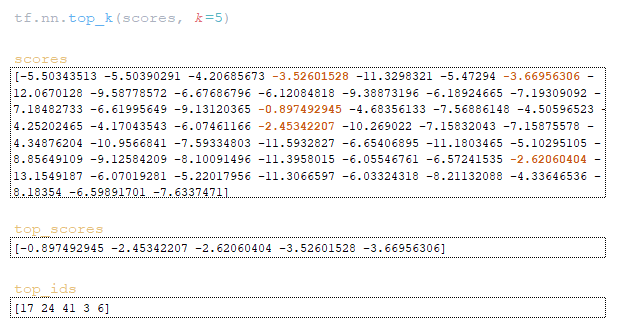

Step2
According to the word_ids matrix obtained at step step = 1, vector representations of tokens are extracted from the target embeddings matrix of the trained model and, together with the encoder_outputs matrix duplicated by the number of beam_size, are fed to the input of the decoder. From the decoder we get the matrix logits and attention. (Image 3 - logits and attention matrices, step2)

Carry out all the above operations and get the matrices word_ids, cum_log_probs, finished and dictionary extra_vars after step 2.
(Image 4a - logits and log_probs) (Image 4b - total_probs) (Image 4c - top_scores and top_ids) (Image 4d - matrices word_ids, cum_log_probs, finished, and dictionary extra_vars)

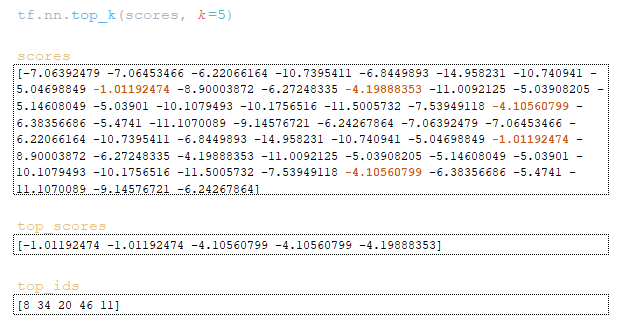

Step3
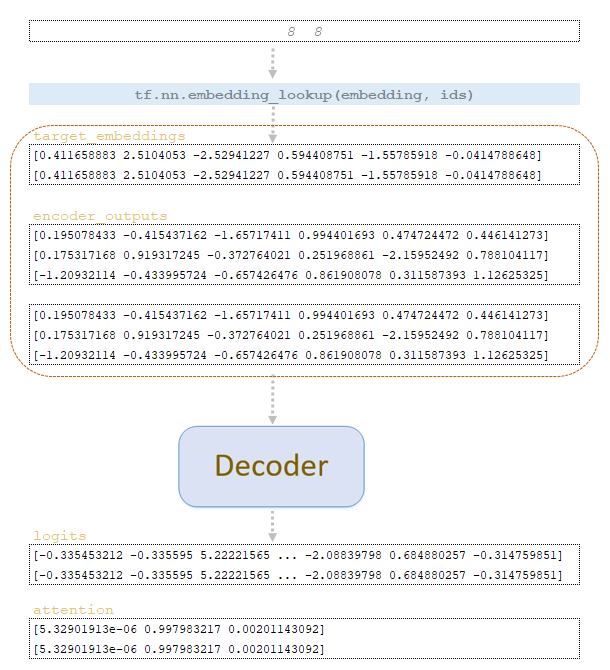
Using the word_ids matrix obtained at step step = 2, we extract vector representations of tokens from the target embeddings matrix of the trained model and, together with the encoder_outputs matrix duplicated by the number of beam_size, feed it to the decoder input. From the decoder we get the matrix logits and attention. (Image 5 - logits and attention matrices, step 3)
Perform the above operations and get the matrices word_ids, cum_log_probs, finished and dictionary extra_vars after step 3.
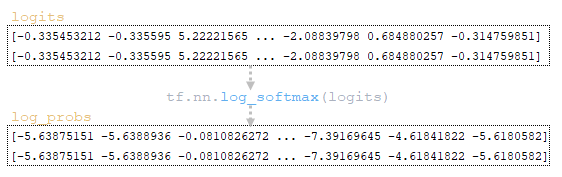
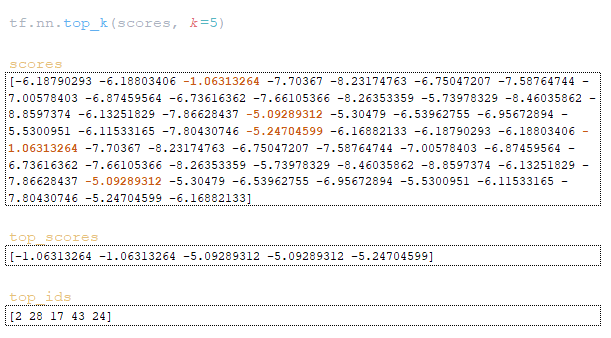
(Image 6a - logits and log_probs) (Image 6b - total_probs) (Image 6c - top_scores and top_ids) (Image 6d - matrices word_ids, cum_log_probs, finished, and dictionary extra_vars)


At this step, the loop is interrupted because the decoder has generated end-of-sequence tokens </s> with id = 2.
The obtained sequences of id tokens are decoded and hypotheses of translation of source sentences are obtained. The number of hypotheses cannot be greater than beam_size, i.e. if we want to get 3 alternative translations, we need to set beam_size=3.
In fact, as a result we have 2 hypotheses, the 1st hypothesis will contain sequences of the most probable tokens obtained and several distributions. (Image 7 - target_tokens)

Conclusion
In this analysis, we studied the inference mechanism in a trained sequence generation model using the phrase “he knows that” as an example. We outlined the architecture of the model, detailing how tokens are represented and processed through the encoder and decoder. Key components of the inference process such as parameter initialization, application of ray search, computation of logarithmic probabilities and scores were discussed in detail. We highlighted the step-by-step operations involved in sequence generation, including how matrices are transformed and updated at each iteration.
Ultimately, this mechanism allows the model to generate sequences that are relevant to the context, ultimately leading to the generation of hypotheses for translation. Studying this process not only deepens our understanding of sequence generation, but also helps us improve future model architecture and performance.


