
In this paper, we examine the inference mechanism in a trained model using the string “he knows this” as an example. We will outline the architecture of the model, which exactly replicates the learning process, and examine the various components involved in converting input tokens into meaningful predictions. Key parameters such as vocabulary size, number of units, layers, and heads of attention will be considered to provide context for the model's functionality.

Model Architecture Overview
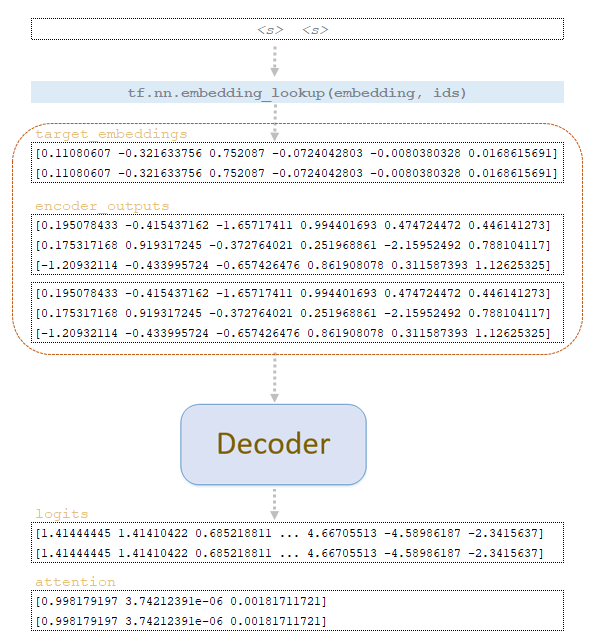
Let us consider the mechanism of inference of the trained model on the example of the following string ▁he ▁knows ▁it. The architecture of the model, for clarity, will be approximately the same as in the considered example of the mechanism of the training process:
- vocab: 26
- num_units: 6
- num_layers: 1
- num_heads: 2
- ffn_inner_dim: 12
- maximum_relative_position: 8
Token Representation and Encoder Processing
For each token, the vector representation of the token is extracted from the source embedding matrix of the trained model and fed to the encoder input. In the encoder, absolutely all the same transformations occur as in the model training. The difference is that the dropout mechanism is not applied to the matrices. After transformations in the encoder we get the encoder_outputsmatrix. (Image 1 - The encoder_outputs matrix)

Parameters and initialization of inference
Next, consider an example for inference with the following parameters. In our case, the following inference parameters were used:
- beam_size = 2
- length_penalty = 0.2
- coverage_penalty = 0.2
- sampling_topk = 5
- sampling_temperature = 0.5
Then applying the function tfa.seq2seq.tile_batch (encoder_outputs, beam_size) allows the value matrix obtained after the encoder to be duplicated by the amount of beam_size. The output is a matrix of values * beam size, in our case two. (Image 2 - Encoder outputs * beam size)

The second step is to initialize the variables:
1) batch size for translation, in our example batch_size = 1;
2) matrix start_ids, containing indices of tokens of the start of sequence <s> by beam_size dimension → start_ids = tfa.seq2seq.tile_batch (start_ids, beam_size) = [1 1];
3) matrix finished, filled with zeros, with boolean data type and dimension batch_size * beam_size → tf.zeros ([batch_size * beam_size], dtype=tf.bool)] = [0 0];
4) matrix initial_log_probs → tf.tile ([0.0] + [-float(“inf”)] * (beam_size - 1), [batch_size]) = [0 -inf];
5) dictionary with extra variables extra_vars, which contains the following variables, is initialized:
- parent_ids: tf.TensorArray(tf.int32, size=0, dynamic_size=True) → []
- sequence_lengths: tf.zeros([batch_size * beam_size], dtype=tf.int32) → [0 0]
- accumulated_attention: tf.zeros([batch_size * beam_size, attention_size]), where attention_size is the dimension of the encoder_outputs matrix (tf.shape(encoder_outputs)[1] = 3) → [[0 0 0] [0 0 0]]
Then, in a loop, iterate until we reach the maximum value (the default maximum value is maximum_decoding_length = 250) or until an end-of-sequence token is generated.
Step 0
By matrix start_ids, vector representations of tokens are extracted from the target embeddings matrix of the trained model and together with encoder_outputs matrix duplicated by the number of beam_size is fed to the decoder input. In the decoder, absolutely all the same transformations take place as when training the model. The difference is that the future_mask tensor is not formed , and also the dropout mechanism is not applied. (Image 3 - decoder process)
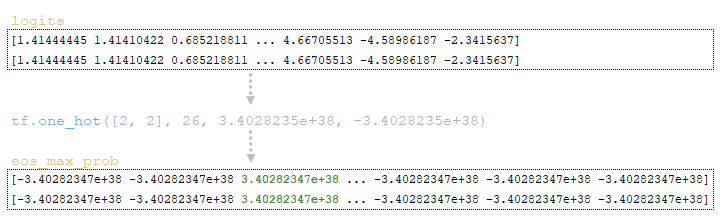
Variables batch_size = 1 and vocab_size = 26 are formed by the dimension of the logits matrix obtained from the decoder. Next, using the function tf.one_hot(tf.fill([batch_size], end_id), vocab_size, on_value=logits.dtype.max, off_value=logits.dtype.min) the matrix eos_max_prob, where:
- tf.fill([batch_size], end_id); end_id is the index of the end-of-sequence token </s> → [2 2];
- logits.dtype.max is the maximum value of the tf.float32 data type, which is 3.4028235e+38 or 34028235000000000000000000000000000000;
- logits.dtype.min is the maximum value of the tf.float32 data type, which is equal to -3.4028235e+38 or -34028235000000000000000000000000000000.
Thus, the output is a matrix eos_max_prob of dimension 2 x 26, where the elements at index 2 will be filled with the maximum value and all other elements will be filled with the minimum value. (Image 4 - eos_max_prob matrix)
Using the function tf.where (tf.broadcast_to (tf.expand_dims (finished, -1), tf.shape(logits)), x=eos_max_prob, y=logits), where the matrix finished changes in dimension: tf.expand_dims([0, 0], -1) → [ [0][0]], get an array of values along the dimension of the logits matrix: tf.shape(logits) → [2 26] and increase the dimensionality: tf.broadcast_to ([[0], [0]], [2, 26]) → [[0 0 0 0 ... 0 0 0 0], [0 0 0 0 ... 0 0 0]].
Since the finished matrix contains zeros and the expanded matrix contains zeros, the values of the final matrix are filled with values from the logits matrix.
The log_probs matrix is calculated from the logits matrix using the function tf.nn.log_softmax(logits). (Image 5 - Matrix log_probs)

If coverage_penalty != 0, the following actions are performed additionally:
- the matrix finished is modified and transformed using the function tf.math.logical_not([0, 0]) to form the matrix not_finished → [1 1];
- the resulting matrix is dimensionally modified tf.expand_dims (tf.cast(not_finished, attention.dtype), 1) → [[1], [1]] ;
- the obtained matrix is multiplied with the attention matrix; (Image 6 - attention matrix)
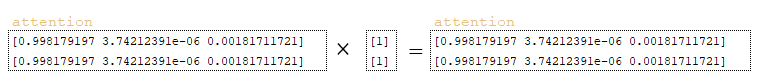
- accumulated_attention variable is formed. (Image 7 - accumulated_attention variable)
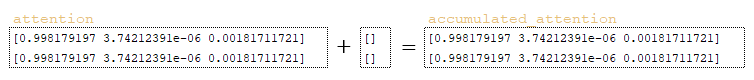
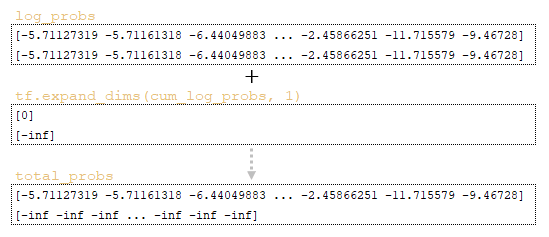
Then the total_probs matrix is formed by adding the log_probs matrix and the inverted cum_log_probs matrix → log_probs + tf.expand_dims (cum_log_probs, 1). (Image 8 - total_probs matrix)
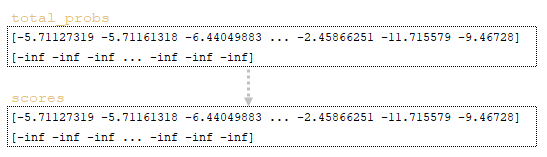
By matrices total_probs, sequence_lengths, finished and accumulated_attention scores are calculated. The calculation of scores involves the following steps:
1) The original matrix scores → scores = total_probs is initialized by the matrix total_probs (Image 9 - total_probs and scores matrices);
2) If length_penalty != 0, perform the following actions:
- expand_sequence_lengths matrix is formed - the sequence_lengths matrix is dimensionally changed tf.expand_dims (sequence_lengths, 1) → [[0], [0]] ;
- one is added to the expand_sequence_lengths matrix and the matrix is cast to the log_probs value type - tf.cast (expand_sequence_lengths + 1, log_probs.dtype) → [[0], [0]] + 1 = [[1], [1]] ;
- matrix sized_expand_sequence_lengths is formed - constant 5 is added to the matrix obtained above and divided by constant 6: (5.0 + expand_sequence_lengths) / 6.0 → (5 + [1]) / 6 = [[1], [1]].
- matrix sized_sequence_lengths is formed - matrix sized_expand_sequence_lengths is raised to the degree specified in the length_penalty parameter : tf.pow (sized_expand_sequence_lengths, length_penalty) → [[1]**0.2, [1]**0.2] = [[1], [1]];
- matrix values are corrected by integer division by the penalized_sequence_lengths matrix → scores /= penalized_sequence_lengths. (Image 10 - scores)

3) If coverage_penalty!= 0, then, perform the following actions:
- the matrix equal is formed by the matrix accumulated_attention using the function tf.equal (accumulated_attention, 0.0) tf.expand_dims (sequence_lengths, 1), i.e. we check the matrix elements for equality to zero; (Image 11 - equal matrix)

- the accumulated_attention matrix is used to form a matrix of ones_like units using the function tf.ones_like (accumulated_attention); (Image 12 - ones_like matrix)

- using the function tf.where (equal, x=ones_like, y=accumulated_attention ) the accumulated_attention matrix is redefined, where values will be taken from x if the element from equal is equal to one, otherwise from y. Since all elements of the equal matrix are equal to zero, all values will be taken from y; (Image 13 - accumulated_attention matrix)

- coverage_penalty matrix is formed - the minimum value is taken from the accumulated_attention matrix and unit and the logarithm is calculated, and then the elements are summed tf.reduce_sum (tf.math.log (tf.minimum (accumulated_attention, 1.0)), axis=1) ; (Image 14 - coverage_penalty matrix)

- the coverage_penalty matrix obtained at the previous step is multiplied with the matrix finished coverage_penalty *= finished ; (Image 15 - coverage_penalty)

- the matrix scores is adjusted by the specified coverage_penalty value from the parameters and the calculated coverage_penalty matrix - scores += self.coverage_penalty * tf.expand_dims (coverage_penalty, 1). (Image 16 - scores matrix)
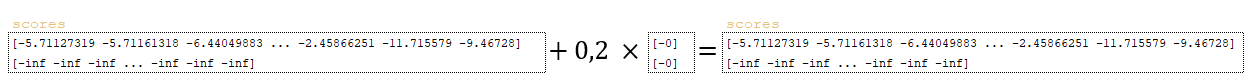
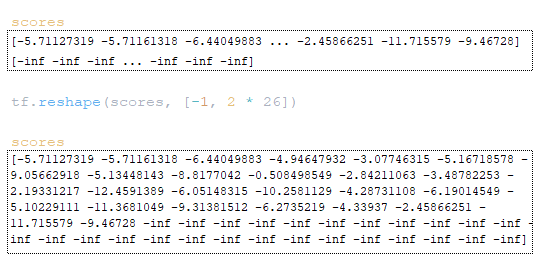
The next step involves working with the scores and total_probs matrices. The scores matrix is reshaped by tf.reshape (scores, [-1, beam_size * vocab_size]). (Image 17 - scores matrix)
The total_probs matrix is reshaped by tf.reshape (scores, [-1, beam_size * vocab_size]). (Image 18 - total_probs matrix)
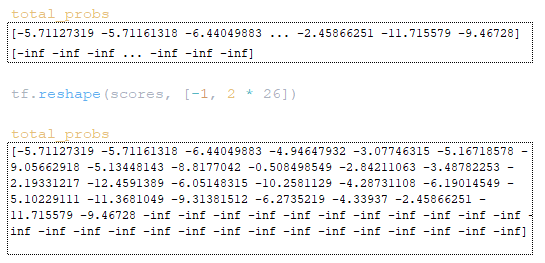
The next step is to calculate the id target tokens sample_ids and the scores for these tokens sample_scores:
- using the function tf.nn.top_k find the maximum values and their indices top_scores, top_ids = tf.nn.top_k(scores, k=sampling_topk) (if the sampling_topk parameter is not specified, then k will be equal to beam_size); (Image 19 - top_scores and top_ids matrix)
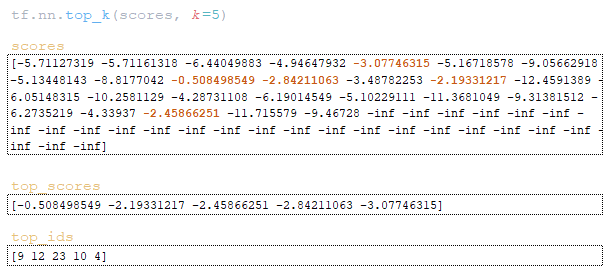
- the top_scores matrix is divided by the value of the sampling_temperature parameter; (Image 20 - sampling_temperature parameter)
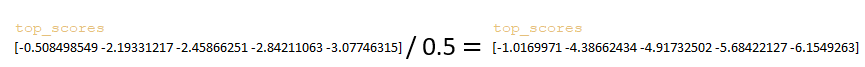
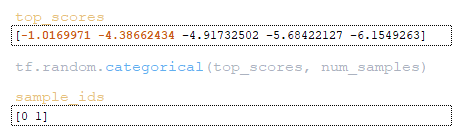
- from the corrected matrix top_scores using the function tf.random.categorical the indexes of elements in the number of beam_size are extracted; (Image 21 - sample_ids)
- by element indices, using the function tf.gather, token indices are extracted from the matrix top_ids ; (Image 22 - token indices)
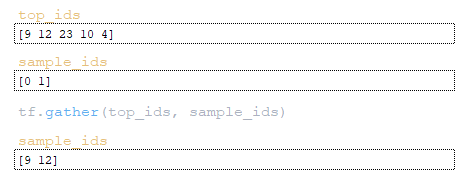
- by element indices, the scores for these tokens are extracted from the scores matrix using the tf.gather function. (Image 23 - sample_scores matrix)
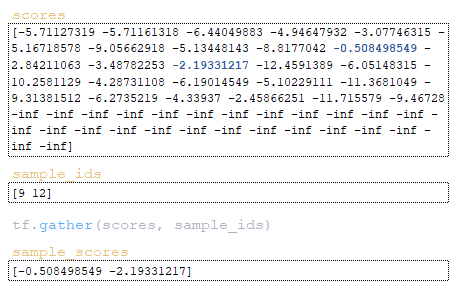
Then the cum_log_probs matrix is formed by the obtained values of sample_ids from the total_probs matrix. (Image 24 - cum_log_probs matrix) Word_ids matrix is formed by dividing the remainder by vocab_size value → word_ids = sample_ids % vocab_size = [9 12] % 26 = [9 12].
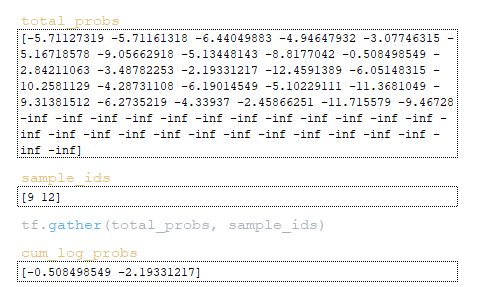
By integer division by the value of vocab_size the matrix beam_ids → beam_ids = sample_ids // vocab_size = [9 12] // 26 = [0 0 0] is formed by the received values of sample_ids, by integer division by the value of vocab_size.
Using the obtained word_ids and beam_ids matrices and the beam_size value, the beam_indices matrix is formed → beam_indices = (tf.range (tf.shape(word_ids)[0]) // beam_size) * beam_size + beam_ids = ([0 1] // 2) * 2 + [0 0 0] = [ 0 0].
A further step involves the redistribution of matrixes sequence_lengths, finished and sequence_lengths as follows:
- sequence_lengths matrix is redefined → sequence_lengths = tf.where(finished, x=sequence_lengths, y=sequence_lengths + 1); (Image 25 - sequence_lengths matrix)

- overrides matrix finished → finished = tf.gather(finished, beam_indices) → tf.gather([0 0], [0 0]) = [0 0] ;
- sequence_lengths matrix is redefined → finished = tf.gather(sequence_lengths, beam_indices) → tf.gather([1 1 1], [0 0]) = [1 1].
After that the work with the dictionary extra_vars will be done, as follows:
- the sequence_lengths matrix is stored into the extra_vars dictionary by the sequence_lengths key → extra_vars = {“sequence_lengths”: sequence_lengths};
- beam_ids and current step values are written to the extra_vars dictionary using the parent_ids key → extra_vars = {“parent_ids”: parent_ids.write (step, beam_ids)};
- accumulated_attention matrix is stored into the extra_vars dictionary by key accumulated_attention → tf.gather ( accumulated_attention, beam_indices); (Image 26 - accumulated_attention matrix)
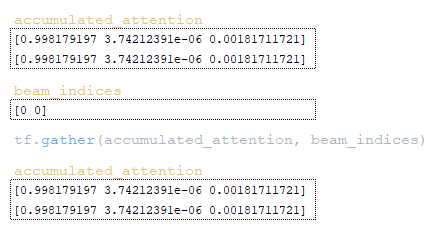
- The obtained word_ids values are checked for equality with the end-of-sequence token and the matrix finished is redefined → finished = tf.logical_or (finished, tf.equal (word_ids, end_id)).
This completes step 0, the matrices word_ids, cum_log_probs, finished, and dictionary extra_vars are passed to the beginning of the loop and the whole process described above. (Image 27 - matrices word_ids, cum_log_probs, finished, and dictionary extra_vars)

Conclusion
In this article, we thoroughly examined the inference mechanism of a trained model using the example string "he knows it." We began by outlining the model architecture and the essential parameters that define its structure, such as vocabulary size, number of units, and layers.
The process of token representation and encoder processing was detailed, emphasizing the transformation of input tokens through the encoder without applying dropout, thereby ensuring consistency with the training phase. We discussed the initialization of inference parameters and the looping structure that governs the iterative decoding process, highlighting the various matrices involved, including log_probs, total_probs, and the management of penalties.
In the second part of this article we will cover step 1, step 2 and step 3 respectively, where the details of the inference mechanism will also be revealed.


