
Lingvanex has been developing machine translation solutions for over seven years. Every month, we process billions of rows of data in over 100 languages to train language models that deliver exceptional performance. But how do we manage to consistently support such a wide range of languages while improving translation quality month after month?
In this article, I will share insights from our research and the tools that contribute to our success. Also we will look at a powerful tool designed to improve the quality of text translation. We will discuss how this tool helps in preparing data, training translation models, and testing their performance. By breaking down the steps involved, we aim to provide a clear understanding of how language translation can be improved through systematic processes.

Key information about Data Studio
Data Studio is a tool for working on NLP tasks, which is necessary to improve the quality of text translation. Using Data Studio, you can train language translation models, configure various parameters for these trainings, tokenize data, filter data by various parameters, take metrics, create training, test and validation data, etc.
The general process of creating a language model is as follows:
Data preprocessing: the stage of data preparation before training the model.
Filtration with structural and semantic filters.
Collecting a common dataset: removing redundancy, evenly distributing topics and lengths, sorting.
Tagging for data classification.
Loading a common dataset into Data Studio for verification.
Creating data for validation and testing the model.
Training the model.
Conducting quality tests: structural and semantic, measuring metrics.
Detecting errors in translations, analyzing errors in datasets, correcting them and supplementing with a translated mono-corpus if necessary.
Repeat stage of collecting a common dataset.
Data Preparation
To create a language model for text translation, 3 types of data are required:
1) Training dataset or learning dataset
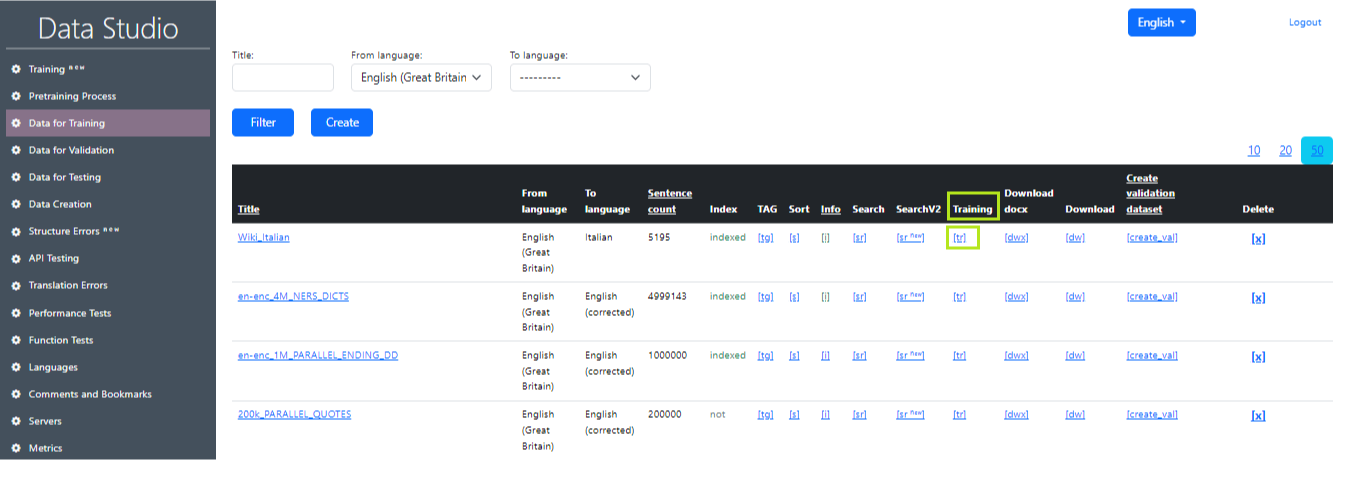
A dataset that is used to train a language model. These are pairs of sentences in different languages (source and target). You can use several training datasets at the same time when training a model. It is important to take into account the consistency of the format and structure of the data so that the model can correctly use information from all training datasets. This working window displays the prepared large-volume Data-sets (dataset) on which the AI model is trained for translation. An example of the “Training data” working screen in Data Studio is shown in Image 1.
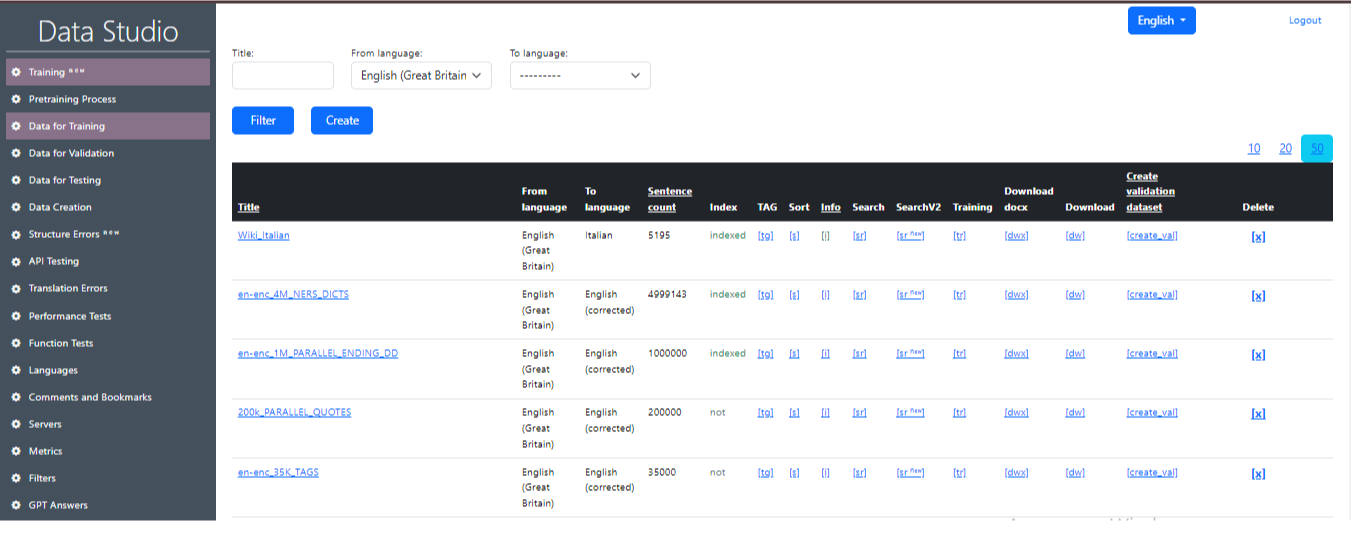
Description of values in the “Training Data” table:
- Title: Title defining the name of the entry.
- From language: Language from which the translation is made.
- To language: Language to which the translation is made.
- Sentence count: Number of entries (sentences) in the file.
- Index: Displays whether the Data Set is indexed or not (to get quick access to it).
- Tag: Replaces a certain percentage of numbers in the dataset with <tag>. It is necessary for the logic that marks words that should not be translated (when the model is trained). The percentage of tag replacement is set in the Settings. When the replacement occurs, a new dataset is created with a name (tag) at the end.
- Sort: Sorts the dataset by the number of words in the sentence and alphabetically, so that it is then convenient to look at it with your eyes for analysis. When the replacement occurs, a new dataset is created with a name (sorted) at the end.
- Info: Provides information about the dataset.
- Search: Search for specific words and phrases in the dataset. This functionality is needed to find sentences with incorrect translation in the dataset. For example, where cat is translated as “dog”.
- Training: Moves the dataset to the Training page.
- Download: Downloads the archive with the dataset to your computer in.txt format.
- Download_doc x: Downloads the archive with the dataset to your computer in.docx format.
- Create validation dt: Creates a validation file from the training data. Parameters are set in Settings.
- Delete: Deletes the record.
2) Validation dataset
This dataset is used to evaluate the performance of the model during training. It helps optimize the model parameters and prevents overfitting by allowing us to evaluate how well the model generalizes to data it has not seen during training.
For example, let's say we have English sentences and their corresponding French translations. The training dataset will contain these sentence pairs, where the English sentence will be the input and the French translation will be the target. The model will be trained on this dataset, trying to predict the correct French translations for the English sentences. After training the model on the training data, we want to evaluate its performance on new data. To do this, we use the validation dataset, which also contains pairs of English sentences and their French translations. We feed the English sentences from the validation dataset to the model and compare its predictions with the real French translations from this dataset. This allows us to assess how well the model generalizes to data it has not seen before.
Using training and validation datasets helps create more accurate and generalizable language translator models that can effectively translate new sentences into other languages. An example of the “Validation data” working screen in Data Studio is shown in Image 2.
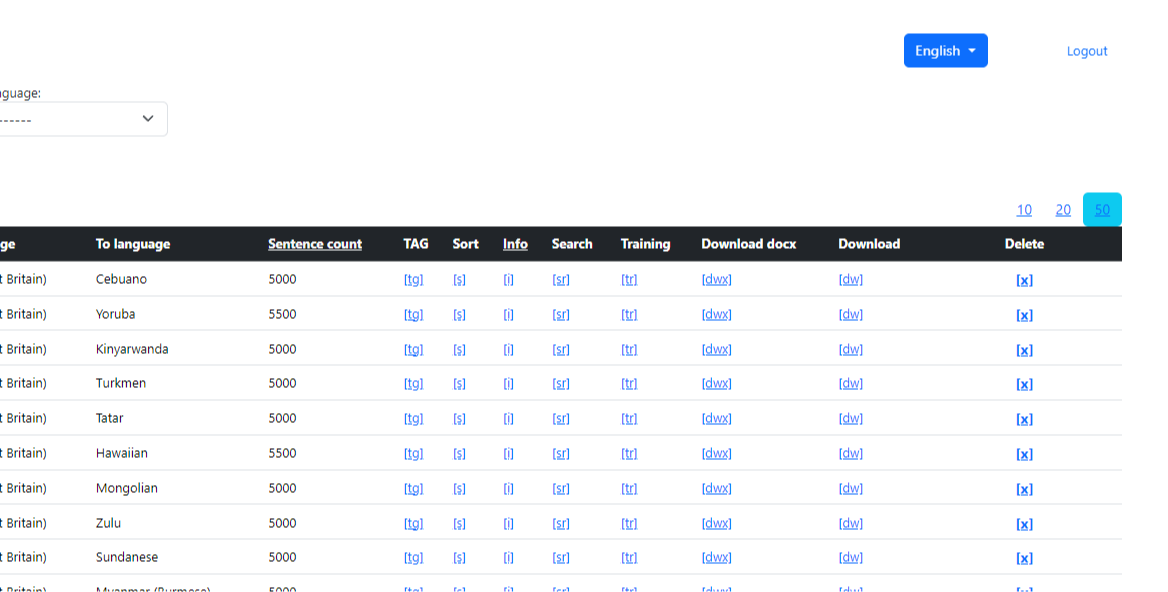
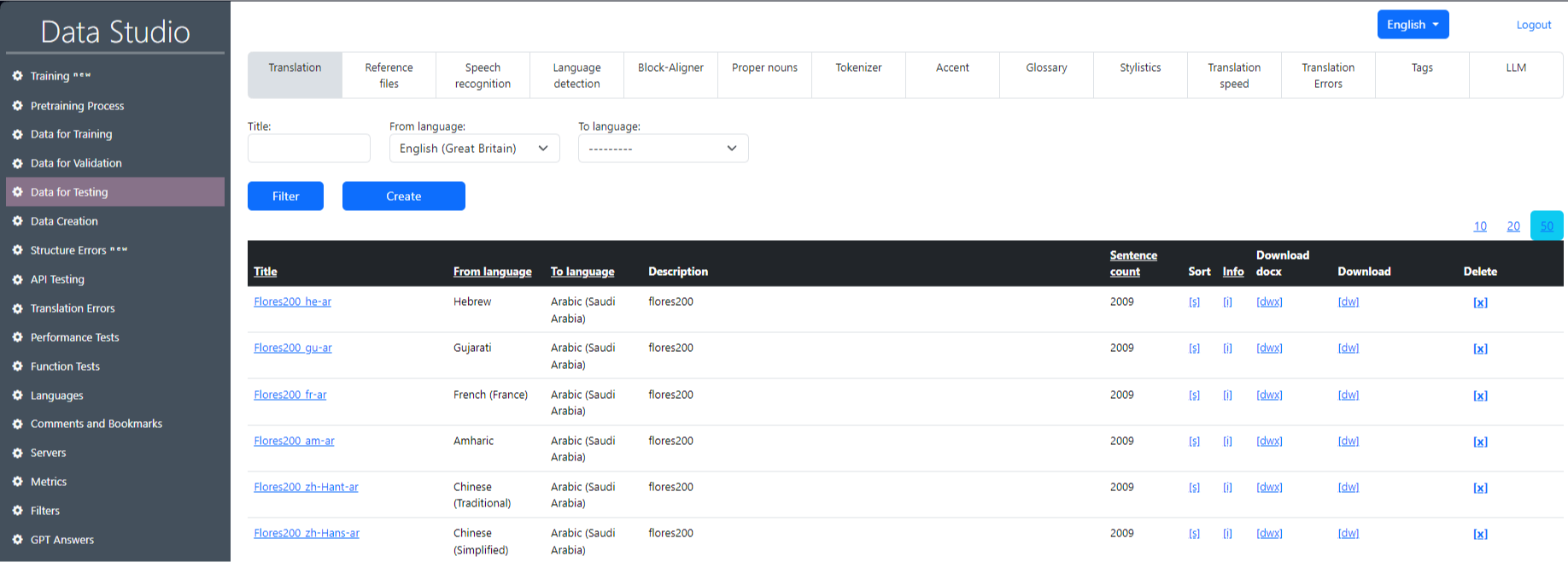
3) Testing Dataset
This dataset is necessary for testing the quality of trained models, using the files stored in it, divided into tabs. Once the model and hyperparameters are finalized using the training and validation sets, the test set is used to evaluate the performance of the model. An example of the “Testing data” working screen in Data Studio is shown in Image 3.
Pre-training process
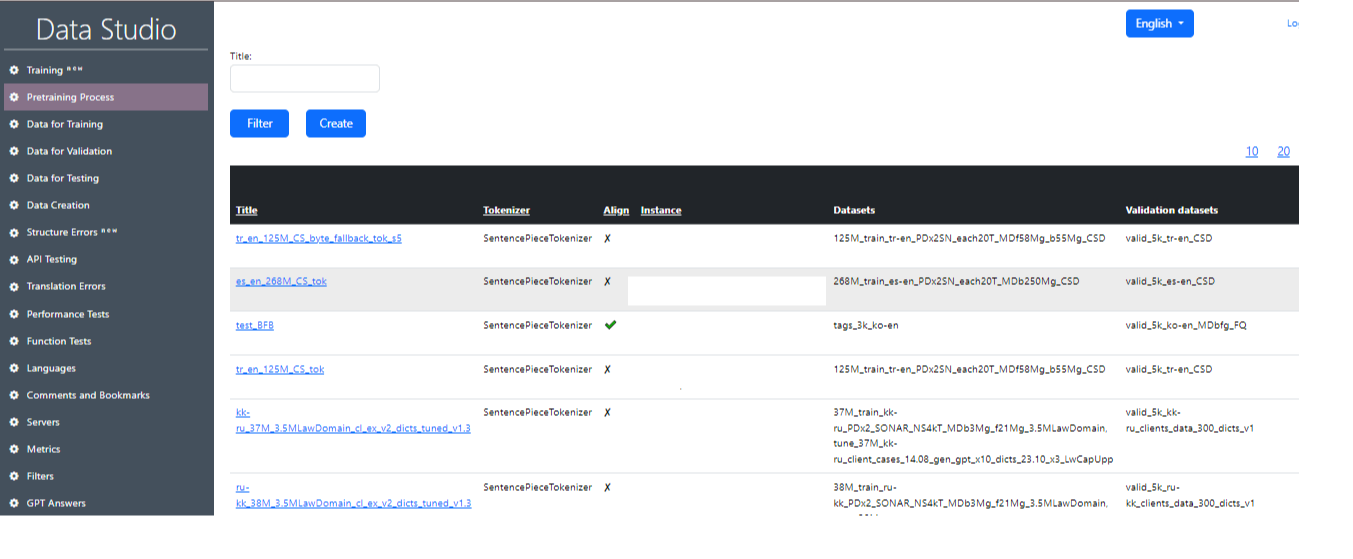
Previously, tokenization and model training processes were performed simultaneously, which resulted in GPU idle time (server rental is paid regardless of whether the model is being trained or not) while waiting for tokenization to complete on the CPU. To optimize resource usage, a “Pre-training process” was developed. Now tokenization is performed separately from training, which allows models to be trained on the GPU without interruptions. An example of the “Pre-workout process” working screen in Data Studio and one of the variance of pre_trained tasks are shown in Image 4 and Image 5.
The quality of the translation of the trained model depends on:
- Training data;
- Set parameters for the neural network during training;
- Inference parameters;
- Text formatting before it goes to the neural network (breaking long sentences into short pieces and gluing translations together later, bringing different quotation marks and other symbols to standard ones).
Procedure for conducting the “Pre-training process”
In order to perform tokenization, you need to do the following:
Click “Create” on the main window of the “Pre-training process” section (Image 6);

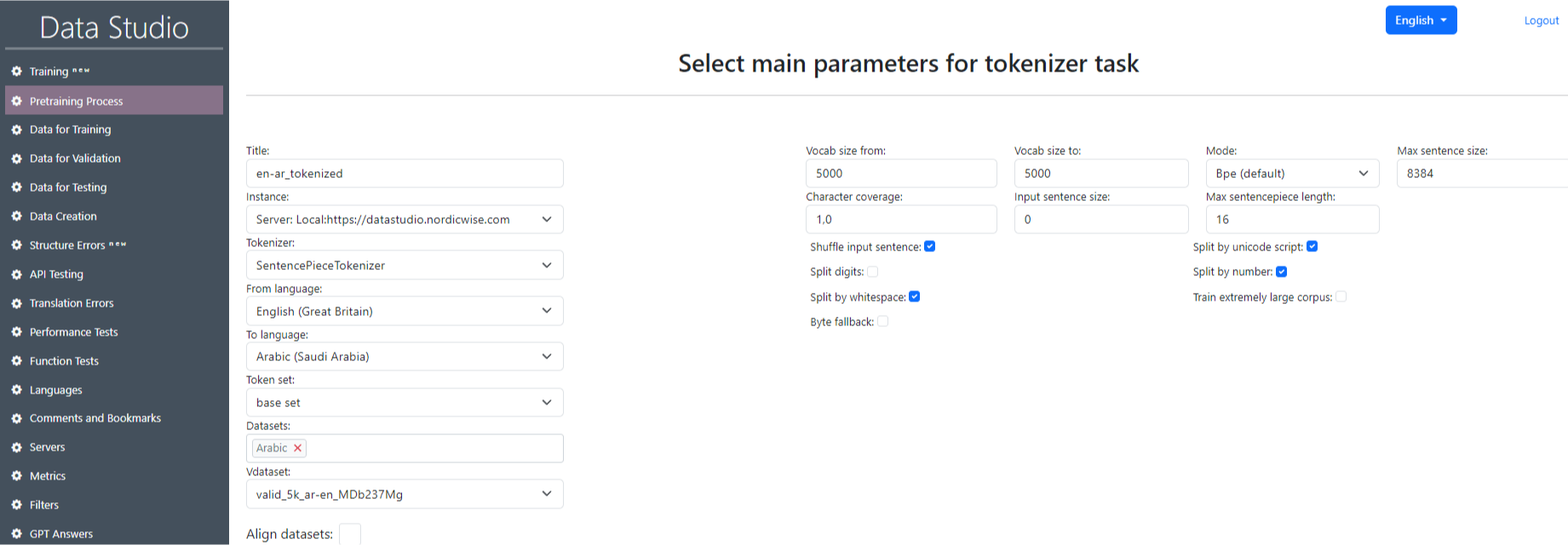
On the opened page “Select main parameters for tokenizer task” fill in all the fields using tables 3.1 “Tokenization parameters”, 3.2 “SentencePieceTokenizer tokenization parameters” and 3.3 “OpenNMTTokenizer tokenization parameters”. Click “Submit”. After that, the task we created will be displayed in the table on the main page of the section.
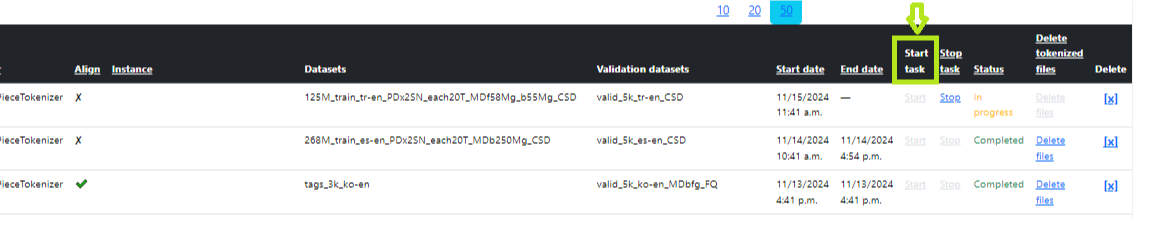
In the table on the main page of the section, find the task we created and click “Start” opposite our task (Image 7 - Start of tokenization). After launch, the status will be “In_queue”, a little later - “Started”, upon completion - “Completed”. You can launch several tokenization processes at once. In this case, after creating, click “Start” for each. All tasks must be placed in the queue (In queue) and are executed sequentially one after another. After launch, all will have the status “In_queue”. Upon successful execution, the status will be sequentially updated to “Completed”. After successful tokenization, the dataset will be available for selection in the “Pretraining data” field in the “Training V2” section.
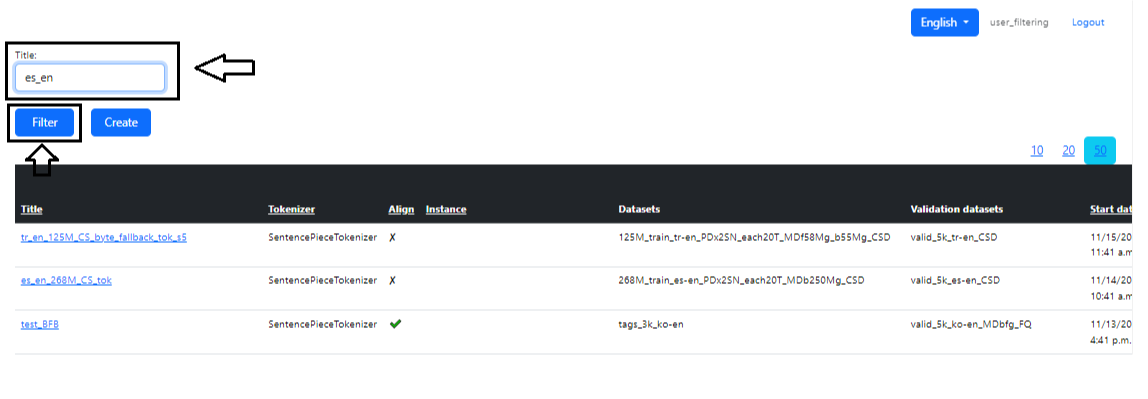
On the main page of the section there is a search for the task we need. To do this, you need to type the task name or part of it in the “Name” field and click “Filter”. You can also sort in the table itself by clicking on the column names (Image 8 - Search).
To delete a task, you need to click on the cross in the “Delete” column opposite the task you need (Image 9 - Deletion).

Training
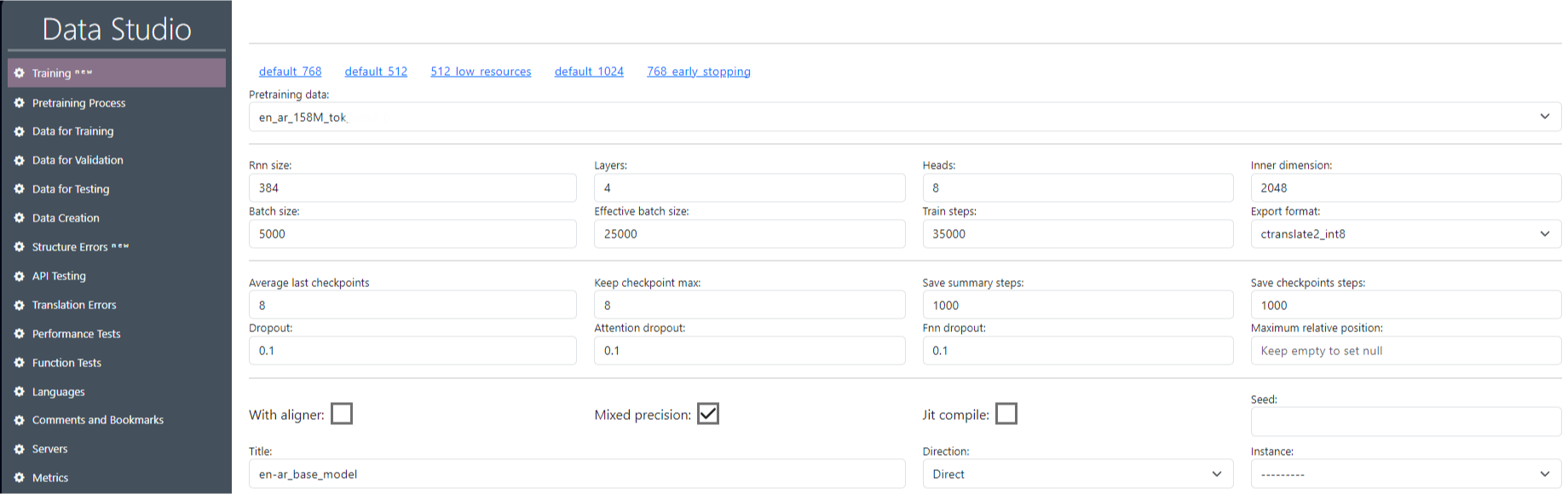
Each training creates a model for one translation direction, for example English-French. To make a translator, for example from Russian to English, you need to train in the other direction. If we make a translation model from English to language X, in the Direction parameter - specify "Direct", if from language X to English, then in the Direction parameter - specify "Reverse". The first and second languages are not necessarily English, directly - simply indicates that the choice of languages From and To goes from left to right. Before starting the training, you need to set the parameters for this training (Image 10).
To perform a training session, you need to do the following:
Add training data. Click on “tr” (Image 11) in the row of the dataset we need in the “Training data” table. After that, the dataset will be available for selection in the “Training” section.
Add data for validation. Click on “tr” (Image 12) in the row of the required validation dataset in the “Validation data” table. After that, the validation dataset will be available for selection in the “Training” section.
In the “Training” section, specify all the necessary parameters (SentencePieceTokenizer and OpenNMT Tokenizer tokenization parameters and Model parameters), as well as “Title” (the name of our training).
Select the necessary training and validation datasets.
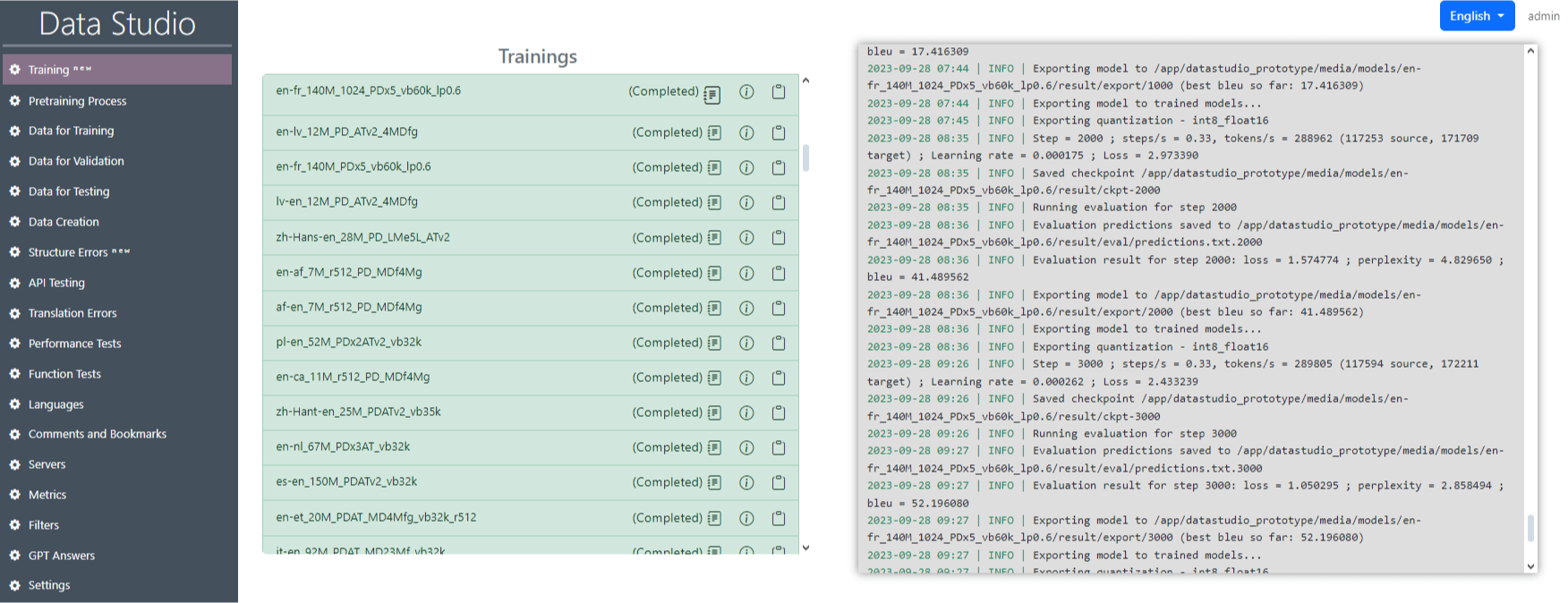
Click on the “Create and Run” button (Image 13). After that, the training will start and records will start appearing in the logs (Image 14).

Testing
There are two special sections in Data Studio for tracking translation quality: API Testing and Structure Errors. Let's consider each of them in more detail
API Testing
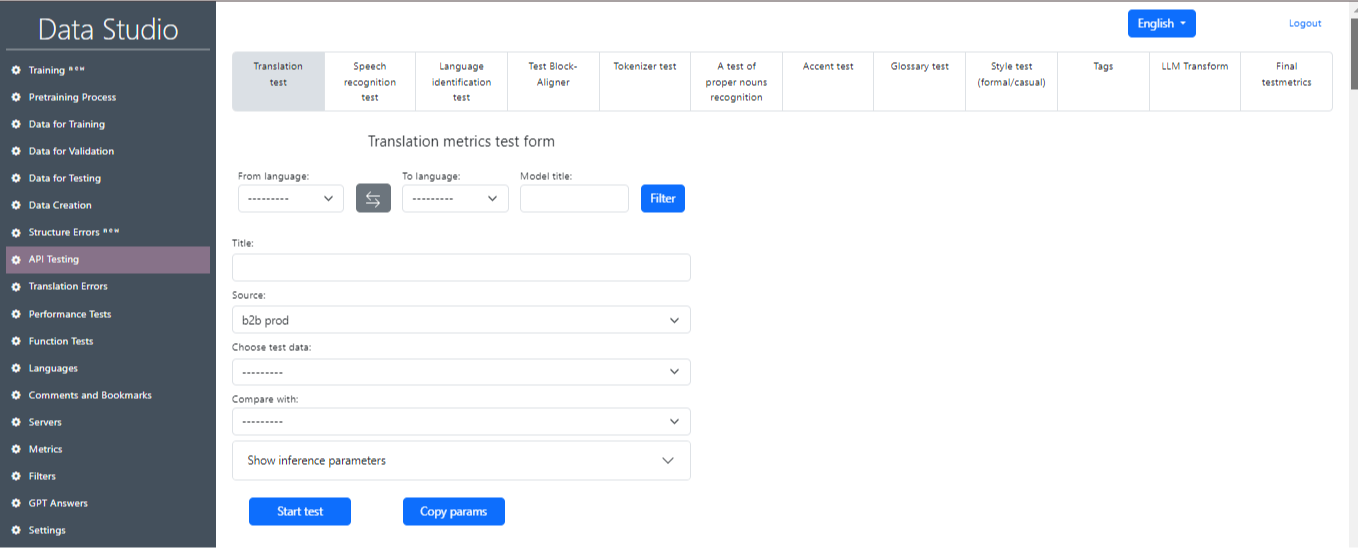
The API Testing section is intended for testing the trained model according to such units as translation test, speech recognition test, language identification test and others (Image 15). It is also possible to obtain a summary table of the final test metrics.(Image 16).
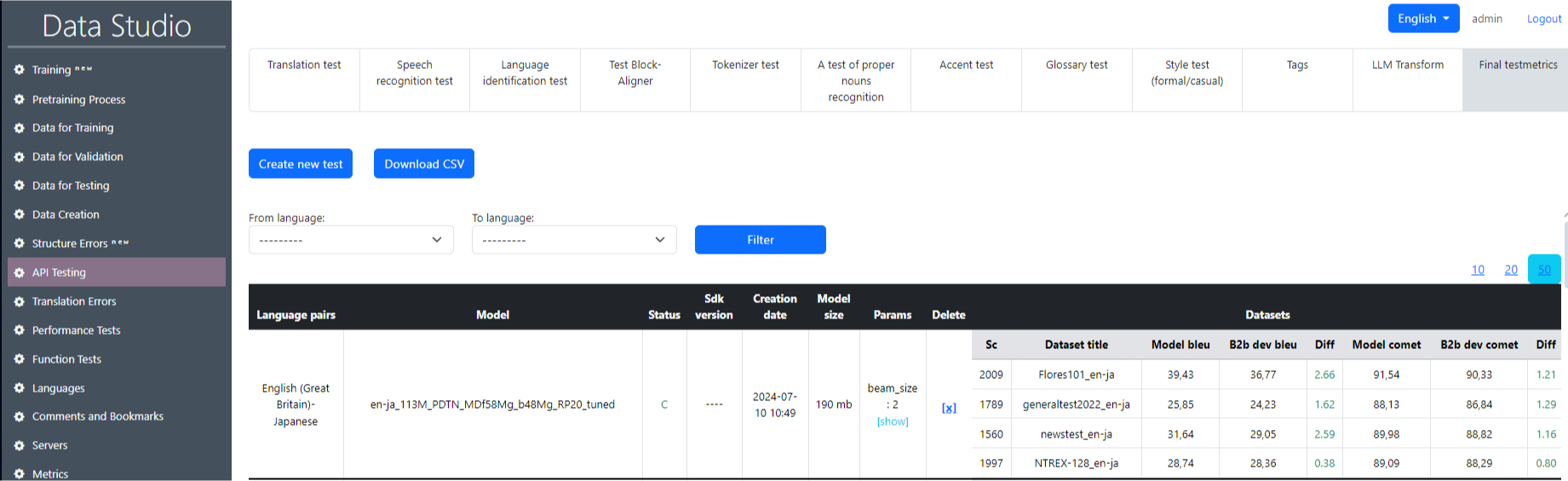
Here's a breakdown of what each column and metric in this section represents:
- Date: The timestamp when each test was run.
- From/To Language: The source and target languages for translation testing.
- Status: Indicates the status of the translation test (all are marked as Completed).
- Model: The specific model used for translation (some fields are blank, implying unspecified models).
- Test Dataset: The dataset used for testing, such as "flores200", "ntrex-128", or others that represent different collections of data for language translation testing.
- Number of Sentences: The number of sentences in the test dataset.
- Server: The server name used to run the test.
- BLEU: A metric that evaluates translation quality by comparing machine-translated text to one or more reference translations. Higher BLEU scores generally indicate higher quality translations.
- BLEU ref: The BLEU reference score, possibly indicating a perfect or previous benchmark score.
- BLEU diff: The difference between the current BLEU score and the benchmark score, shown in green (positive difference) or red (negative difference).
- COMET: Another translation quality metric, potentially more context-sensitive than BLEU.
- COMET ref: The COMET reference score.
- COMET diff: The difference in the COMET score relative to the benchmark.
- Translation Time: The time it took to complete the translation, probably in seconds.
- Delete: Ability to delete the test record.
The first diff outputs the BLEU score, the second outputs the COMET score. BLEU and COMET are metrics used to evaluate the quality of machine translation:
- BLEU: a statistical metric that measures the overlap of n-grams (word sequences) between machine translations and reference translations. It is simple, fast, and widely used, but does not take synonyms or context into account.
- COMET: a neural metric that uses deep learning to evaluate translations by comparing the source, reference, and candidate. It better captures meaning and context, more closely matching human judgment, but is computationally expensive.
The file with the conducted testing looks like this (Image 17). The interface provides a breakdown of translation quality between different versions of translations for individual sentences within the dataset. Here’s an explanation of the elements on this screen:
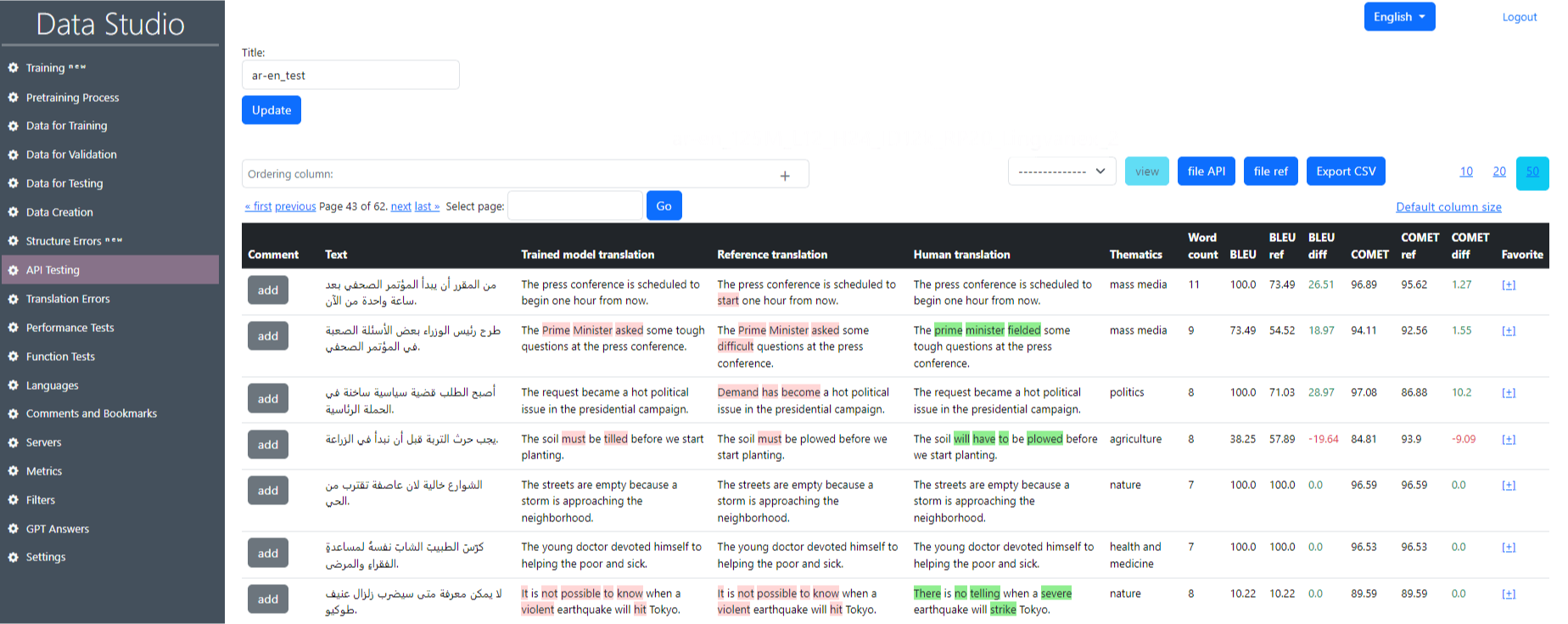
- Comment: The ability to add a description.
- Text: this is the original text that was sent for translation.
- Reference translation: the result of the API/Reference file model.
- Human translation: translation made by a human.
- Thematics: translation topic.
- Word count: the number of words in a sentence.
- BLEU: evaluation metric.
- BLEU ref: ref. file evaluation metric.
- BLEU diff: difference between metric BLEU ref and BLEU.
- COMET: evaluation metric.
- COMET ref: ref. file evaluation metric.
- COMET diff: difference between metric COMET ref and COMET.
Structure Errors
The main page of the Structural Errors section is shown in Image 18 and carries a few extra compartments:
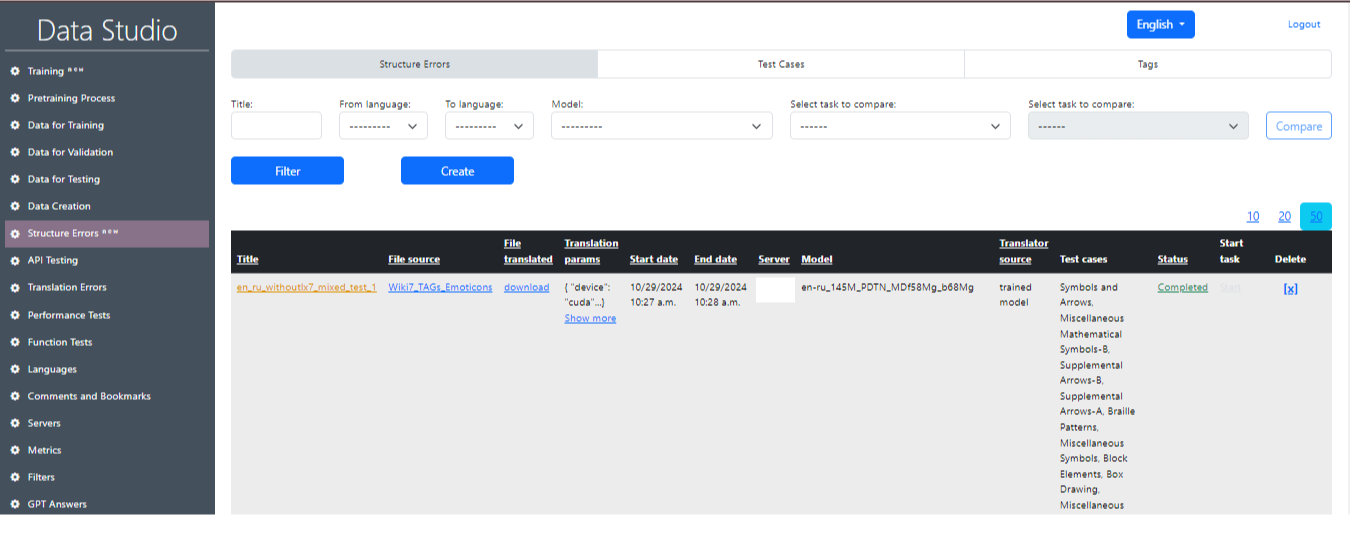
1) Structure Errors:
- Title: This field allows you to enter a title for the structure errors.
- From language: This dropdown lets you select the source language.
- To language: This dropdown lets you select the target language.
- Model: This dropdown allows you to select the model to be used.
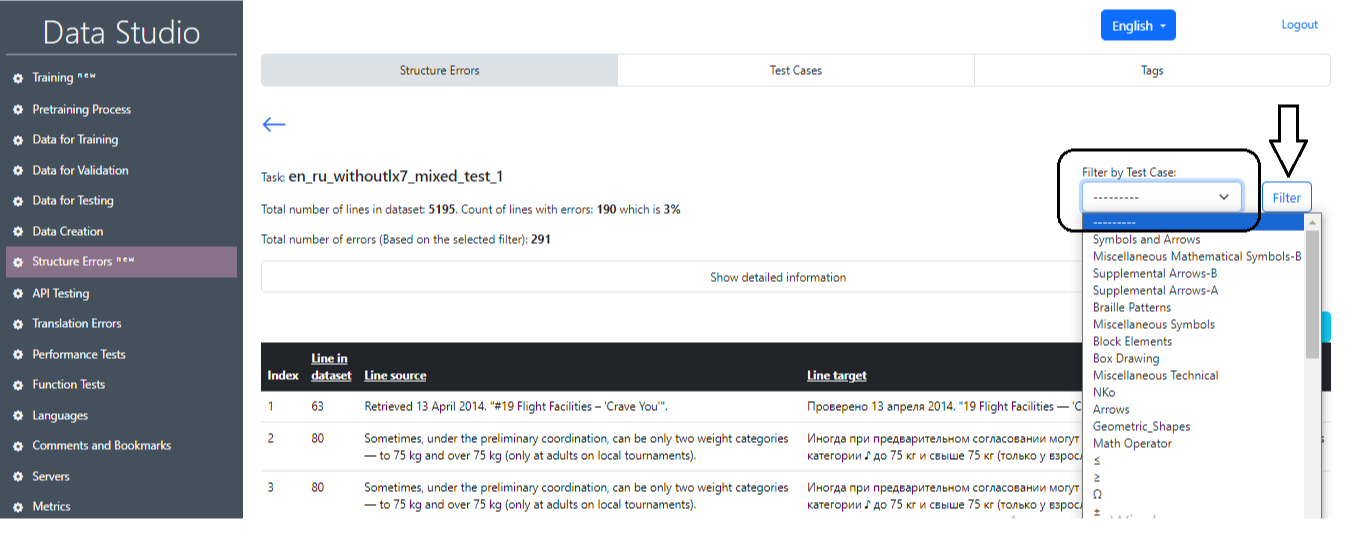
- Select task to compare: selection of a tasc with lx7 and without lx7 to compare the results of the two tests.
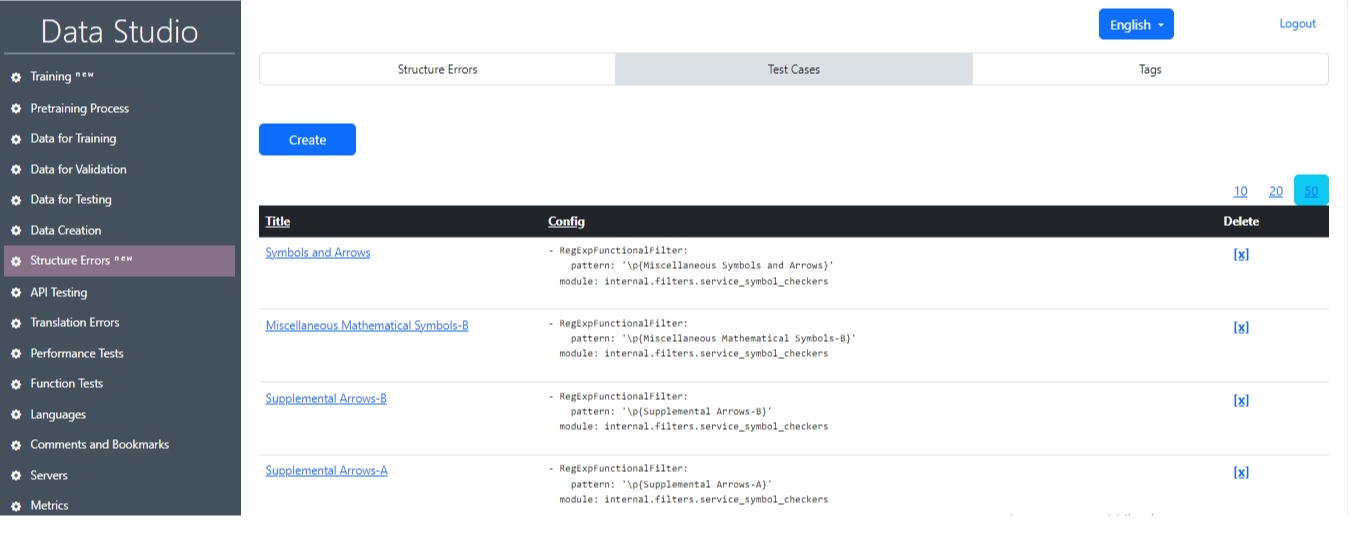
2) Test Cases (Image 19): This section displays test cases that are used to find errors. The operation of these test cases is based on regular expressions and filters.
3) Tags (Image 20): In this section the user can select a specific group of test cases. These test cases are grouped based on task categories, e.g., Symbols and Arrows, Miscellaneous, Math, etc. or language.
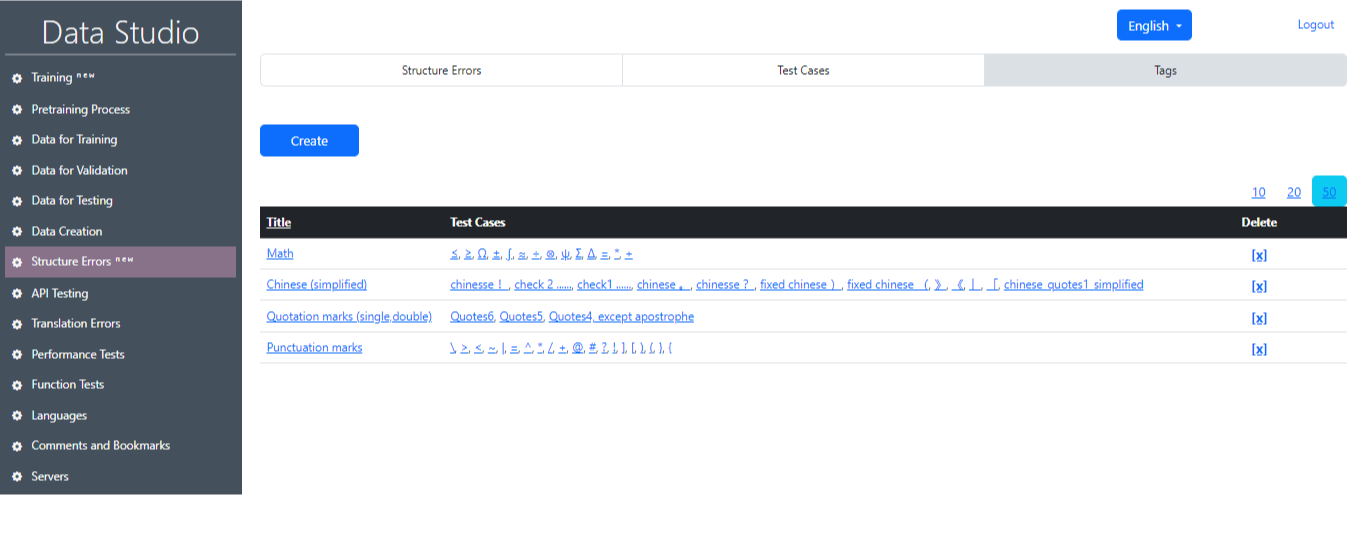
Image 21 shows a detailed view of a specific translation task in the Data Studio interface. Let's describe the key sections and the information presented:
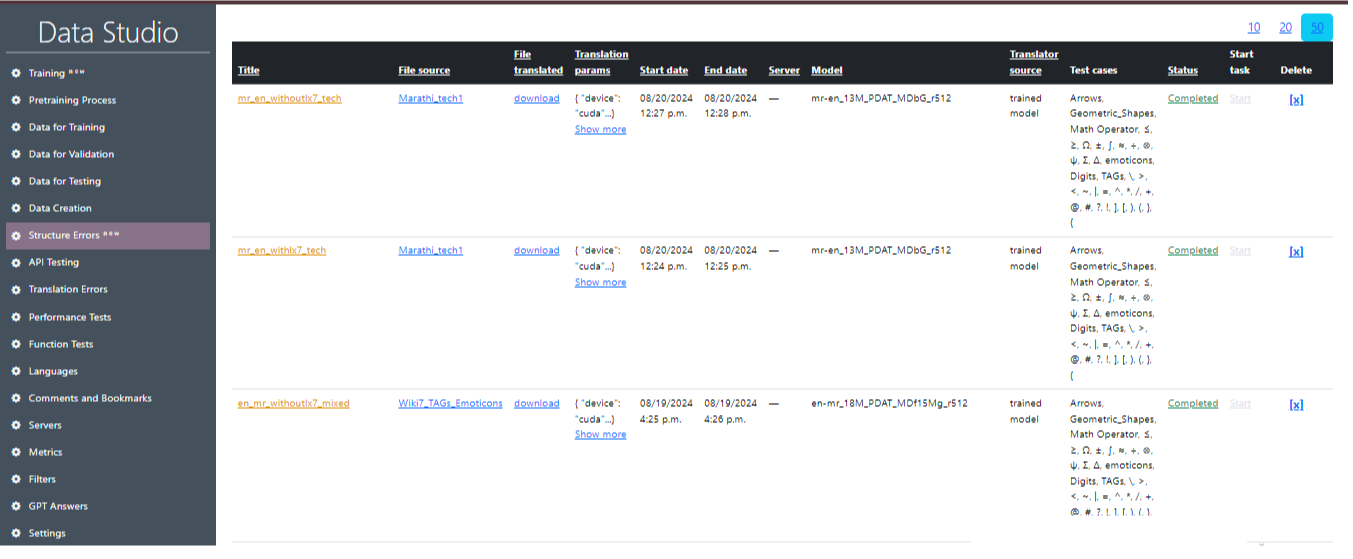
- Title: This displays the title or name of the translation task.
- File source: This displays the source of the file used for the translation.
- Translation Parameters: This section provides translation details including the device used (GUDA or CPU), translation with or without lx7, compute_type and beam_size.
- Start date: Presents information about the date and time the task was run.
- End date: Provides information about the date and time the task was completed.
- Server: Server in use.
- Model: Model in use.
- Translation source: Source of translation.
- Test Cases: Test cases used or a group of test cases.
- Status: This block displays all completed and ongoing tasks.
- Start Task: This column indicates the status of the translation task.
- Delete: Removing the task.
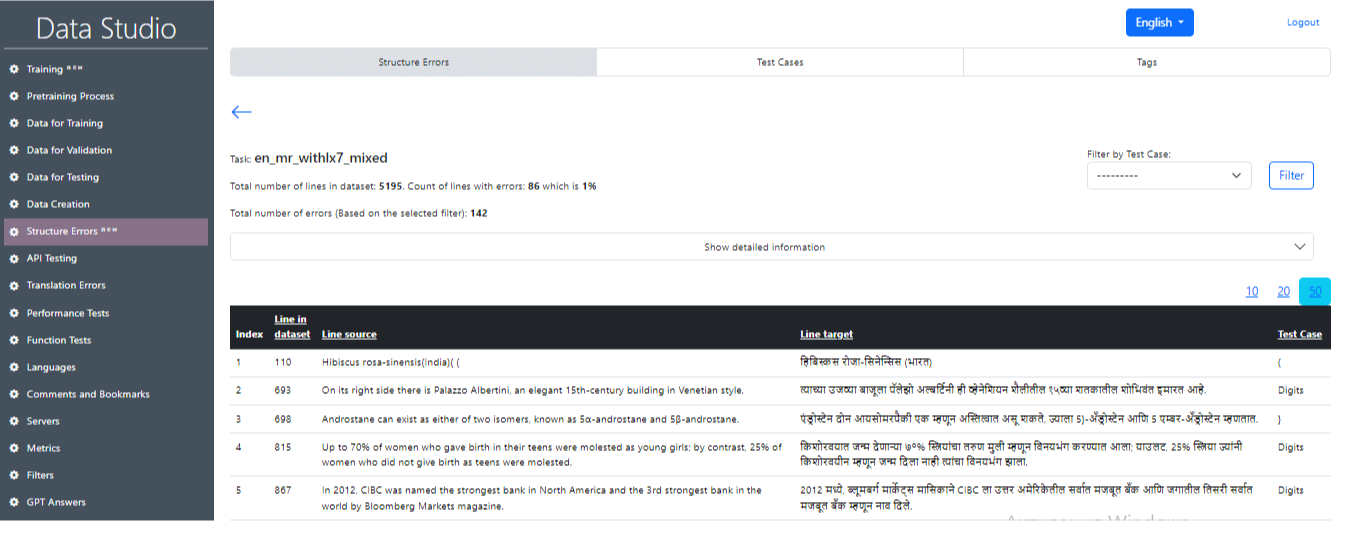
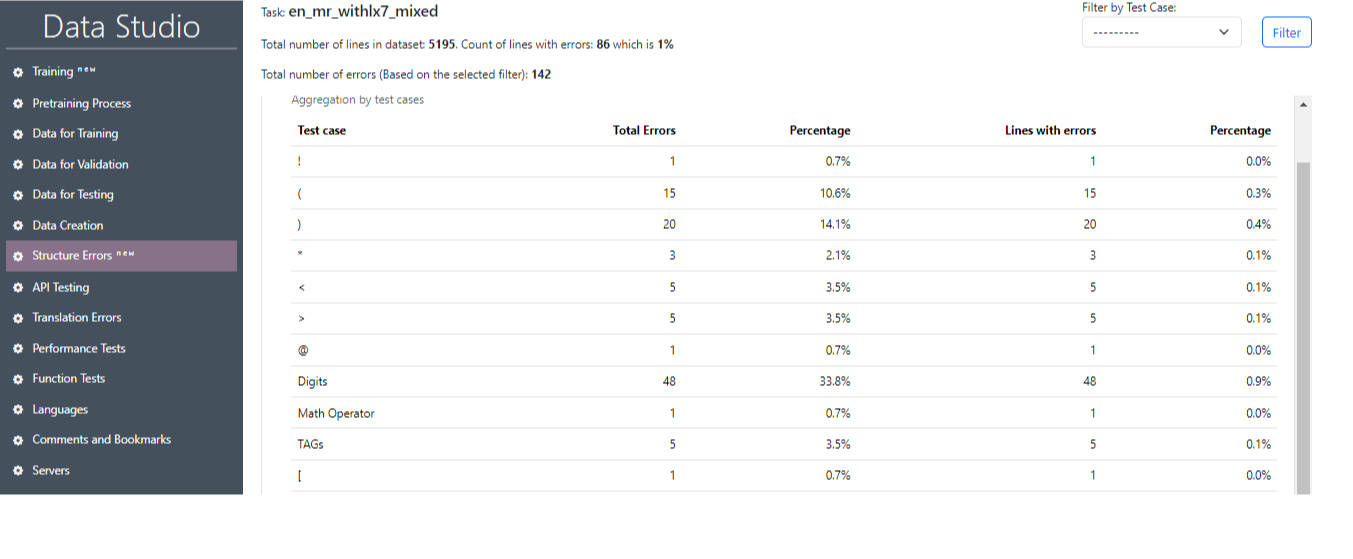
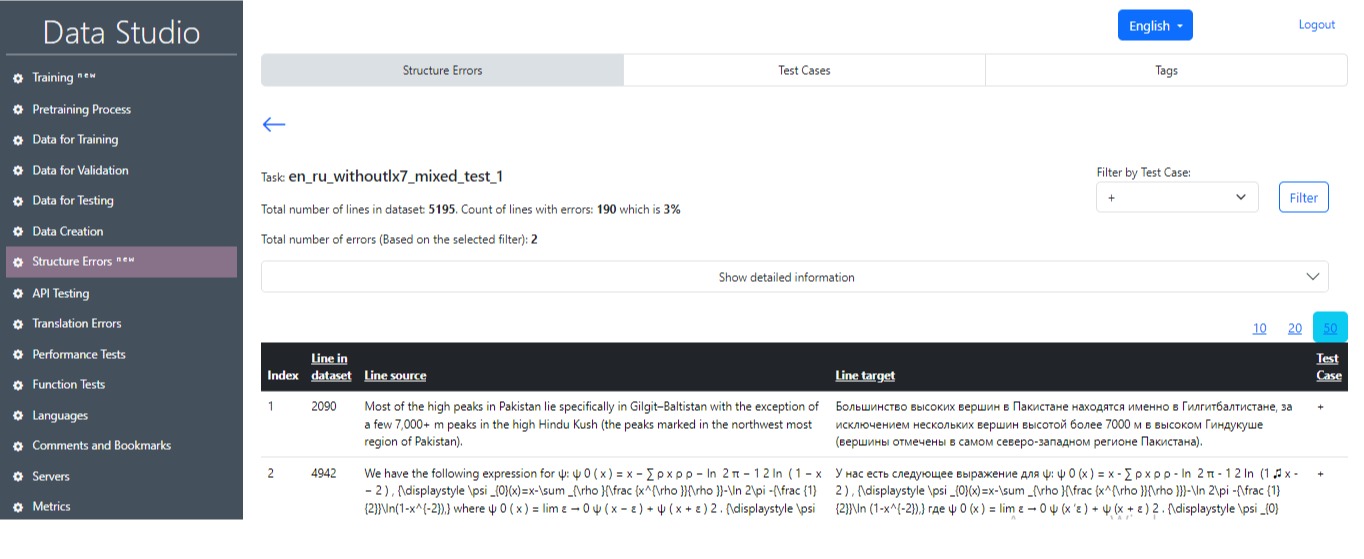
After successful completion of the task, it is possible to get the main information on the test results (Image 22), where the main statistics will be displayed (Image 23), as well as the numbers of sentences that contain an error and the related text-case. It is also possible to select an individual test case and sentences with that test case by clicking on the Filter button (Image 24, Image 25).
Conclusion
In this article, we explored the capabilities of Lingvanex Data Studio, a robust tool designed to improve the quality of machine translation. By processing massive amounts of data and applying systematic approaches to training, validation, and testing models, we are able to deliver exceptional translation results across a wide range of languages. We discussed the critical steps involved in developing effective language models, including data preparation, training, and rigorous testing methodologies. Integrating training, validation, and testing datasets ensures that our models not only learn efficiently, but also generalize well to new, unseen data.
Thanks to our ongoing research and the innovative tools at our disposal, we continue to refine our translation processes, improving accuracy and performance month after month.


