
At a Glance
- Comparison of leading speech recognition APIs, including Lingvanex, Deepgram, AssemblyAI, Gladia, and Speechmatics.
- Evaluation based on Word Error Rate (WER) and Character Error Rate (CER).
- Testing across 12 languages, including English, Chinese, Arabic, and Kazakh.
- Real-world audio scenarios: calls, meetings, noisy environments, and studio recordings.
- Analysis of performance variability across languages and conditions.
- Insights into challenges of ASR evaluation beyond controlled benchmarks.
- Overview of deployment options, including on-premise speech recognition and integration with machine translation.

Disclaimer: This material was prepared by Lingvanex specialists, including software and hardware developers and DevOps engineers with experience in speech recognition systems. The evaluation is based on internal testing and analysis, and reflects results obtained under specific testing conditions. Results may vary depending on datasets, configurations, and real-world usage scenarios.
Speech recognition is widely used across modern software systems, including customer support tools, voice assistants, meeting transcription services, and compliance platforms. As adoption grows, so does the need for consistent and reliable transcription quality.
In practice, the performance of speech recognition systems can vary significantly depending on the conditions. Factors such as background noise, speaker accents, audio quality, and multilingual input often affect accuracy and lead to inconsistent results.
One of the challenges in evaluating these systems is that many benchmarks rely on controlled datasets that do not fully reflect real-world usage. This can make it difficult to assess how different solutions perform in production environments.
This article presents a comparison of several speech recognition APIs based on testing across multiple languages, audio conditions, and use cases. The evaluation focuses on Word Error Rate (WER) and Character Error Rate (CER) to provide a consistent basis for comparison.
Who This Article is For
This article may be relevant for:
- CTOs and engineering leaders evaluating speech recognition technologies for production use.
- Product managers working on voice-enabled applications such as voicebots, transcription tools, or customer support systems.
- AI and ML engineers comparing ASR models and performance metrics across different providers.
- Technical decision-makers selecting solutions for multilingual or global deployments.
- Teams working in regulated industries (e.g., finance, healthcare, legal) where transcription accuracy and data handling are important.
Why Speech Recognition Accuracy Matters for Business
Speech recognition has become a core component of many business systems, including customer support platforms, video conferencing tools, legal workflows, and financial services applications. As adoption increases, organizations rely on transcription accuracy for day-to-day operations.
Inconsistent ASR performance can lead to measurable business impact. When transcription quality declines, it affects multiple areas:
- Customer Support Quality. Errors in call transcription can result in misunderstandings, unresolved issues, and lower customer satisfaction
- Regulatory Compliance. Inaccurate transcripts in regulated industries such as finance or healthcare may create compliance risks
- Data Quality and Insights. Missing or incorrect information in meetings and interviews can affect analysis, reporting, and decision-making
These issues are more noticeable in real-world conditions, where speech recognition systems must process diverse inputs. Variability in accents, background noise, speech pace, and multilingual conversations often exposes limitations in model performance.
For example, even small transcription errors can change the meaning of a request or statement, which may lead to incorrect actions or misinterpretation of intent.
As a result, evaluating speech recognition systems requires more than basic accuracy metrics. It is important to consider how systems perform under realistic conditions and whether they can maintain consistency across different use cases and environments.
Why Real-World Conditions Matter
In practice, speech recognition systems operate in conditions that are far from ideal. Audio quality varies, speakers have different accents, and conversations often include interruptions or background noise.
Several factors can directly affect speech recognition accuracy:
- audio quality and recording conditions;
- background noise and environmental interference;
- speaker accents, dialects, and pronunciation;
- speech speed, pauses, and disfluencies;
- overlapping speech and multi-speaker conversations;
- multilingual input or code-switching.
These factors introduce variability that directly impacts transcription results. Even small errors can change the meaning of a sentence, especially in customer interactions or compliance-related use cases.
Because of this, evaluating ASR performance requires testing beyond controlled environments. It is important to understand how systems behave under realistic conditions and whether they can maintain accuracy across different scenarios.
This is the approach we used in our evaluation.
Methodology for Evaluating Speech Recognition Systems
To assess how modern speech recognition APIs perform in real-world conditions, we designed a testing process based on typical business use cases. The goal was to evaluate how systems handle everyday speech across different environments, languages, and audio qualities.
Here’s how we did it.
Audio Samples
We used a diverse set of audio recordings to reflect realistic input scenarios:
- Clean studio recordings were used as a baseline for accuracy.
- Phone call audio included narrow-band, compressed speech typical for call centers.
- Meeting conversations featured multiple speakers with interruptions and variable pacing.
- Street and café recordings captured background noise and uncontrolled environments.
This setup helps evaluate how systems perform beyond ideal conditions.
Languages Tested
We selected languages for testing that represent a mix of high-resource and lower-resource scenarios, as well as different linguistic structures:
English, Simplified Chinese, Arabic, Portuguese, Spanish, French, German, Italian, Russian, Ukrainian, Kazakh, and Polish.
Evaluation Metrics
We used two standard metrics to measure speech recognition performance: Word Error Rate (WER) and Character Error Rate (CER). Together, these metrics provide a more complete view of transcription accuracy across different languages and use cases.
What is Word Error Rate (WER)?
Word Error Rate (WER) is a standard metric used to evaluate speech recognition accuracy. It measures the percentage of words that are incorrectly recognized in a transcript compared to a reference text.
WER includes three types of errors:
- substitutions;
- deletions;
- insertions.
A lower WER indicates higher accuracy and is commonly used as a baseline for comparing speech recognition systems.
What is Character Error Rate (CER)?
Character Error Rate (CER) measures transcription accuracy at the character level. Instead of comparing full words, it evaluates how many individual characters are recognized incorrectly.
CER provides a more detailed view of transcription quality and is particularly useful for:
- names;
- technical terms;
- languages with complex morphology.
A lower CER indicates higher precision.
WER vs. CER: What’s the Difference
Word Error Rate (WER) and Character Error Rate (CER) measure speech recognition accuracy at different levels.
- WER evaluates errors at the word level;
- CER evaluates errors at the character level.
WER provides a general measure of transcription accuracy, while CER offers more detailed insight into spelling and fine-grained errors.
You can learn more about current challenges in speech recognition evaluation methodologies in a separate article.
Speech Recognition API Comparison Results: Lingvanex
Quick Overview
- Lingvanex – speech recognition solution with support for on-premise deployment and integration with translation workflows
- Deepgram (Nova-2) – API-focused speech recognition platform with emphasis on real-time processing
- AssemblyAI – cloud-based speech-to-text API with a focus on developer integration and additional AI features
- Gladia – speech recognition API designed for multilingual transcription and audio intelligence use cases
- Speechmatics – speech recognition system with support for multiple languages and deployment options
To evaluate performance in realistic conditions, we conducted a side-by-side comparison of several widely used speech recognition APIs, including Lingvanex, Deepgram (Nova-2), AssemblyAI, Gladia, and Speechmatics.
These systems represent different approaches to speech recognition in terms of architecture, deployment models, and target use cases, but are all positioned as production-ready solutions.
Key Findings
- Lowest WER observed in several tested languages, including English, German, and Spanish.
- Highest variability observed in multilingual and lower-resource language scenarios.
- Performance differences increase in real-world conditions, including noisy audio and overlapping speech.
- Multilingual performance remains a key differentiator across providers.
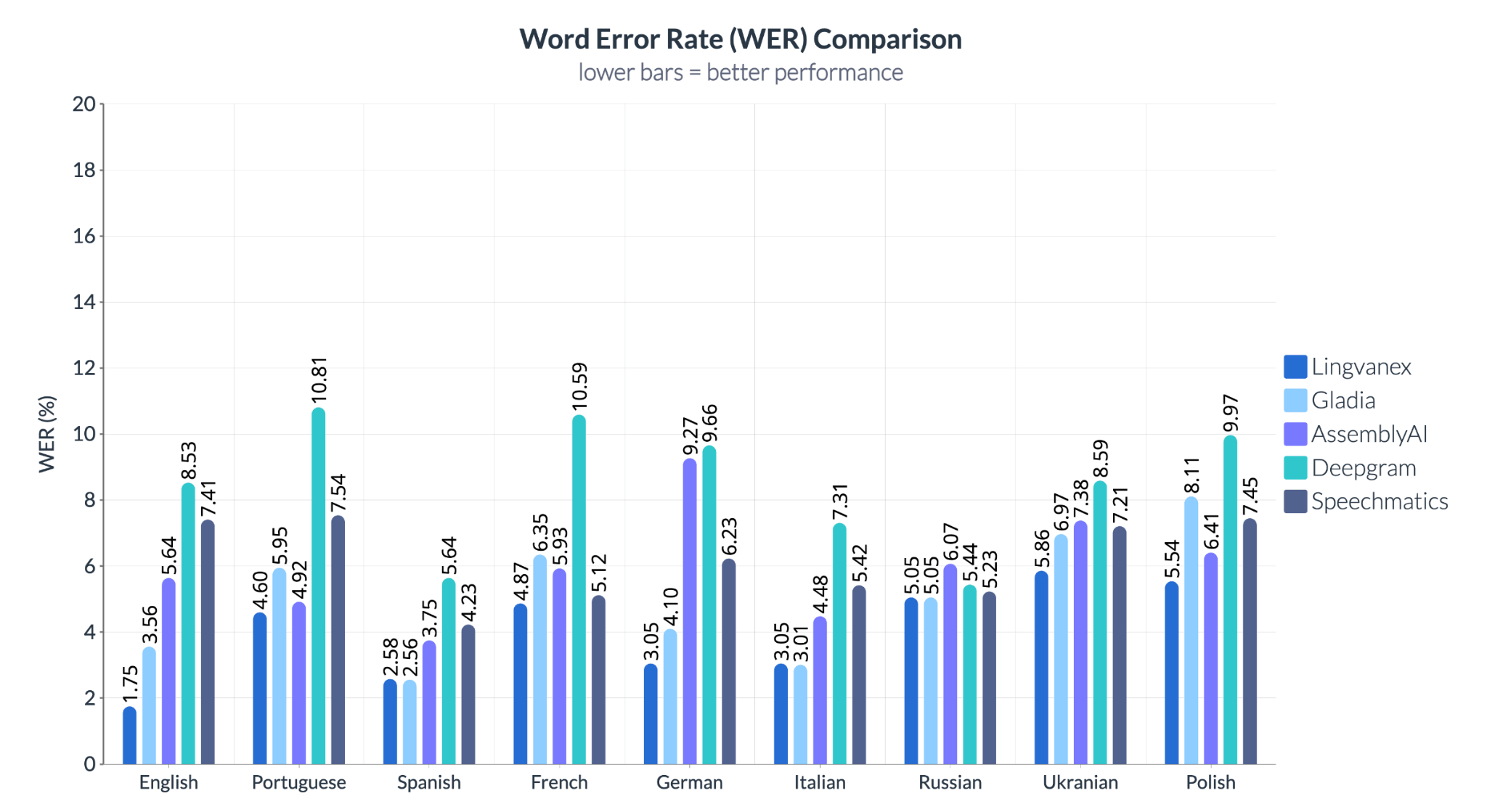
Results show variation in performance across languages and providers. In English, German, and Spanish, Lingvanex demonstrates lower error rates compared to other systems. Differences are also observed in other languages: for example, Deepgram shows higher error rates in Portuguese and French, while Speechmatics exhibits less consistent results in Slavic languages such as Ukrainian and Polish.
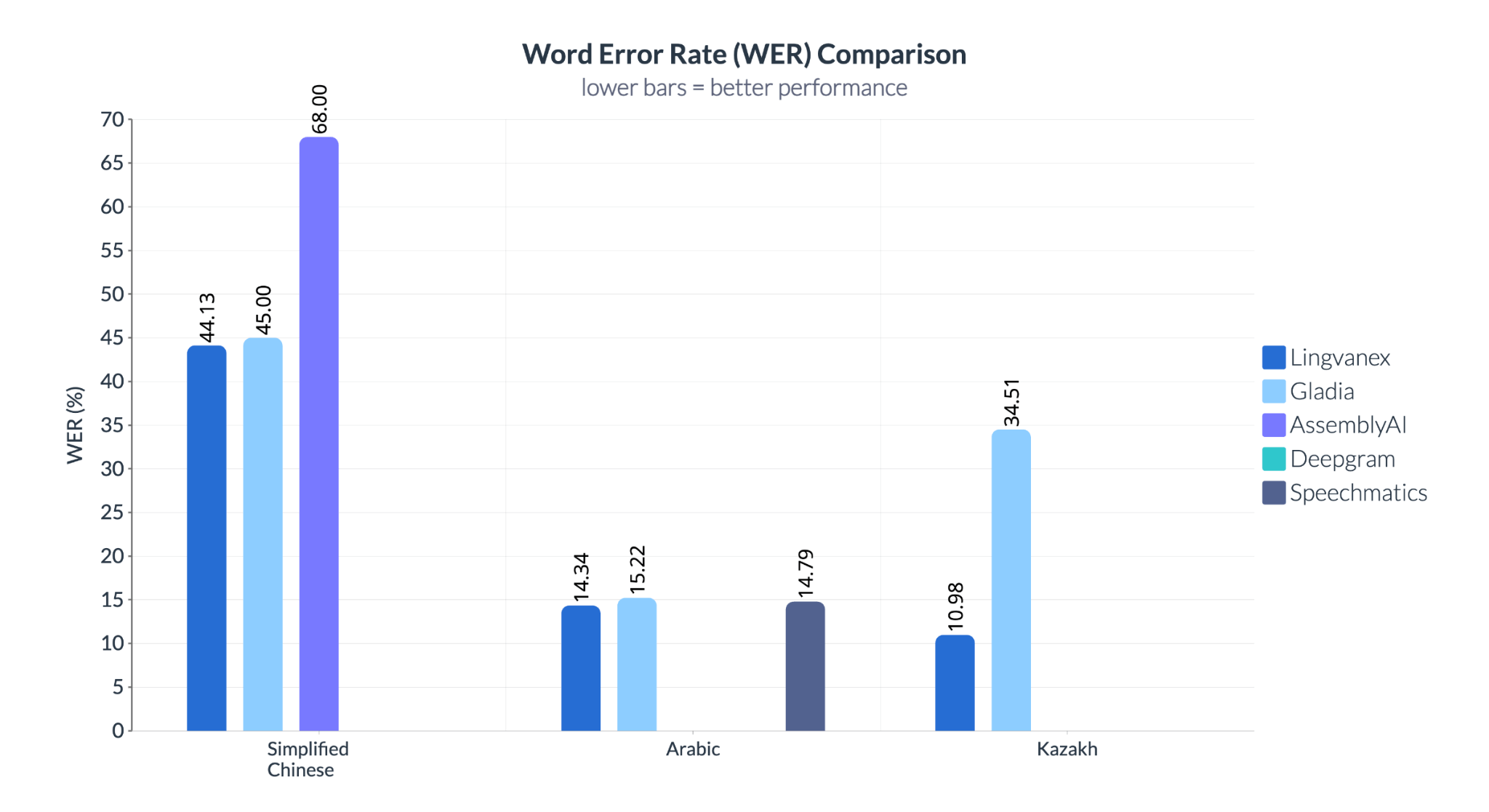
The difference is more pronounced in Kazakh, where Lingvanex shows a Word Error Rate (WER) of 10.98%, compared to 34.51% for Gladia. In Simplified Chinese, Speechmatics records a WER of 68%, while Lingvanex shows 44.13%.
Speech recognition systems used in enterprise environments require consistent performance across multiple languages, accents, and acoustic conditions. For global applications, it is important to evaluate how systems handle linguistic diversity and real-world variability.
The results indicate that performance can differ significantly depending on the language and scenario, highlighting the importance of testing beyond widely supported languages such as English.
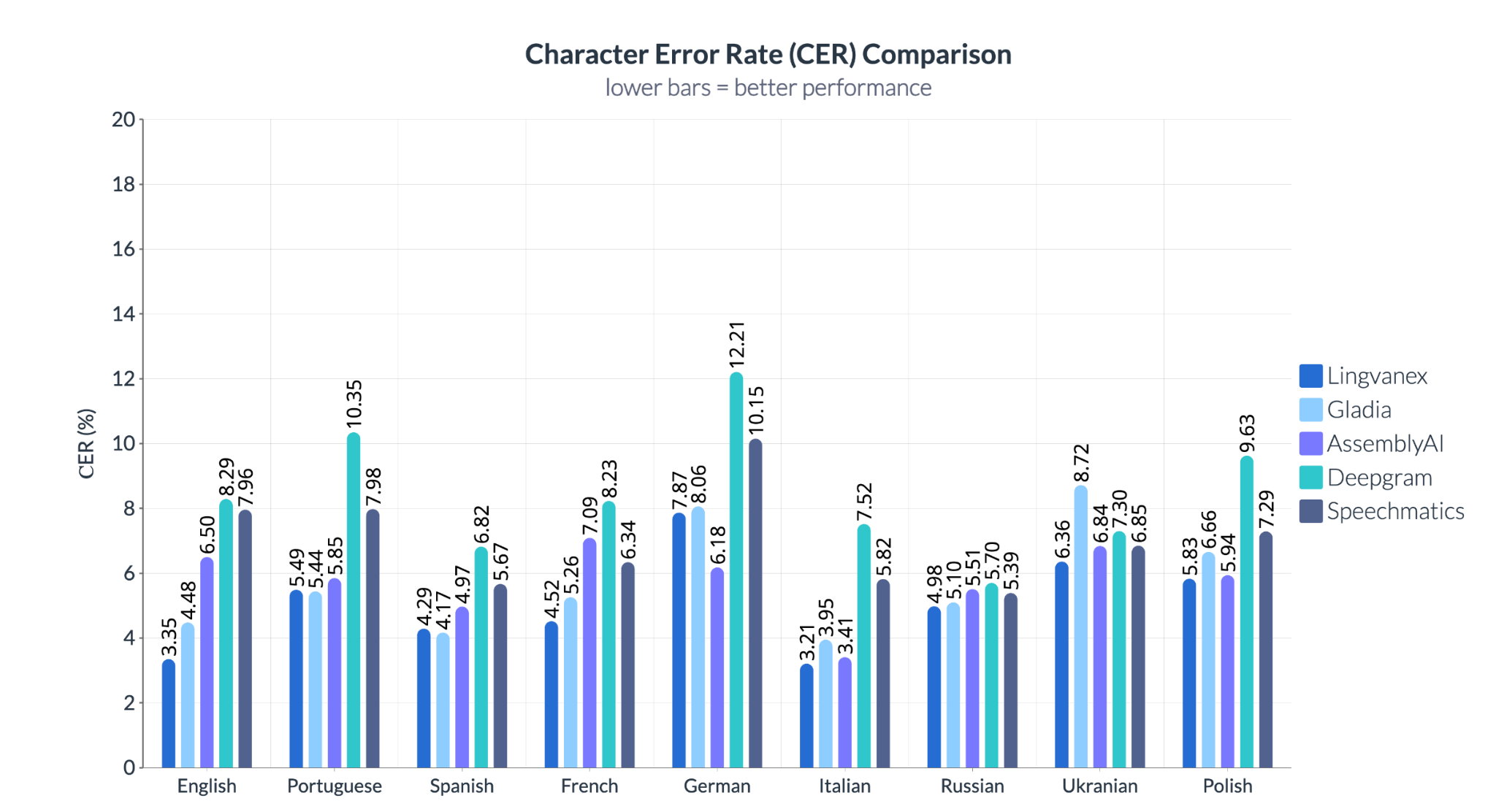
Character Error Rate (CER) results show differences across systems and languages. In Chinese, AssemblyAI records a CER of 13.8%, compared to 7.34% for Lingvanex. In Kazakh, Gladia reaches 13.81%, while Lingvanex shows lower error rates.
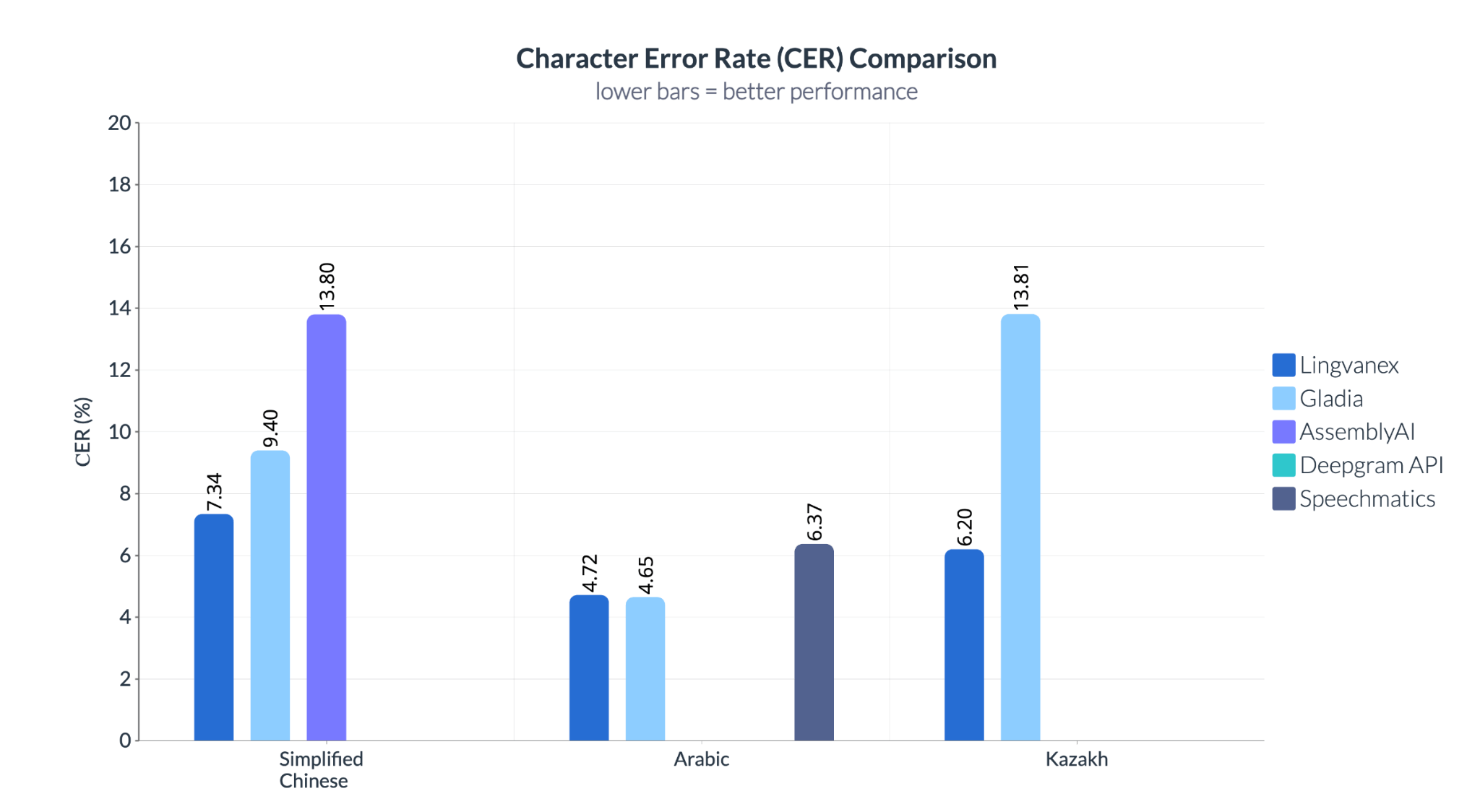
In Chinese, AssemblyAI records a CER of 13.8%, compared to 7.34% for Lingvanex. In Kazakh, Gladia shows a CER of 13.81%, while Lingvanex demonstrates lower error rates. Unlike Word Error Rate (WER), which measures errors at the word level, CER evaluates transcription accuracy at the character level. This makes it useful in scenarios where precise spelling is important, such as names, commands, or domain-specific terminology.
Across both Word Error Rate (WER) and Character Error Rate (CER), the results highlight several patterns:
- Accuracy varies across systems and languages
- Some systems demonstrate lower error rates across both high-resource and lower-resource languages
- Performance differences become more noticeable in multilingual and complex audio conditions
- Variability increases in scenarios with background noise, overlapping speech, and diverse accents
These observations suggest that evaluating speech recognition systems requires considering both accuracy metrics and performance consistency across different real-world conditions.
Lingvanex Speech Recognition: Deployment and Capabilities
Unlike cloud-only APIs that treat STT as a siloed service, Lingvanex offers a full-stack solution: speech recognition, translation, and language routing – all customizable and deployable on your terms.
Key characteristics include:
- Language Coverage. The solution supports speech recognition across 90+ languages, depending on the selected models and configuration.
- Customization Options. The system supports adaptation for domain-specific vocabulary and use cases, including scenarios with specialized terminology and compliance requirements
- Lightning-Fast Data Processing. According to internal testing, one minute of audio can be processed in approximately 3.44 seconds.
- Automation of Transcription Workflows. Speech-to-text processing can reduce the need for manual transcription in certain use cases.
- Support for Diverse Speech Conditions. The system is designed to handle variations in accents, speech patterns, and multi-speaker environments
- Cost Considerations. Automation and processing speed may reduce reliance on manual transcription and related operational costs
- Integration Options. The solution is available via API and SDK, allowing integration into existing systems and workflows. It can be deployed and used on desktop environments, including macOS and Windows, as well as on mobile platforms such as Android and iOS.
- Supported Audio Formats. The system supports multiple audio formats, including WAV, MP3, OGG, and FLV.
- Deployment and Data Security. On-premise deployment is available for environments with specific data protection and compliance requirements. The solution can be deployed entirely within the client’s infrastructure, allowing full control over data processing and storage.
- File Size Handling. The system is designed to process large audio and video files without strict size limitations, depending on deployment configuration.
- Timestamps. The system provides timestamps for recognized speech, enabling alignment between audio segments and transcribed text.
- Speaker Diarization. The solution supports speaker separation, allowing identification of different speakers within a conversation
- Real-Time Processing. Speech recognition can be performed in real time, supporting use cases such as live transcription and streaming audio.
- Subtitle Generation. The system supports automatic subtitle generation based on speech recognition output, enabling use in video content processing and media workflows
- Integration with Machine Translation. The system can be integrated with Lingvanex On-premise Machine Translation, enabling combined speech recognition and translation workflows in 100+ languages within a controlled infrastructure environment.
How to Choose a Speech Recognition API for Business Use
When selecting a speech recognition solution, consider the following questions:
- How accurate is the system in real-world conditions?
- What are the Word Error Rate (WER) and Character Error Rate (CER) for the target language?
- Which languages are supported, and how consistent is performance across them?
- Does the system support accents, dialects, and multilingual or mixed-language speech?
- How does the system handle background noise, overlapping speech, and unclear pronunciation?
- Does it support real-time processing, batch processing, or both?
- What is the recognition latency in real-time scenarios?
- Does it support streaming speech recognition?
- What deployment options are available: cloud, on-premise, or hybrid?
- Can the solution be deployed entirely within a private infrastructure?
- What are the CPU, GPU, and memory requirements?
- Does the system support hardware acceleration such as GPU or NPU?
- On which operating systems and platforms can it run?
- Are APIs or SDKs available for integration?
- Which audio and video formats are supported?
- Are there limitations on audio or video file size or duration?
- Can the system be customized for domain-specific terminology or workflows?
- Does it support custom vocabularies, user dictionaries, or language model adaptation?
- Are specialized models available for domains such as healthcare, legal, or customer support?
- Does it support speaker diarization, timestamps, subtitle generation, or keyword spotting?
- How many concurrent streams or requests can it handle?
- Is the processing fully local, or does it require an internet connection?
- Are audio files or transcripts stored, logged, or used for further training?
- Can data collection or logging be disabled?
- Can the system be tested on your own data before adoption?
Conclusion
The results show that speech recognition performance varies depending on language, audio conditions, and system design. Accuracy measured in controlled environments does not always reflect real-world performance, especially in multilingual and noisy scenarios.
Evaluating ASR systems requires looking beyond aggregate metrics such as Word Error Rate (WER). Additional factors, including character-level accuracy, consistency across languages, and behavior in complex audio conditions, play an important role in practical use.
The comparison also indicates that system capabilities differ across providers, particularly in less common languages and real-world use cases. This highlights the importance of selecting solutions based on specific requirements, including language coverage, deployment model, and integration needs.
Overall, speech recognition should be assessed as part of a broader workflow, where accuracy, stability, and adaptability directly affect downstream applications and business processes.


