
في تقييم جودة الترجمة الآلية، من المهم ليس فقط مقارنة نتائج أنظمة الترجمة المختلفة، ولكن أيضًا التحقق مما إذا كانت الاختلافات الموجودة ذات دلالة إحصائية. وهذا يسمح لنا بتقييم ما إذا كانت النتائج التي تم الحصول عليها صالحة ويمكن تعميمها على بيانات أخرى.
في هذه المقالة، نقوم بمراجعة اثنين من المقاييس الأكثر شيوعًا لتقييم جودة الترجمة، BLEU وCOMET، ونحلل كيفية اختبار الأهمية الإحصائية للاختلافات بين نظامين للترجمة باستخدام هذه المقاييس.

الأهمية الإحصائية لـ BLEU وCOMET
يقوم مقياس BLEU (بديل التقييم ثنائي اللغة) بتقييم جودة الترجمة من خلال مقارنة n-grams في نص مترجم مع n-grams في ترجمة مرجعية (بشرية). وفقا للدراسة “نعم، نحن بحاجة إلى اختبار الأهمية الإحصائية”، من أجل المطالبة بتحسن ذو دلالة إحصائية في مقياس BLEU مقارنة بالعمل السابق، يجب أن يكون الفرق أكبر من 1.0 درجة BLEU. إذا اعتبرنا تحسنًا مهمًا للغاية في “كـ ” p-value “0.001<، فيجب أن يكون التحسين 2.0 نقطة BLEU أو أكبر.
مقياس آخر يستخدم على نطاق واسع، COMET (المقياس الأمثل عبر اللغات لتقييم الترجمة)، يستخدم نموذج التعلم الآلي لتقييم جودة الترجمة مقارنة بالترجمة المرجعية. وأظهرت الدراسة أن الفرق من 1 إلى 4 نقاط يمكن أن يكون غير مهم إحصائيا، أي ضمن هامش الخطأ. حتى الفرق بمقدار 4.0 درجات COMET يمكن أن يكون ضئيلًا.
هذه النتائج لها آثار عملية مهمة على مطوري أنظمة الترجمة الآلية. إن مجرد مقارنة المقاييس الرقمية يمكن أن يؤدي إلى استنتاجات مضللة حول التحسينات في جودة الترجمة. وبدلا من ذلك، ينبغي إجراء اختبارات إحصائية لتحديد ما إذا كانت الاختلافات المرصودة ذات معنى حقا.
اختيار مقياس لمقارنة أنظمة الترجمة
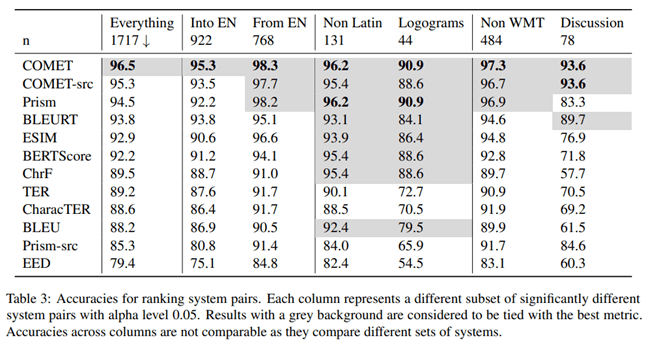
في المقالة “للشحن أو عدم الشحن: تقييم شامل للمقاييس التلقائية للترجمة الآلية”قام باحثون من Microsoft بالتحقيق في المقياس الخاص بتقييم جودة الترجمة الآلية الذي يرتبط بشكل أفضل بتقييم المترجمين المحترفين. وللقيام بذلك، أجروا التجربة التالية.
قام المترجمون المحترفون الذين يتقنون اللغة الهدف أولاً بترجمة النص يدويًا دون تحرير لاحق، ثم أكد مترجم مستقل جودة هذه الترجمات. رأى المترجمون السياق من الجمل الأخرى، لكنهم ترجموا الجمل بشكل منفصل.
وفقا لنتائج هذه الدراسة، أظهر مقياس COMET، الذي يقيم الترجمة على أساس متغير مرجعي، أعلى ارتباط ودقة بالمقارنة مع التقييمات التي أجراها المترجمون المحترفون.
قام مؤلفو المقال أيضًا بدراسة المقياس الذي يعطي أعلى دقة عند مقارنة جودة أنظمة الترجمة الآلية المختلفة. ووفقا للنتائج التي توصلوا إليها، فإن COMET هو المقياس الأكثر دقة لمقارنة أنظمة الترجمة مع بعضها البعض.
لاختبار الأهمية الإحصائية للاختلافات بين النتائج، استخدم المؤلفون النهج الموضح في المقالة “اختبارات الأهمية الإحصائية لتقييم الترجمة الآلية”.
من الواضح أن مقياس COMET هو الأداة الأكثر موثوقية لتقييم جودة الترجمة الآلية، سواء عند مقارنتها بالترجمة البشرية أو عند مقارنة أنظمة الترجمة المختلفة ببعضها البعض. الاستنتاج مهم لمطوري أنظمة الترجمة الآلية الذين يحتاجون إلى تقييم ومقارنة أداء نماذجهم بشكل موضوعي.
اختبار الأهمية الإحصائية
ومن المهم التأكد من أن الاختلافات الملحوظة بين أنظمة الترجمة ذات دلالة إحصائية، أي مع احتمال كبير أنها ليست نتيجة لعوامل عشوائية. ولهذا الغرض، يقترح فيليب كوهن استخدام طريقة التمهيد في كتابه المادة “اختبارات الأهمية الإحصائية لتقييم الترجمة الآلية ”.
طريقة إعادة أخذ العينات التمهيدية هي إجراء إحصائي يعتمد على أخذ العينات مع الاستبدال لتحديد الدقة (التحيز) لتقديرات العينة للتباين والمتوسط والانحراف المعياري وفترات الثقة والخصائص الهيكلية الأخرى للعينة. تخطيطيًا، يمكن تمثيل طريقة التمهيد على النحو التالي

خوارزمية لاختبار الأهمية الإحصائية:
1. يتم إنشاء عينة تمهيدية بنفس الحجم بشكل عشوائي من العينة الأصلية، حيث قد يتم التقاط بعض الملاحظات عدة مرات والبعض الآخر قد لا يتم التقاطها على الإطلاق.
2. لكل عينة تمهيدية، يتم حساب القيمة المتوسطة للقياس (على سبيل المثال، BLEU أو COMET).
3. يتم تكرار إجراء أخذ العينات التمهيدية وحساب المتوسطات عدة مرات (عشرات أو مئات أو آلاف).
4. ومن مجموعة المتوسطات التي تم الحصول عليها، يتم حساب المتوسط الإجمالي، والذي يعتبر متوسط العينة بأكملها.
5. يتم حساب الفرق بين القيم المتوسطة للأنظمة المقارنة.
6. يتم إنشاء فاصل الثقة للفرق بين المتوسطات.
7. تُستخدم المعايير الإحصائية لتقييم ما إذا كان فاصل الثقة لفرق المتوسطات ذا دلالة إحصائية.
تطبيق عملي
يتم تنفيذ النهج الموضح أعلاه لمقياس COMET في مكتبة Unbabel/COMET، والذي، بالإضافة إلى حساب مقياس COMET، يوفر أيضًا القدرة على اختبار الأهمية الإحصائية للنتائج التي تم الحصول عليها. يعد هذا النهج خطوة مهمة نحو تقييم أكثر موثوقية وصلاحية لأنظمة الترجمة الآلية. إن مجرد مقارنة المقاييس يمكن أن يكون مضللاً في كثير من الأحيان، خاصة عندما تكون الاختلافات صغيرة.
يعد تطبيق أساليب التحليل الإحصائي مثل bootstrap خطوة مهمة في التقييم الموضوعي ومقارنة أداء أنظمة الترجمة الآلية. يتيح ذلك للمطورين اتخاذ قرارات أكثر استنارة عند اختيار الأساليب والنماذج المثالية، ويوفر عرضًا أكثر موثوقية للنتائج للمستخدمين.
خاتمة
وبالتالي، عند مقارنة أنظمة الترجمة الآلية، من المهم استخدام الأساليب الإحصائية لفصل التحسينات ذات المغزى عن العوامل العشوائية. وهذا سيعطي تقييماً أكثر موضوعية للتقدم المحرز في تكنولوجيا الترجمة الآلية.



