
The goal of this report is to showcase the translation quality of Lingvanex language models according to two most popular machine translation evaluation metrics. Flores is an open-source and publicly available data test set that was released by Facebook Research and has the biggest language pair coverage.
Quality metrics description
BLEU
BLEU is an automatic metric based on n-grams. It measures the precision of n-grams of the machine translation output compared to the reference, weighted by a brevity penalty to punish overly short translations. We use a particular implementation of BLEU, called sacreBLEU. It outputs corpus scores, not segment scores.
References
- Papineni, Kishore, S. Roukos, T. Ward and Wei-Jing Zhu. “Bleu: a Method for Automatic Evaluation of Machine Translation.” ACL (2002).
- Post, Matt. “A Call for Clarity in Reporting BLEU Scores.” WMT (2018).
COMET
COMET (Crosslingual Optimized Metric for Evaluation of Translation) is a metric for automatic evaluation of machine translation that calculates the similarity between a machine translation output and a reference translation using token or sentence embeddings. Unlike other metrics, COMET is trained on predicting different types of human judgments in the form of post-editing effort, direct assessment, or translation error analysis.
References
- COMET - https://machinetranslate.org/comet
- COMET: High-quality Machine Translation Evaluation - https://unbabel.github.io/COMET/html/index.html#comet-high-quality-machine-translation-evaluation
On-premise Private Software Updates
New version - 1.22.0.
Changes in functionality:
- Add support for audio in video files for Speech Recognizer.
New version - 1.21.1.
Changes in functionality:
- Fixed speech recognition in *.wma and *.flv files.
Improved Language Models
BLEU Metrics
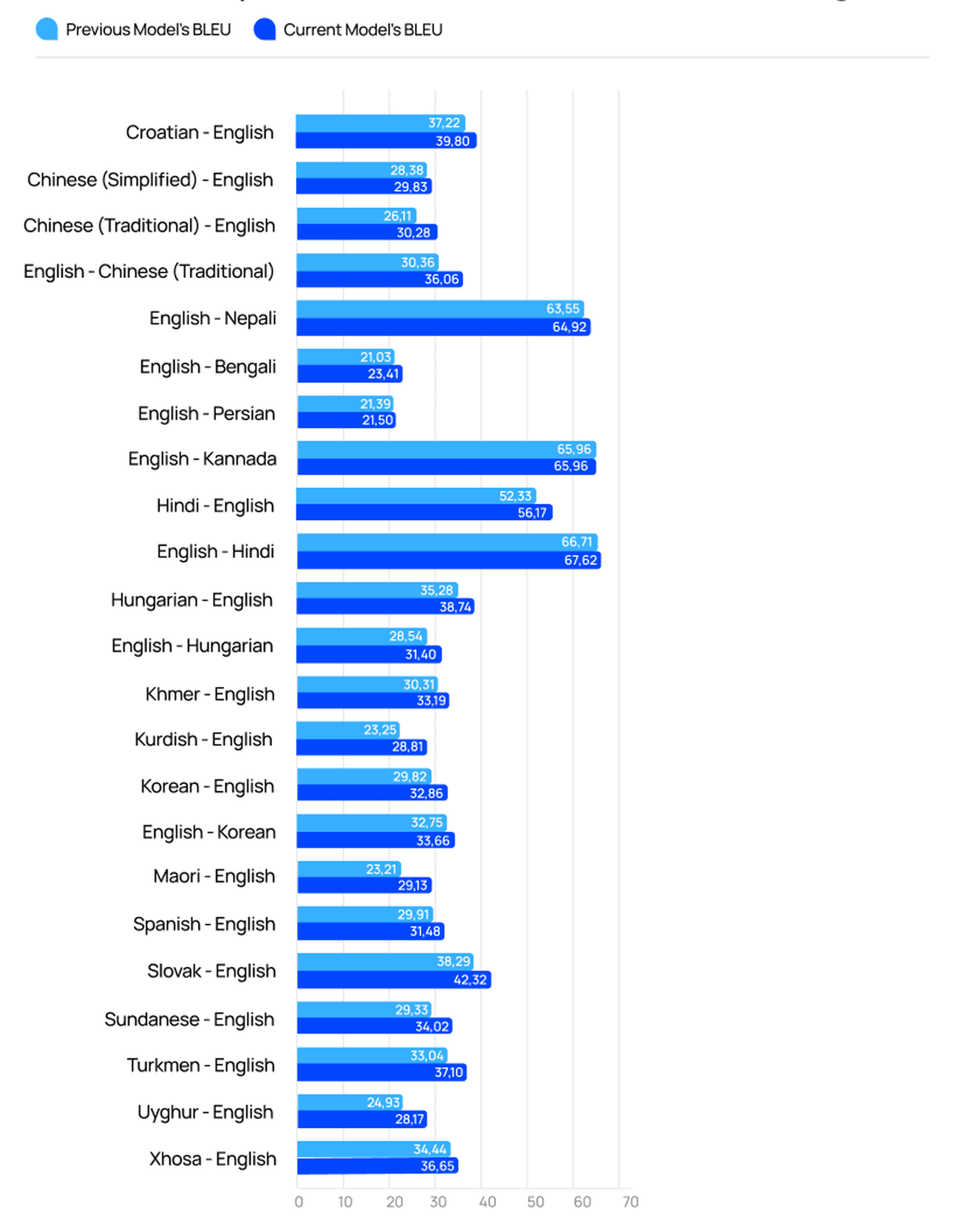
Improved Language Models. March 2024
COMET Metrics
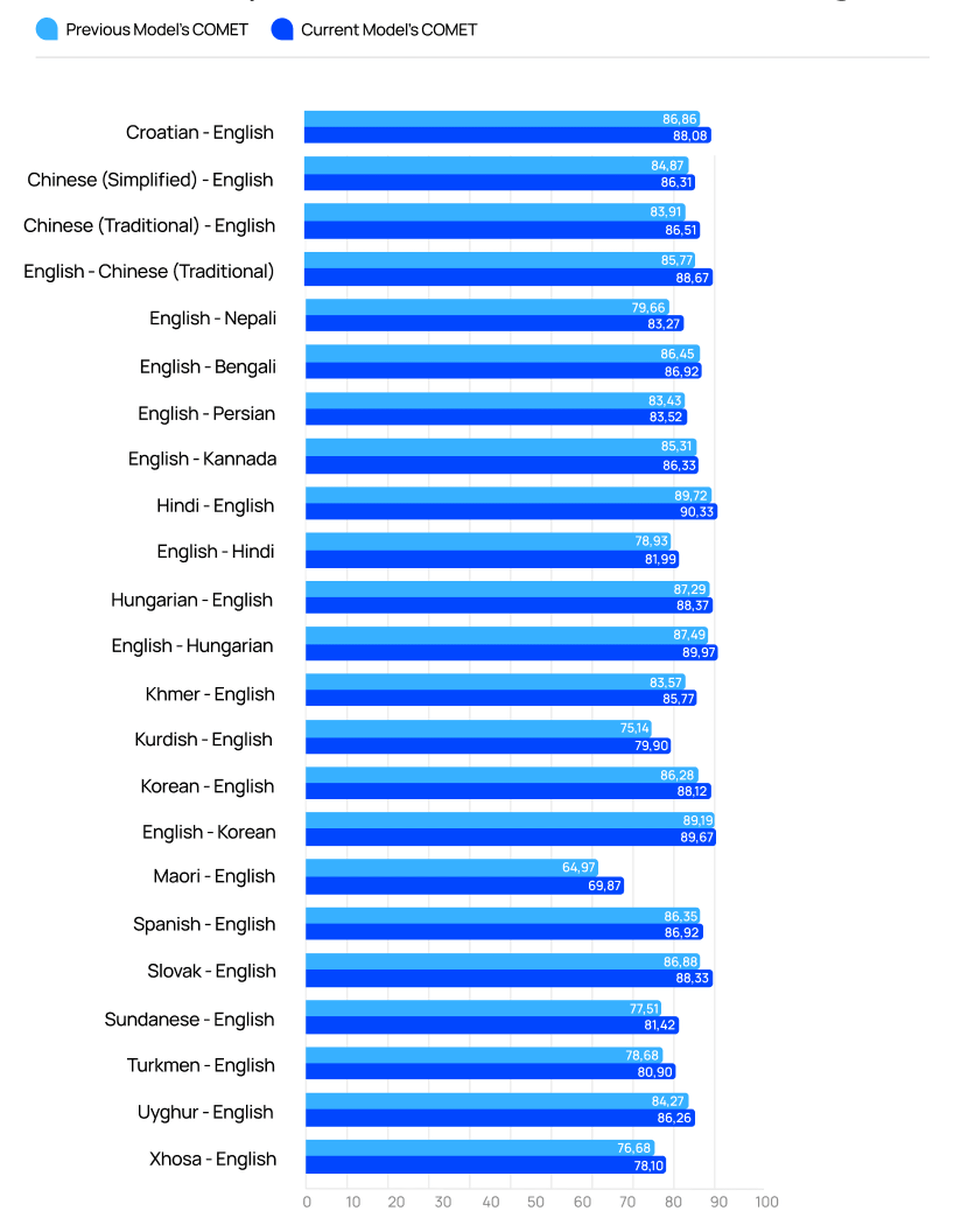
Improved Language Models. March 2024
Language pairs
Note: The lower size of models on the hard drive means the lower consumption of GPU memory which leads to decreased deployment costs. Lower model size has better performance in translation time. The approximate usage of GPU memory is calculated as hard drive model size x 1.2
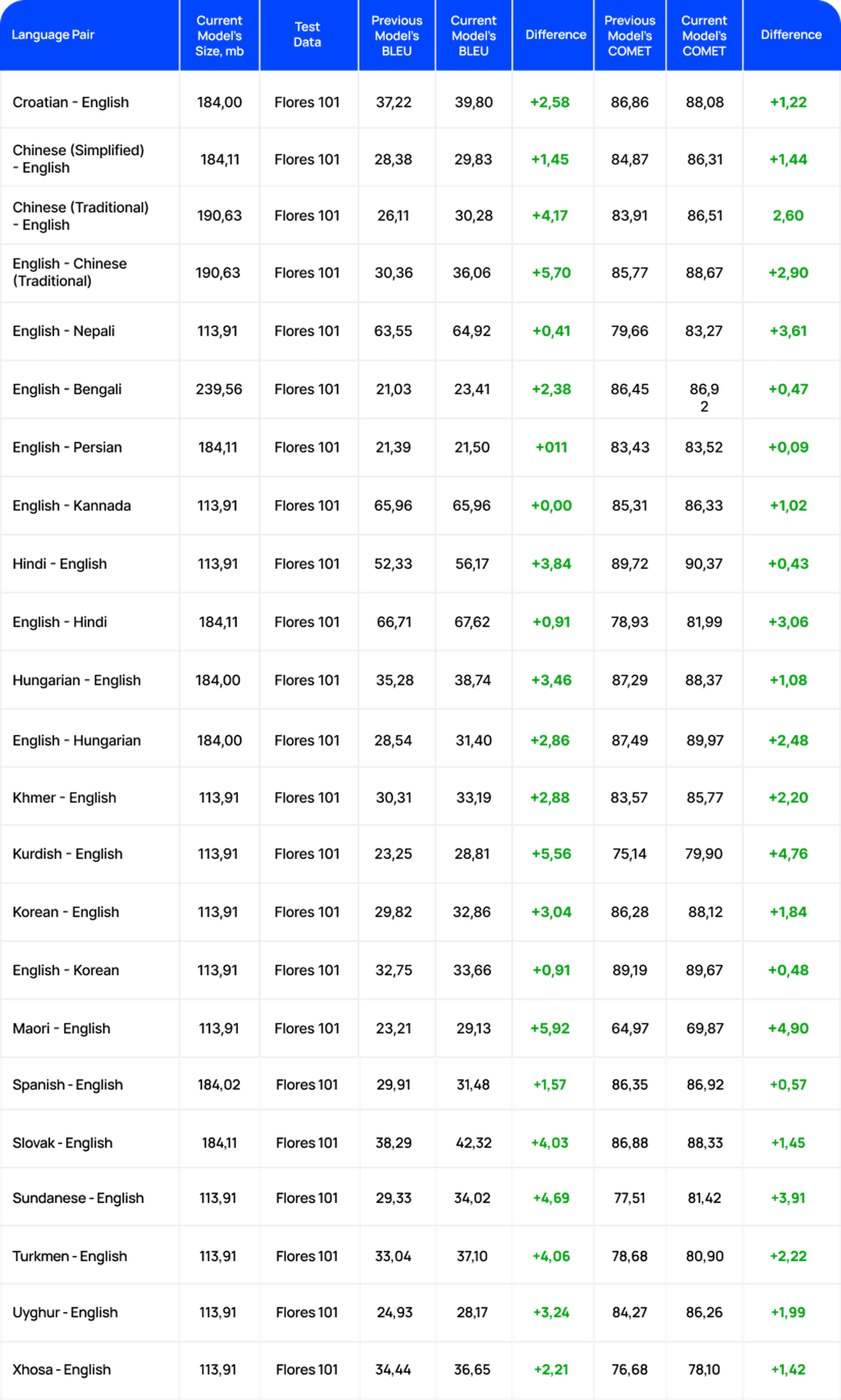
Conclusion
The Lingvanex machine translation models have been evaluated using two popular automatic evaluation metrics - BLEU and COMET. BLEU measures the precision of n-grams in the machine translation output compared to reference translations, while COMET calculates the similarity between the machine translation and reference using embedding- based techniques. The report showcases the translation quality of the Lingvanex models across a wide range of language pairs from the publicly available Flores dataset. The models demonstrate strong performance according to these industry-standard evaluation metrics. Some key advantages of the Lingvanex models noted are:
- Smaller model size leading to lower GPU memory consumption and faster translation times
- Continuous improvements in the language models over successive software updates
Overall, the results indicate that the Lingvanex machine translation models provide high-quality translations that meet or exceed the performance of other leading MT systems. The use of robust evaluation metrics provides confidence in the reliability and accuracy of the Lingvanex translation capabilities.



